【テキスト×GPS】あなたが昨日見逃した”美味しいお店”をリストアップするプログラムを作った!

お疲れ様です。東京で仕事をしているものです。へちやぼらけと申します。(統計学・機械学習に関する動画も投稿している、所謂YouTuberです。笑)
ポケモンGO・ドラクエウォークのブームなどを目の当たりにしてると、「GPSを使った地理情報連動型アプリって、今後流行るんじゃね?」と密かに思ってます。また、Zenlyっていう「友達と位置情報を共有するSNSアプリ」もあったりするんですよね。
と、言うことで今回はテキストマイニング×GPS(地理データ)です。GPS情報から昨日あなたが歩いた場所を取得して、あなたが見逃した”美味しいお店”をリストアップするプログラムを作ります。
リストアップの際は、口コミの情報をネガポジ分析し、より良い口コミが含まれているお店を見つけます!
ちなみに、位置情報からお店を取得する際は”ぐるなびAPI”を利用させていただきました。
〇アルゴリズム概要
ざっくりとアルゴリズムの概要ですが、とってもシンプル。以下の5つのステップで”美味しいお店”をリストアップします。
⓪スマホのGPSをON!位置情報をGoogleのサーバーに送る。
①自分の位置情報を取得!
②取得した位置情報をPythonに読み込ませる。
③リスト形式で格納した位置データを”ぐるなびAPI”に投げる。
④投げたあとに返ってくる「周辺のお店情報」「そのお店の評価」「口コミ」をリストに格納する。
⑤取得したお店の中で評価4.5以上のお店をピックアップ。更に、ピックアップしたお店の口コミをネガポジ分析!良い口コミを持つお店をリストアップ。
こんな感じです。以下ステップごとに確認をしていきましょう!
⓪スマホのGPSをON!位置情報を送る。
アンドロイド端末の場合「Googleアカウントがログインした状態」「ロケーション履歴がオン」「デバイスの現在地送信機能がオン」の3つの状態を満たす場合に限り、あなたの位置情報が保存されるようです。
①自分の位置情報を取得
保存した位置情報はグーグルマップから取得可能だ。取得方法は、個人のプライバシーに関わるため詳細には触れない。自分で調べて自分の責任下で実施して下さい。
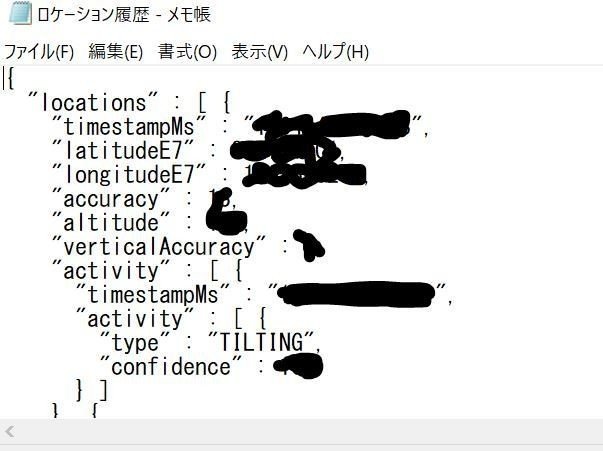
ちなみに、自分はGoolgemapsのページからロケーション履歴を取得しています。取得したロケーション履歴は↓。緯度・経度及び、その時の自国がjson形式で保存されているぞ。
②位置情報をPythonに読み込ませる
取得した”ロケーション履歴.json”をPythonに読み込ませます!と言っても、単純にjsonファイルを読み込むだけです。
jsonのlocationに位置情報があるので、それを変数locationsに格納します。
with open("ロケーション履歴.json") as file:
data = json.load(file)
# locationsから履歴情報を取得
locations = data["locations"]
locationsには、あなたが通った場所が緯度・経度として保存されています。さて、locaionsの緯度・経度を取得してマップ上に表示してみよう!コードは↓。
# locationsの情報をitemに代入
for item in locations:
# itemから緯度経度を取得!
timestamp = datetime.fromtimestamp(int(item["timestampMs"]) / 1000)
lat = convert_lat_lng(item["latitudeE7"])
lng = convert_lat_lng(item["longitudeE7"])
accuracy = item["accuracy"]
・
・
・
map.fit_bounds(positions)
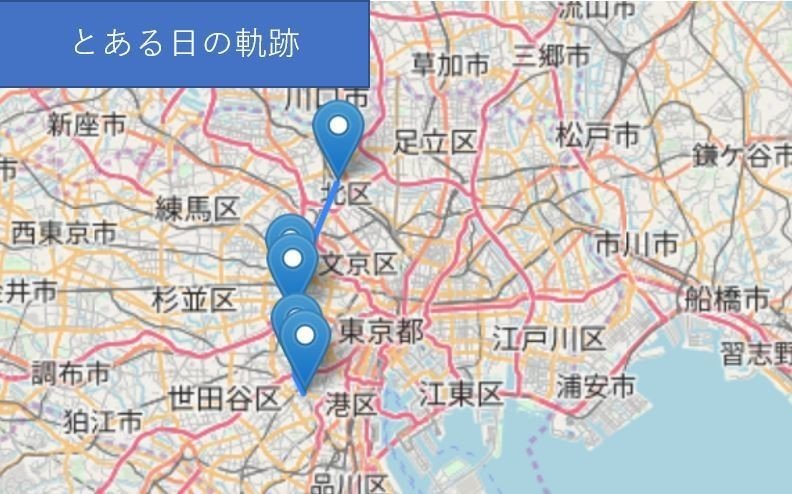
map表示したマップはこんな感じ↓。俺が東京をふらふらしたとある1日です。
③位置データを”ぐるなびAPI”に投げる。
ぐるなびAPIに先ほどの緯度・経度をぶん投げます。投げると、「その周辺のお店の情報」「お店の評価」「お店の口コミ」が返ってくるので、変数shop_dicに格納します。
Url = "https://api.gnavi.co.jp/PhotoSearchAPI/v3/"
shop_dic = pd.DataFrame()
#パラメタ
for tate, yoko in positions:
params={}
params["keyid"] = "?????????????????????" #取得したアクセスキー
params["latitude"] = float(tate)
params["longitude"] = float(yoko)
params["range"] = 3 #1:300m、2:500m、3:1000m、4:2000m、5:3000m
params["hit_per_page"] =50
#リクエスト結果
shop_dic = shop_dic.append(requests.get(Url, params).json(),ignore_index=True)
time.sleep(1)④返ってきた値の整形
ぐるなびAPIから受け取った情報はjsonファイルで返ってきます。情報量が多く扱いにくい。なので、shop_dicから「お店id」「店名」「評価」「口コミ」のみを抽出して、それを変数shopsに格納します。
ちなみに、この処理は例外処理が多く、思ったよりごちゃごちゃになってしまった・・。コードは肝となる部分だけ載せます。↓です。
if (get[str(i)]["photo"]["shop_name"] != get[str(i+1)]["photo"]["shop_name"]):
try:
rank = float(get[str(i)]["photo"]["total_score"])
except KeyError as e:
rank = 3.0
temp_s = pd.DataFrame([[get[str(i)]["photo"]["shop_id"],
get[str(i)]["photo"]["shop_name"],
(temp_rank + rank)/times,
temp_kome + get[str(i)]["photo"]["comment"] + "。"]])
shops = shops.append(temp_s)
⑤いいお店をピックアップ!
はい、ということで、shopsの中からいいお店だけをピックアップします。ここら辺、センスの別れるところだと思いますが、私はまず「評価が4.3以下のお店」を全部捨てることにしました。
#平均評価が、4.3点以下は捨てる。
shops_sel = shops_sel[shops_sel[2]>4.3]次はその中から、より良いお店を”口コミ”から決めます。
下のコードは、実際に口コミをネガポジ分析している部分。辞書は有志の方が作られた「nega_poji.dic」を使います!(http://www.lr.pi.titech.ac.jp/~takamura/pndic_en.html)
# pn_ja.dicファイルから、単語をキー、極性値を値とする辞書を得る
def load_pn_dict():
dic = {}
with codecs.open('nega_poji.dic', 'r', 'UTF-8') as f:
lines = f.readlines()
for line in lines:
# 各行は"良い:よい:形容詞:0.999995"
columns = line.split(':')
dic[columns[0]] = float(columns[3])
return dicfor i,texts in enumerate(shops_sel.iloc[:][3]):
# CorpusElementのリスト
naive_corpus = []
naive_tokenizer = Tokenizer()
tokens = naive_tokenizer.tokenize(texts)
element = CorpusElement(texts, tokens)
naive_corpus.append(element)
# 感情極性対応表のロード
pn_dic = load_pn_dict()
# 各文章の極性値リストを得る
for element in naive_corpus:
element.pn_scores = get_pn_scores(element.tokens, pn_dic)
print(sum(element.pn_scores))
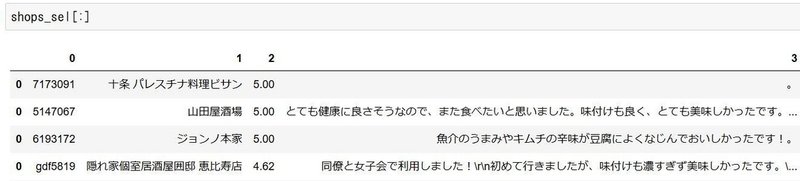
shops_sel.iloc[i,4] = sum(element.pn_scores)出力結果は以下の様な感じ。評価が4.3以上でかつ、口コミの良かったお店がリストアップされます!新しく追加した5列目(4の列目)がネガポジの結果です。

この記事が気に入ったらサポートをしてみませんか?