
深津貴之さんが解説、AI モデルを使い分けて使いこなす

*本 note は、Google が深津貴之さんにインタビューした内容を編集して掲載しています。深津さんには、Gemini の改善や活用のための知見をいただくため、アドバイザーに就任いただいています。また、Gemini を含む生成 AI の利用に関する説明は例示を目的としています。実際の回答結果については、ご自身で正確性をご確認いただくようお願いいたします。
こんにちは。Google の AI「Gemini(ジェミニ)」の公式 note 編集部です。
今回は、Gemini のアドバイザーで、Gemini を初期から使っているユーザーでもある深津貴之さんのインタビューをお届けします。
深津さんは 2023 年初頭、プロンプトを構造化して生成 AI からの出力精度を高める「深津式プロンプト」を公開しました。当時画期的だったこのテクニックは生成 AI の広がりとともに多くの人に使われたのです。そして現在、進化を続ける生成 AI について、「コンテキスト量(入出力データ量)」「レスポンスの速さ」「マルチモーダル」に注目しているという深津さん。
そんな深津さんに今回は、Gemini について、その軽量モデルである Gemini Flash やマルチモーダルについて、Gemini の今後などお聞きしました。
シャーロック・ホームズ全集から探偵の人格を Gemini で再現する
-Gemini の特徴のひとつは最上位モデルの Gemini 1.5 Pro にアクセスできる Gemini Advanced で 100 万トークンあるというロング コンテキスト ウィンドウです。深津さんも「コンテキスト量」に注目しているということで前回はその活用法などお話いただきました。つづいて、レスポンスの速さの影響についてお聞きしたいのですが、どのような変化をもたらすものなのでしょうか?
深津貴之さん(以下深津):入力したプロンプトに対するレスポンスが速いということは、リアルタイムに使いやすいっていうことです。

前回、長時間の動画、音声、ボリュームのあるコードもごっそり入力して処理できることで、以前よりも長い文章を、一貫性のある内容で生成するという例として、プロンプト エンジニアリング入門の内容をシャーロック・ホームズとジョン・ワトソンの対談形式で教えてもらう方法を紹介しました。
その際には、Gemini のロング コンテキスト ウィンドウを活用して、シャーロック・ホームズの小説を読み込ませて 2 人の性格や口調がよく表れた会話データを元に、Gemini にまねしてもらうという話でした。
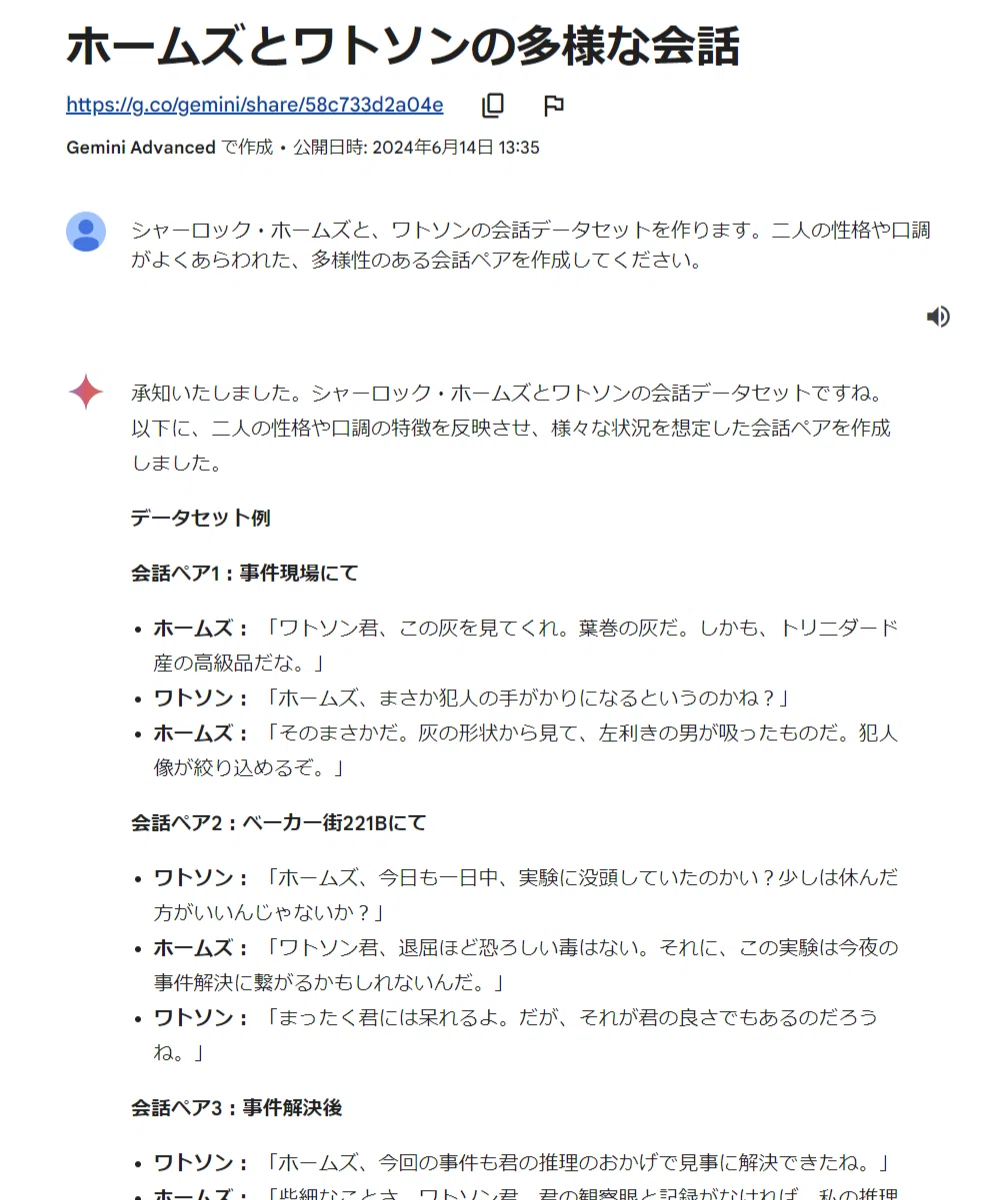
これにレスポンスの速さが加わると、ホームズの考え方や立ち居振る舞い、喋り方などを列挙させ、その内容をもって、僕との会話もできるんじゃないかと考えています。いわば Gemini でホームズを作るような実験です。
-どのような違いが出るのですか?
深津:ホームズの会話と人格をデータセットにするプロンプトは、対談形式で出力させるのとあまり変わりません。でも、ホームズとワトソンの対談を読んで理解するのではなく、ホームズと自分が会話してアドバイスがほしいのだとしたら、リアルタイム性がほしい。レスポンスが速いほうが UX は良いですよね。
僕の実験では、あくまで小説内のホームズとして話しているので頓珍漢な会話になることもありましたが、それもご愛敬。そしてレスポンスの速さという点では、可能性を感じています。
さらに将来、Gemini で音声の会話ができるようになったら、ホームズのような口調で喋らせてみたいですね。
Gemini 1.5 Flash を使って広がる可能性
-速度でいうと、高速かつ効率的に対応できるように設計されたモデル、Gemini 1.5 Flash があります。ついに、コンシューマ向けの Gemini (gemini.google.com) にも Gemini 1.5 Flash が対応しましたが、実際に深津さんがこの Gemini Flash を使ってみて、注目している使い方はありますか?
深津:僕は一次処理に使うと面白そうだなと考えています。
これは僕の期待というか、流れ的にこうなっていくだろうという話なんですが、たとえばある課題があったとします。それを全部いきなり Gemini Pro で実行するのではなくて、まず Gemini Flash に一次処理させる。具体的には、「A: 軽量モデルでぱっと答えて大丈夫な課題」もしくは「B: より上位のモデルでじっくり考えたほうがいい課題」のどちらか?と質問するんです。
その後に、「A」と返ってきたら、そのまま Gemini Flash で続けさせて、「B」と返ってきたら Gemini Pro での処理に移行します。
-Gemini Flash に判断させて、課題をふるい分けするのですね?

深津:そうです。これは、実は行動経済学で考えられている、人の脳の使い方と一緒です。僕たちの日常生活はさまざまな判断や選択で溢れています。例えば、何を食べるか、何を着るか、といった比較的些細なことも、仕事やお金に関する重要な決断も、混在しています。そこで脳が最初にすることは、じっくり考える必要があるかどうかの判断だと言われています。
人間の思考がこうした 2 つの段階(システム)によって行われるという概念があるんです。
ここで言う「システム 1」は、直感や感情に基づいて判断を下す思考システムです。無意識のうちに処理されるので、少ない労力で判断することができます。「システム 2」は、複雑な問題や新しい情報を処理するのに適していますが、エネルギーを多く消費してしまい、長時間持続することはできません。
言い換えると、脳には、効率的で高速処理ができる「システム 1」と熟考するので処理が遅い「システム 2」があるというわけです。まさに、 Gemini Flash と Gemini Pro みたいじゃないですか?
軽量の AI モデルは廉価版とか賢くないとか考えるのではなく、使い方次第。Google のスマートフォンでも Gemini Nano が使える機種がありますよね。Google アシスタントの代わりに動作したり、ネットに接続していない状態でも、録音の文字起こしや要約ができたりします。将来はさらに一歩進み、スマートフォンのようなローカル端末に高速動作する AI モデルを搭載して、そのままローカルで答えられる問題か、サーバーに送らなければいけない問題かを切り分けるようになると期待しています。
サイズの異なる AI モデルを連携させるのが鍵
-行動経済学と生成 AI、興味深いですね。私たちの脳はマルチモーダル モデルでもあります。その点で Gemini がさらに進化したら、今後どんなことが実現すると予想されていますか?
深津:マルチモーダルの大きな流れでいうと、エージェント化に注目しています。これも複数の AI モデルが連携して、複雑なタスクを実行することが鍵になってくると思います。
ロボットが複雑な意思決定や受け答えをするときには Gemini Pro といった高性能な AI モデルを使うことになると思います。それと同時に、Gemini Flash のような軽量 AI モデルを使えば、5 秒ごとに今目の前で起きていることをサマリーさせることも可能です。これは、ロボットに短期記憶が作れることにつながります。ロボットが自ら状況判断をしながら、話す / 動くが可能になるんじゃないでしょうか。
僕個人は、「大きい AI モデル 」1 つですごい答えを出すより、「小さい AI モデル」を 3 つくらい並行して使って、別々にメモを取ってもらったり、ToDo リストを処理したり、壁打ち相手としてツッコミを入れさせたり…といったことができると面白くなりそうだと感じています。小さい AI モデルが ToDo リストを見ながら、必要に応じて大きい AI モデルに処理を指示していく。逆に、大きい AI モデルが複雑な行動指針のようなものを生成して、その指針に沿って、小さい AI モデルがどんどん実行していくのもありです。
どちらが処理の司令塔になるかは設計次第だと思います。サイズの異なる AI モデルがお互いを補完し合うような設計がすてきなんじゃないかなと思っています。
-深津さん、ありがとうございました。AI モデルがお互いを補完し合う展望はとてもワクワクします!
深津さんのお話にもあったように、AI が使われる状況はひとつではありません。Gemini はそうした状況に対応するために特徴の異なる 4 つのモデルを用意しています。いろいろ試していただきたいのですが、まずは、パソコンやスマートフォン、タブレットから Google アカウントでログインすれば、すぐに利用できる Gemini(gemini.google.com)からぜひ!
連載 深津貴之さんインタビュー