
AIによる観光アプリ 第2回:観光地のおすすめ度を決める技術

前回に続いて、今回も人工知能による観光アプリ「鎌倉観光案内」の記事です。今回は、AIが観光地のおすすめ度を決める仕組みを紹介します。
前回の記事はこちらからどうぞ。
第1回:自作アプリ「鎌倉観光案内」の紹介
おすすめ度の決定
鎌倉観光案内のAIの目的は、観光コースを自動的に作成することです。そのためには、まず観光地それぞれのおすすめ度を評価する必要があります。
鎌倉観光案内アプリでは、収録されている67カ所の観光地を点数化し、「スコア」として扱います。
観光地を点数化しようなど、おこがましい話であることは十分承知していますが、AIで自動化するには数値ベースで表現しなければ始まらないのです。
鎌倉観光案内の場合、観光地のスコアは固定的な値ではなく、ユーザーが指定した興味の入力値4つ(「知名度」「歴史・遺構」「自然・季節感」「雨天用」の値)によって変化します。
下の図に例を示します。
ユーザーの興味を入力する画面では、4つあるシークバーで4つの入力値を指定できます。入力値は、それぞれ0~100の値を取ります。
たとえば一番上の「知名度」の入力値を0(名所に行きたい)にした場合と、100(穴場に行きたい)にした場合で、各観光地のスコアは図のように大きく変化します。
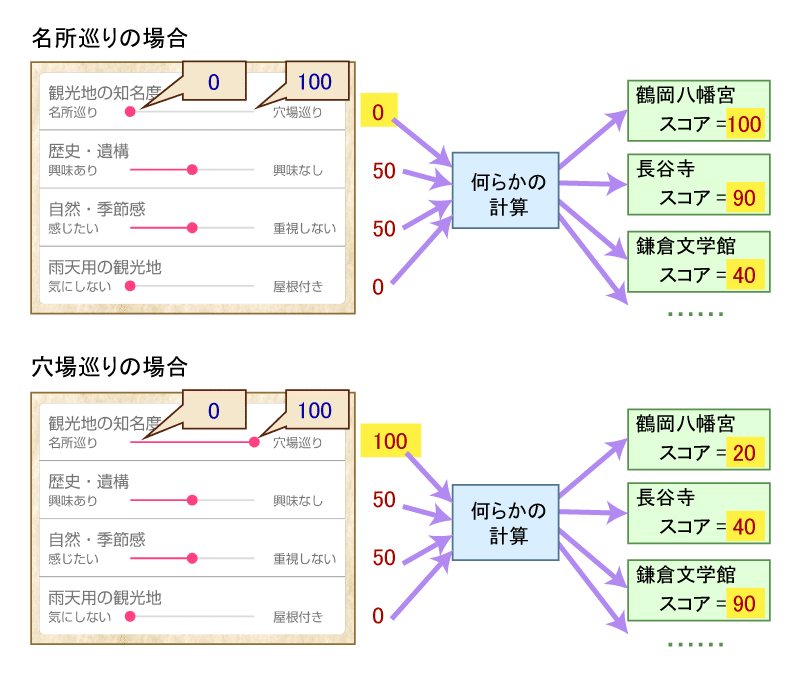
名所に行きたいとした場合、鶴岡八幡宮や長谷寺のような名所のスコアが高く、鎌倉文学館のような穴場のスコアが低く出ます。逆に穴場に行きたいとした場合、スコアの大小は逆転します。
また、「雨天用」の入力値を「屋根付き」側に移動させると、博物館やショップを含む観光地のスコアが上昇するなど、異なる結果になります。
アプリ上では各観光地のおすすめ度を星5つで表示していますが、これはスコアの値を直感的に理解できるように表現し直したものです。観光地をスコアの高い順に並べ替え、上から順に5つ星、4つ星…1つ星を割り当てます。
星の数による表現は相対評価であるため、計算過程でスコアの絶対値の大きさを気にする必要がありません。
スコアの計算方法
ここで、上の図の「何らかの計算」をどう実現するかが問題になります。
鎌倉観光案内では、4つの入力値から観光地のスコアを求める際、入力値ごとの「査定値」を求め、求めた4つの査定値の合計をその観光地のスコアとしています。
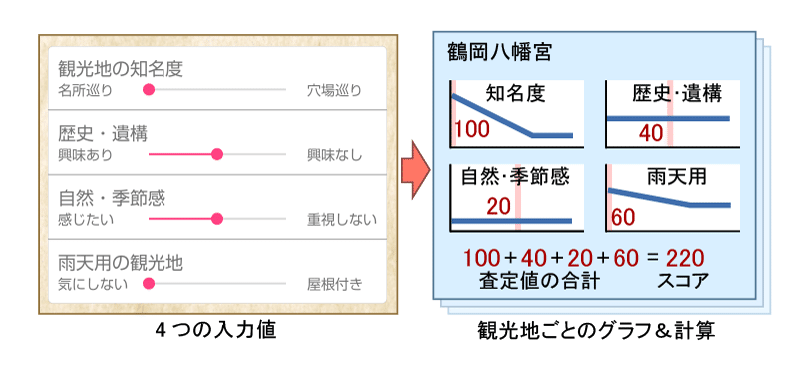
アプリでは、入力値4つからどのような査定値を返すべきか、観光地ごとにグラフの形でデータ化しています。もちろん観光地が違うとグラフの形も違います。
興味の入力値4つが与えられると、グラフから査定値4つを計算し、その合計を求めて観光地のスコアとします(実際には天気の支配力を大きくするため、一部で式の調整も行っていますが……)。
この計算を観光地の数だけ繰り返せば、各観光地のスコアが定まります。
ここで、入力値の1つ、「知名度」の計算を例に挙げます。
例えば、名所「鶴岡八幡宮」と穴場「鎌倉文学館」では、それぞれ「知名度」のグラフを次のように用意しています。
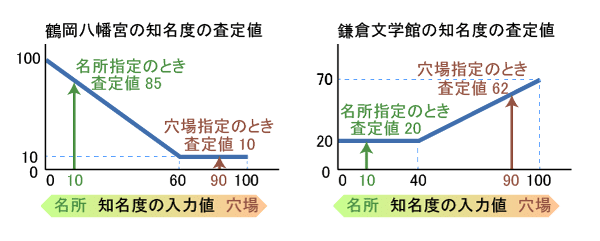
名所に行きたい人が「知名度」を10(名所を希望)と入力すると、名所の鶴岡八幡宮では大きな査定値を、穴場の鎌倉文学館では小さな査定値を返します。逆に「知名度」を90(穴場を希望)と入力すると、穴場の鎌倉文学館のほうが大きな査定値を返します。
グラフから査定値を計算する際は、小学校の算数で習った比の計算ができれば十分です(もちろん1次関数でもよいのですが、私は最適化や予測処理の大半を算数の比で処理している気がする)。ディープラーニングの内部計算のように、偏微分などの高等数学は不要です。
AIにおける「知識」
スコアの計算に使用した観光地ごとのグラフは、どのような旅行者にどの観光地を勧めればよいかという、観光地の「知識」に相当します。
私は様々なWebの観光情報や、実際に観光地を見た印象から、観光地67カ所×入力値4つ分、合計268パターンのグラフを手作業でデータ化しました。
以下は実際のデータです。プログラム中に書かれているこれらの数字の列(グラフの上限、下限、形など)が、「鎌倉観光案内」の観光地に関する「知識」といえます。

私は、追加更新がない完全な固定値を、わざわざリソースデータにして読み込むようなプログラムを書きません。原則に反するコーディング方法なので、よい子のエンジニアの皆さんは真似しないように!
機械学習!?
最近では、こうした知識を機械学習によって自動的に取得するのが流行しています。今回なら、興味の値と、実際に行った観光地のペアを実績データとして、その関係を学習する……という感じです。
ディープラーニングに代表される機械学習が有益であることには異論ありませんが、今回のようなケースで使うのは現実的ではなさそうです。
まず、マイナーな観光地の訪問実績まで含め、学習用の大量のデータを事前に用意するのはかなり困難です。また、「冷やかし」の結果で生じたノイズデータを取り除く技術も必要です。
とは言っても、私の大学院での研究テーマはまさにこの「知識の学習」でした。当時はディープラーニングの技術はなかったので、MDLを使ってif-thenルールの観光知識を学習する仕組みで修士論文を書きました。
システムの利用に伴って知識を自動的に修正することができる一方、知識をゼロの状態から作り出すことには課題があるという整理だったと記憶しています。
鎌倉観光案内では、私の主観に基づいて「知識」をパラメータの形で埋め込みました。客観性は全くありませんが、マイナーな観光地まで含めて、納得できるまでパラメータを微調整できたという良さもります。
最近のAI関連のサービスは流行の技術を使うこと自体が目的になりがちです。しかし、対象となる領域(今回は観光)に興味を持って、完成度向上に向けた情熱を注ぐことこそ最も重要だと私は考えます。
理想が先にあって、それを実現するためにベストな技術を選ぶという順番は、技術者として忘れてはならないと思っています。