
なぜ依存を注入するのか DIの原理・原則とパターンを読んだ

SNSでこの本を見かけ、ニッチな話題だと思ったのですが、DI周りについて整理できていないと思い読んでみました。結果としてはニッチではなく、ソフトウェア設計に関する本で、私としては良い整理が出来ました。
C#という事で、あまり慣れていないのですが、Javaは理解していたため、そんなに労せず読めました。ただUWP周りが初見だったので、じっくり読まないと分からず、そこだけ少し時間がかかりました。
DIというとDIコンテナのイメージが強かったんですが、章としては最後にあるだけで、基本的にはDIの目的、依存の種類、インターフェースの使い方、ソフトウェアアーキテクチャにおける、レイヤーとの関係性などの話で、DIについてその基本から整理し直すことができる形の構成になっています。
コードについては、以下で公開されているので、本書と合わせて読むと理解しやすいです。
というわけで読書メモとか感想とかを書いてみます。
DIの目的
DIは、ソフトウェアが達成したい目的を支援するためにあり、モジュールやレイヤー間を疎結合にするためのテクニックと定義しています。
疎結合になっていることのメリットとして、遅延バインディング、並列開発が出来るようになり、そして拡張容易性、保守容易性、テスト容易性などを高めることができ、その結果としてソフトウェアが達成したい目的を支援することができると言っています。
この辺りは、特に違和感は無く、継続的にアプリケーションを進化させていくためには、大事な要素ですね。
依存注入の3つの重要な特性
オブジェクト合成
オブジェクト合成とは、アプリケーションの構成を簡単に組み変えられるようにしておける特性と言っています。
依存を必要とするオブジェクトに、依存オブジェクトを生成して注入し、オブジェクトグラフを構成する、そしてアプリケーションが新たな要求に対応する必要が出た場合に、その依存をラップして追加したり、差し替えるだけで、新たな要求に対応できるようにすることが、オブジェクト合成だと言っています。
これはまさにDIをする主要な理由の一つだと感じました。
オブジェクトの生存期間
依存を注入するということは、依存の制御を諦めるということで、それはつまり利用する側のインスタンスは、依存オブジェクトがいつ生成され、破棄されるのかを制御する能力を失うということだと言っています。
例えば、2つのインスタンスに、1つの依存オブジェクトを注入したとして、片方のインスタンスで、その依存オブジェクトを破棄してしまうと、もう片方のインスタンスで、エラーになってしまう。そのため、利用する側のインスタンスでは、DIにより受けとったオブジェクトの生存期間を制御する能力がないと言っています。
これは、忘れられがちかもしれませんが、十分に理解し適切に管理する必要があるところだなと感じました。
インスタンスが、シングルトンだったり、リクエストの間だけ生きているなど、指定できるDIコンテナも多いと思います。パフォーマンスなど考えた場合に、シングルトンにしておきたい、その場合はインスタンス変数は持ったらまずいとか、その依存オブジェクトのライフサイクルがどうなっているのかは、しっかりと認識しておかないと、バグを生み出したり、不必要に生成してしまうなど発生するため、しっかりと認識しておくべきことですね。
介入(interception)
連携するオブジェクト間の呼び出しに介入して、振る舞いに追加の処理を加えたり、変えたりすることを、連携するオブジェクトに対して変更を加えることなく出来るようにすることと言っています。
また介入は、アスペクト指向プログラミングへと向かい、関心の分離を維持しながら、横断的関心事を適用出来るようになると言っています。
アスペクト指向については、SOLID原則の面でも論じられていて面白いところではあったので、時間をおいて再度読んでみたいなと思いました。
介入については、GoFのDecoratorパターンやProxyパターンをイメージすれば良いのと、本書ではDecoratorパターンは、たくさん出てきますので、あらためて使い所を認識できました。
依存の種類
安定依存と揮発性依存があり、揮発性依存は、DIで注入すべきと言っています。揮発性依存は、以下と言っています。
対象の依存を導入してアプリケーションを適切に動作させるためには、実行環境の設定や調整が必要になるもの
DBなど別のプロセスにあるもの
対象の依存となる具象クラスが用意されていない、もしくは開発中
対象に依存が開発に携わるすべての環境に用意されていない
高価なサードパーティ製のライブラリなど
対象の依存に非決定的な振る舞いが含まれている
日付とかランダム値とか、そういったもの
これらは確かにDIが必要なケースですね。このように言葉が定義されて、リストアップされるとより一層理解が進みますね。
制御の反転(Inversion of Control : IoC)
DIはIoCの一部でしかなく、IoC自体はもっと大きい範囲のもので、フレームワークや実行環境によって、プログラムの流れが制御されるプログラミングスタイルのことを意味していると言っています。
依存注入という名前が与えられる前は、制御反転コンテナ(Inversion of Control Container)と呼んでいたらしく、その後すぐに、依存に対する制御の反転という意味を持ち始めたとのこと。そしてマーチン・ファウラーによって「依存注入(Dependency Injection: DI)と名付けられて、そこから今日に至るようです。
レイヤーと依存の向きと合成容易性
ソフトウェアアーキテクチャでは、いくつかのレイヤーに分け、関心事を分離します。そして、各レイヤーを疎結合にすることで、差し替えをしやすくすることを目的としています。合成容易性とは、この差し替えの容易さのことだと言っています。
本書では、3層のレイヤードアーキテクチャを例に説明しています。
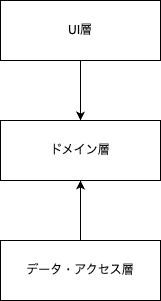
ドメイン層は、アプリケーションの根幹をなすため、ドメイン層の変更はアプリケーションの変更と同義です。そのため、各層の依存の向きをドメイン層に向け、インターフェースに依存させる設計にします。UI層やデータ・アクセス層が依存するインターフェースはドメイン層に配置することで、これらの層の差し替えが可能になると言っています。
例えば、UI層を通常のHTMLのレスポンスからAPIに変えることが出来るのか?を考えた場合に、UI層が他の層から依存されていなければ、他の層を変更することなく、差し替えることが可能なはずです。
次にデータ・アクセス層ですが、データの構造が変わらないなどの前提を置いた場合、RDBからドキュメントDBに変更することが可能になるはずです。
もちろん、実際の開発では、画面は変わりますし、適切なAPI設計を行うため、他の層を変更せずに入れ替えると言うのは現実的では無いと思いますが、適切に作られたドメイン層があれば、ある程度の変更は吸収しやすい状態になっているはずです。
合成基点(Composition Root)
合成基点は、オブジェクト合成を行う場所で、オブジェクトを入れ替えるだけで、アプリケーションの構築が出来る場所。そのため、アプリケーションのエントリーポイントに限りなく近い場所になると言っています。
エントリーポイントに限りなく近い場所とは、プログラミング言語のmain系の関数、メソッドがエントリーポイントになるため、プログラムの引数の確認などの後、メインとなる処理を実行する前の間になるようです。
DIコンテナを使っている場合でも、DIコンテナを使うのは合成基点のみにすべきと言っています。もし合成基点以外で使用してしまうと、後ほど出てくるサービス・ロケーターのアンチ・パターンになると言っています。
補足ですが、依存の向きについては、合成基点では、各レイヤーのオブジェクトを生成するため、各レイヤーへの依存関係が発生します。ただし、1カ所で管理しているため、依存関係の複雑さを制御可能は範囲に留めておくことができるようです。この1カ所で管理するという考え方もまた、サービス・ロケーターのアンチ・パターンと密接に関わってきます。
依存注入の方法
コンストラクタ経由での注入(Constructor Injection)
一番初めに検討すべき方法で、もっとも頻繁に遭遇するシナリオに対応でき、簡単に正しい適用が出来る方法だと言っています。
また、依存が必要ないパターンに関しては、Nullオブジェクトを渡すことで、nullチェックも不要になるため、ほとんどのケースに対応が出来ると言っています。
これについては、まさにDIといった感じで、真っ先に思い浮かべるものですね。
メソッド経由での注入(Method Injection)
依存の注入が合成基点で行うことが出来ないような、メソッドの呼び出し時に、動的に行う必要がある場合だと言っています。
本書では、リクエストに含まれるユーザー情報を例にして説明されています。フレームワークなどを使っているとコントローラーで受け取ったリクエストオブジェクトにユーザーの情報が含まれていたりします。ただし、それをドメイン層にそのまま持っていってしまうと、ドメイン層にUI層への依存が発生してしまいます。
また、ユーザーのロールによる何かしらの判定を、UI層で実施してその結果を渡すと言うことも考えられますが、それはビジネスロジックになるため、UI層で実施すべきことでは無くNGとなります。
この結果、ドメイン層にあるインタフェースに依存したUI層の実装クラスを、メソッド経由でDIする方法になると言っています。この辺りはソースを見ながら追わないとイメージが湧かないかなと思います。
ドメイン層のメソッドでは、ドメイン層に定義されたインターフェースに依存しているだけなので、この場合でも問題なくUI層の差し替えはできる状態になっています。
プロパティ経由での注入(Property Injection)
デメリットが多いため、基本的には使わないパターンだと言っています。
デフォルトの実装があるが、それを任意に差し替えるのは許しているような、依存を注入することが任意の場合には有効な手段になり得るそうです。基本的にはライブラリやフレームワークなどを利用する場合に有効な手段であり、アプリケーション側で利用することは控えるべきだと言っています。
依存注入のアンチ・パターン
コントロール・フリーク(Control Freak)
揮発性依存を注入ではなく、使用するクラス内で生成してしまうアンチ・パターンと言っています。これは一般的なクラスの使い方になりますが、揮発性依存は注入すべきなため、アンチ・パターンになると言うことです。
揮発性依存なのに、外部から注入が出来ないため、テストなどでモックに差し替えることも難しくなります。また、介入も出来なくなるため、Decoratorなどを使って、振る舞いを追加するということもできません。
また、Factoryパターンについても触れられていて、DIにおいて、このパターンを使ったとしても、それは別のクラスにその問題を移動して、コードを複雑にしただけで、意味がないことだと言っています。Factoryは、具象クラスの生成が複雑な場合などに、その複雑さを隠蔽するために利用するパターンだと言っています。
サービス・ロケータ(Service Locator)
合成基点の外で、アプリケーションを構成するオブジェクトに、揮発性依存の提供を無制限に行えるようにするアンチ・パターンで、サービス・ロケータの唯一の欠点は、クラスの再利用性に大きな影響を及ぼすことだと言っています。
サービス・ロケーターを利用するクラスは、サービス・ロケーターへの余分な依存を持つことになり、サービス・ロケーター無しでは動かないということになります。その欠点を覆すほどのメリットは、コンストラクタなどでのDIが出来る以上は無く、余分な依存関係を持ち込んでいると言っています。
また、サービス・ロケーターを利用するクラスが内部でどんな依存をもっているのかを外部から隠してしまうことになります。内部構造まで把握することで、初めて適切に使えるようになるため、内部を知らずに使うと実行時になって初めてエラーが発生するということになります。
テストについても、モックに差し替えることは可能ですが、各テストケースで、サービス・ロケーターをリセットしないといけないという、相互依存するテストになってしまうと言っています。テストケースでグローバルな状態を使っているようなものということですね。
アンビエント・コンテキスト(Ambient Context)
Staticなメソッドやプロパティなどを利用することで、合成基点の外で、揮発性依存へのグローバルなアクセスや振る舞いをアプリケーションコードに提供してしまうアンチ・パターンだと言っています。
サービス・ロケーターのアンチ・パターンと同じように、テスト時のグローバルな状態を利用しているため相互依存するテストになってしまうことや、依存を隠しているため、多くの依存が持ち込まれていても気付きにくく、単一責任の原則に違反しやすいと言っています。
また、主に横断的関心コ事を扱う場合に発生すると言っていて、かつ合成基点の外で行われいることなため、もし変更が入った場合は、各層での大量な変更が入ってしまうと言っています。
横断的関心事であるログですが、クラスのプロパティに、LogManager.getLogger(Main.class)みたいなものもアンビエント・コンテキストだと言っています。
これについては、定義上は確かにそうだなと思うのですが、別の章で提示しているDecoratorでの解決方法については、良い解決方法なのかもと思う一方で、ちょっと面倒だなと感じてしまいました。
制約に縛られた生成(Constrained Construction)
遅延バインディングを可能にするため、特定の抽象に対するすべての実装クラスが全く同じシグネチャのコンストラクタを持つことを強制するアンチ・パターンだと言っています。
そして、遅延バインディングを実現するために、構成ファイルなどで依存を設定するようにした場合に、発生するアンチ・パターンだと言っています。
例えば、データの保存先として、RDBを扱う実装クラスがあった場合に、そのコンストラクタには接続文字列を受け取るようになっているとします。
別の実装として、テスト用にクラス内のメモリでデータを簡易的に管理したい場合を考えると、接続文字列は不要です。ただし実装上は定義する必要があるという状態になってしまうということのようです。これは構成ファイルから読み込んでいるため、常に接続文字列が提供される必要があるということです。さすがに読み込みの処理の中で、この実装クラスなら、という分岐をするのは無理がありますね。
別のケースとしては、引数なしのコンストラクタについても書かれていますが、結論としては柔軟性を損ねてしまうと言っています。
DIコンテナ
最後の章でやっとDIコンテナが出てきます。
この章まででDIについてしっかりと説明しているため、DIコンテナが何を行いたいためのものなのかが分かっている状態になっています。その上でC#のDIコンテナの3つについて、使い方やオブジェクト合成、オブジェクトの生存期間、そして介入の方法などを説明しています。
そして、DIコンテナは、DIに必ず必要なものではなく、開発するソフトウェアとDIコンテナのメリット、デメリットを踏まえて、使用するか検討すべきものだと言っています。
まとめ
DIについて、改めて整理し理解を促進することができました。
実際の開発では、項目追加を伴う機能追加により各層に手が入ることが多く、テスト以外では、なかなかメリットを享受できず、その有用性を理解することができないという声も多いです。
私としては、基本となる考え方を改めて強化、獲得でき、実際のプロジェクトでどうするか、そしてどう説明するのか、引き出しが増えたなと感じていますので、読んで良かった一冊になりました。