
Circuit Xのリプレイス開発での技術選定&AppSyncなどバックエンド側の環境構築編

フクロウラボCTO若杉と申します!
前回、弊社のASP事業の管理画面のリプレイスにおいてフロントエンドの方の技術スタックについてご紹介いたしましたが、今回はバックエンド側についてご紹介したいと思います!
リプレイスを行うまでの背景について
まず、今回対象のCircuitX(ASP)の管理画面についての今までの役割や背景について話したいと思います。
CircuitXについては、前回の記事で説明があるので省かせていただきます。
CircuitXの管理画面リポジトリの最初のプルリクを見ると2015年まで遡ります。Railsの初期設定の構築が最初のプルリクでした。
当時、弊社顧客の単体のプロモーション企画で作ったアフィリエイトの仕組みを他のジャンルの顧客向けに活用できないかということを考えていて、単発の企画のために作ったシステムをそのまま案件毎に流用するというところから始まっています。最初からASP事業をやろうと考えていたわけではなく、あと半年持つかどうかのスタートアップ企業がとにかく稼ぎ食いつなぐために、日銭を稼ぐ手段としてやっていたことが、後に主軸事業になっていったという流れです。
当時は、他のプロダクトの方に可能性を感じていたので、後の主軸事業となるCircuitXは、単発で作った企画モノのシステムを効率的に他の案件でも横展開できるようにするために開発を進めていました。そういった背景により、長期的にこのシステムを使っていくという考えがなく、"必要な最小限の機能のみを最速で実装する"ということのみを考えていたフェーズでした。テストも最低限のもののみで、2016〜2017年は、ビジネスサイドからの要件をひたすら実装していくという、増築に増築を重ねる付け焼き刃なシステムが構築されていったと思います。開発自体を今振り返って見ると、「ひどかったな〜」と思いつつも、会社の事業としてはそれが正解だったのだと思います。むしろそういう開発をできていなければ、会社としても生き残っていなかったのではないかとも思います。
事業のピボット
2017年の後半くらいにやっとASP事業に注力して行こうと判断できたタイミングだったと思います。実はそのタイミングで、システムではなく組織面でエンジニアチームが一度ほぼ崩壊するような場面もありましたが、それはまた別の話でご紹介できればと思います。事業の主軸をピボットしたタイミングで人が抜けていくのはスタートアップあるあるだとは思います。
2018年は、今まで使い捨てと考えていたシステムで収益を上げていかなければならない現実を受け入れる年になりました。そのためには、エンジニア組織を立て直し、CircuitXを長期的に安定運用できるようにする必要がありました。このタイミングでリプレイスをするという選択肢もあったとは思いますが、その頃はまだビジネスサイドから要件が多く上がってきている状況で、かつ、チーム崩壊後なのでエンジニアリソースも圧倒的に少ない状態でとてもリプレイスをできるような状況ではなかったと思います。
データ分析基盤のリプレイス
幸いにも2017〜2018年のエンジニア採用で、優秀な方々に恵まれ、Rails部分でのテストのカバーリングやリファクタリングが進むようになりました。
一方、CircuitX(広告)事業が順調に成長したことにより、開発当初の想定していたよりも爆発的にトラフィックや取り扱うデータ量が増えました。
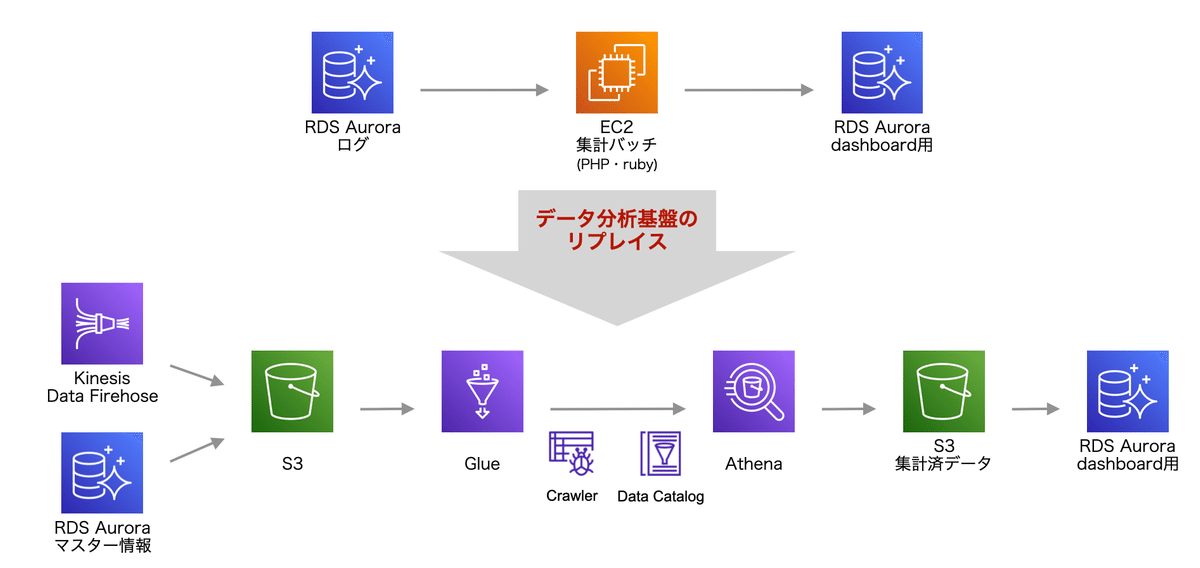
そのことでまず限界を迎えたのがデータの集計の部分でした。それまではMySQLに格納したログデータをPHPやrubyでバッチ処理を走らせ、dailyやhourlyでの集計結果をMySQLに格納するというやり方でしたが、一旦、集計に必要なデータは、kinesis、Glue経由でS3に格納し、Athenaで分析/集計できるようにしました。それが2019年から、データの収集、集計の部分に関わるいくつかのシステムを言語はGoを採用し、インフラリソースもECS FargateやLambdaへ移行し、サーバレスへとリプレイスが始まり2020年中に完了しました。このあたりの詳細については省きますが、別の機会でお話できればと思います。
そこから、ようやく管理画面のRailsのリプレイスを行うというのが、今回、お話しようと思っている部分です。
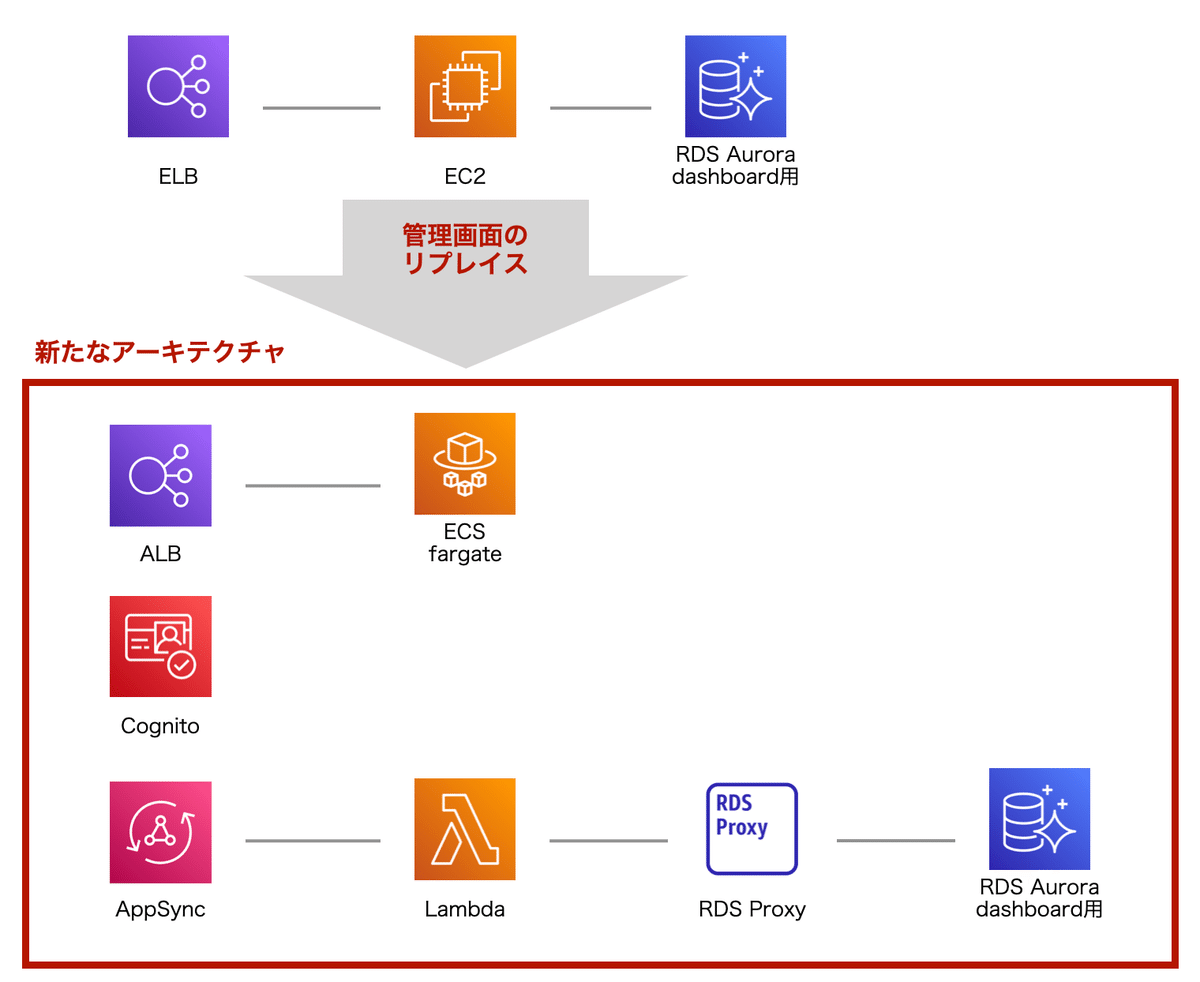
バックエンド全体の構成
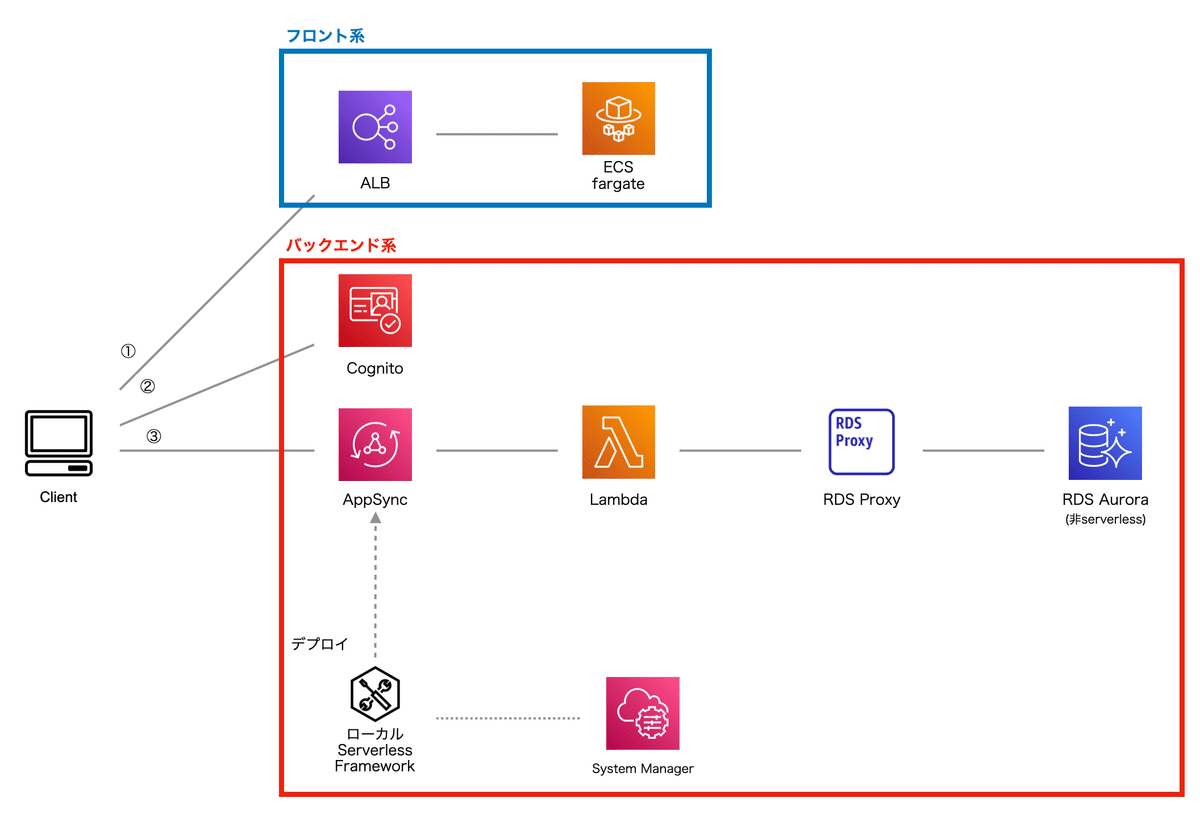
現在進めている構成では、①のECS FargateからはNext.jsが稼働してReactの配信を行います。必要に応じて②のCognitoで認証を挟みつつ、サーバーサイドからの必要な情報はAppSyncから取得します。管理画面用のデータベースには、RDS Aurora(非serverless)を使っている関係上、AppSyncのデータソースとしては、Lambdaを挟み、さらにLambdaとRDSとの間にRDS Proxyを挟む構成となっています。
現在、管理画面用のデータベースとしてRDB(MySQL)を使用して、ユーザー情報などのマスターデータや分析済のレポートデータなどもRDSに格納していますが、各テーブルの特性に応じて、DynamoDBへ移行する予定です。
もしかしたらフロント側の方が今後大きく拡張される可能性が高く、例えば、ClientとALBの間にCloudFrontを挿入しキャッシュさせると同時にLambda@Edgeで簡易的な処理を行いより高速なユーザー体験を提供していく流れになると想像しています。
今回、バックエンドの部分のAppSyncとデータソースとしてのLambdaをServerlessFrameworkで管理する方法についてご紹介したいと思います。
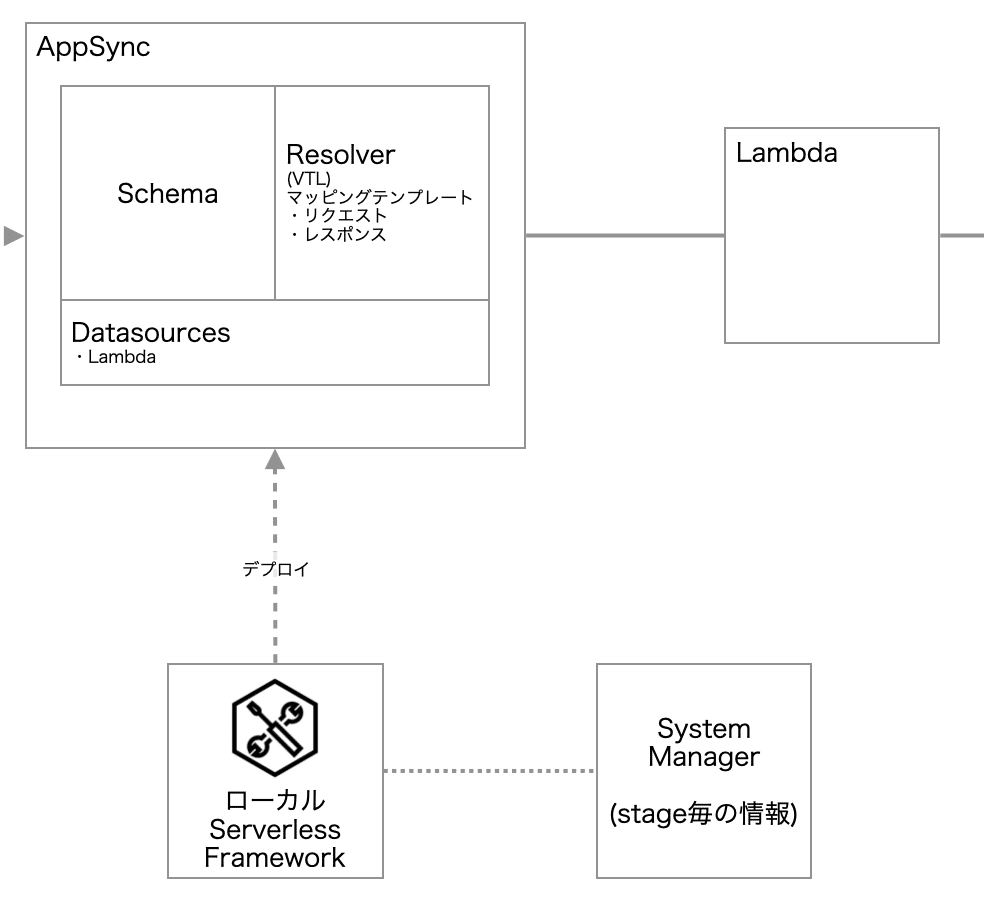
AppSyncを設定する上での主な構成要素としては、
・Schema
・Resolver
・Datasource
の3点だと思いますが、それらはAWSのコンソールパネルを使用し設定することができます。ただし、コンソールパネルのみではCI/CDの観点から実用的ではありません。そこで、ServerlessFrameworkで運用を進めます。
ServerlessFrameworkで実現したいこと
ServerlessFrameworkの詳細については、下記の公式サイトを参照頂ければと思います。
今回、ServerlessFrameworkを使って実現したいこととしては、主に下記になります。
・Schema / Resolver / Datasource、Lambdaのコード管理
・AppSync / Lambdaのローカル開発環境の構築
・AppSync / LambdaのCI/CD
基本設定
ServerlessFrameworkは、Node.jsを利用したフレームワークなので、npmでインストールできます。今回は、serverless-appsync-pluginというプラグインを使用するため、nodeのバージョン15.4.0以降である必要がありますので、予めnodeのバージョンは管理しておいてください。
開発用の任意のディレクトリ直下で、下記のコマンドを実行します。
serverless create --template aws-nodejs-typescript --path project_nameクラウドプロバイダーはAWSでtypescriptで開発を進めたいので、--templateは、一旦aws-nodejs-typescriptを選択します。
--path project_name と指定すると、project_nameというディレクトリが作成され、その中にテンプレートに紐付いた初期ファイルやディレクトリが作成されます。
serverlessコマンドは、slsというエイリアスもあるので、普段はそちらを使います。また、グローバル環境を汚したくない、パスを通すのが面倒などプロジェクト毎のnpmの管理もローカルで完結させておきたい場合は、npxを使うことをお勧めします。npxについては説明はここでは省きますが、気軽にコマンドを実行する際には便利です。
ですので、上記のコマンドは、普段は下記のように使用しています。
npx sls create --template aws-nodejs-typescript --path project_nameコマンドを実行するとproject_nameディレクトリ内に、serverless.tsというファイルが作成されていると思いますが、このファイルは、あらゆるAWSリソースに対する設定を記載するファイルで、重要なファイルです。serverless.tsの記述をベースにしてServerlessFrameworkが動作していきます。今回は、主にAppSyncのSchema/Resolver/Datasourceの設定やLambdaの設定について説明します。
ディレクトリ構成
上記のコマンドを実行すると、下記のようなファイル・ディレクトリが生成されます。
.
├── package.json
├── README.md
├── serverless.ts
├── src
│ ├── functions
│ │ ├── hello
│ │ │ ├── handler.ts
│ │ │ ├── index.ts
│ │ │ ├── mock.json
│ │ │ └── schema.ts
│ │ └── index.ts
│ └── libs
│ ├── apiGateway.ts
│ ├── handlerResolver.ts
│ └── lambda.ts
├── tsconfig.json
└── tsconfig.paths.jsonデータソース(Lambda)のディレクトリ
上記のデフォルトでのディレクトリ構成では、src配下にLambda関連のファイルの設置が想定されていますが、今回は一旦無視して、新たにdatasourcesというディレクトリを設置し、そこにAppSyncのデータソースとして振る舞うLambdaのコードを設置したいと思います。さらに今回は、そのLambdaはPythonで簡易的なコードを記述したので、下記のようなディレクトリで管理することを想定しています。
.
├── datasources
│ ├── appsync_datasource_rds.py
│ └── libs
│ ├── pymysql
│ └── ...リゾルバ(マッピングテンプレート)のディレクトリ
リゾルバのマッピングテンプレートの管理は、mapping-templatesディレクトリ配下で行いたいと思います。
例えば、Userというオブジェクト型に対するシンプルなvtlを設置する場合下記のようになっていく想定です。
│
├── mapping-templates
│ ├── Query.user.request.vtl
│ ├── Query.user.response.vtl
│ ├── ...mapping-templatesには、ひたすらリクエストマッピングとレスポンスマッピングのvtlを格納するというスタイルで考えています。
スキーマファイル
AppSyncの設定上欠かせないスキーマ設定ですが、このプロジェクトディレクトリ直下に、schema.graphqlというファイルを設置して進めます。
例えば、Userというオブジェクト型を定義し、そのidで取得するクエリを設置する場合、下記のような記述になります。
type Query {
user(id: ID!): User
...
}
type User {
id: Int!
type: String!
name: String
mail: String!
}shcema.graphqlの記述については省略します。スキーマ設計についての詳細は下記などを参考にしてください。
一旦、下記のようなディレクトリ構成になります。
.
├── datasources
│ ├── appsync_datasource.py
│ └── libs
│ ├── pymysql
│ ├── ...
│
├── jest.config.js
│
├── mapping-templates
│ ├── Query.user.request.vtl
│ ├── Query.user.response.vtl
│ ├── ...
│
├── test
│ ├── graphql-operation.test.ts
│ ├── ...
│
├── package.json
├── README.md
├── schema.graphql
├── serverless.ts
├── tsconfig.json
└── tsconfig.paths.json以下、serverless.tsの説明
ベース部分の設定
const serverlessConfiguration: AWS = {
"service": "project_name",
"useDotenv": true,
"frameworkVersion": "2",
"provider": {
"name": "aws",
"stage": "${opt:stage}",
"region": "ap-northeast-1",
"lambdaHashingVersion": "20201221",
"environment": {
"Foo": "${ssm:Params01}",
"Bar": "${ssm:${opt:stage}Params02}",
...
},
},環境変数的なパラメータは、上記のenvironmentにまとめて設定し、値はSystemManagerのパラメータストアから取得します。
"environment": {
"Foo": "${ssm:Params01}",
"Bar": "${ssm:${opt:stage}Params02}",
...
},その際、${ssm:パラメータ名}と記載すると取得できます。また、serverlessコマンドから、引数を渡したい場合、コマンドに "--stage Dev"などのようにstageオプションを指定して実行すると、${opt:stage}で引数を取得できます。
例えば、下記のようなコマンドでは、
npx sls deploy --verbose --stage Dev↓
serverless.ts内の${opt:stage}に"Dev"が代入されます。
これを組み合わせて、下記のような記述でも値を代入することもできます。
"Bar": "${ssm:${opt:stage}Params02}"この結果としては、Barには、パラメータストアのkeyが"DevParams02"に格納されている値が取得できます。
また、serverless.tsの中で定義した値も${self:変数へのパス}という形で使い回すことができたり、上記の"environment"内のパラメータは、${env:Foo}でも使用することができます。
Lambdaの設定
Lambdaの設定は、下記のように、"functions"内に記載します。
"functions": {
"appsync_datasource_rds": {
"name": "${opt:stage}_appsync_datasource_rds",
"runtime": "python3.8",
"role": "【appsync_datasource_rds用IAMのarn】",
"handler": "datasources/appsync_datasource_rds.lambda_handler",
"memorySize": 128,
"environment": {
"DB_HOST": "${env:DB_HOST}"
},
"vpc": {
"securityGroupIds": [
"【セキュリティグループID】"
],
"subnetIds": [
"【サブネットID】",
"【サブネットID】",
"【サブネットID】"
]
},
"package": {
"exclude": [
"**"
],
"include": [
"datasources/**"
],
"individually": true
}
}
},今回Lambdaは、AppSyncのデータソースとして扱う関数となります。"environment"の""DB_HOST"は、stageによって接続先を変更したいという要件があるので、slsからLambdaの環境変数へ渡しています。また、先程作成したdatasourcesディレクトリ内のファイル群をマージしてAWSへデプロイされる設定となっています。
AWSコンソールでは、下記の様なLambda側のコンソール画面で設定することが上記の記述で設定できているイメージです。
AppSyncの設定
基本設定とschema,datasource,マッピングテンプレートの紐付け設定
custom→appSyncに設定を記載しますが、基本的なパラメータの設定と、主に、schema,datasource,マッピングテンプレートの紐付けを行うような設定が多いです。
スキーマの設定
"custom": {
"defaultStage": "Dev",
"appSync": {
"name": "${opt:stage}_dashboard",
"apiId": "${env:AppsyncApiId}",
"authenticationType": "AMAZON_COGNITO_USER_POOLS",
"userPoolConfig": {
"userPoolId": "${env:DashboardUserPoolId}",
"defaultAction": "ALLOW"
},
"schema": "./schema.graphql",
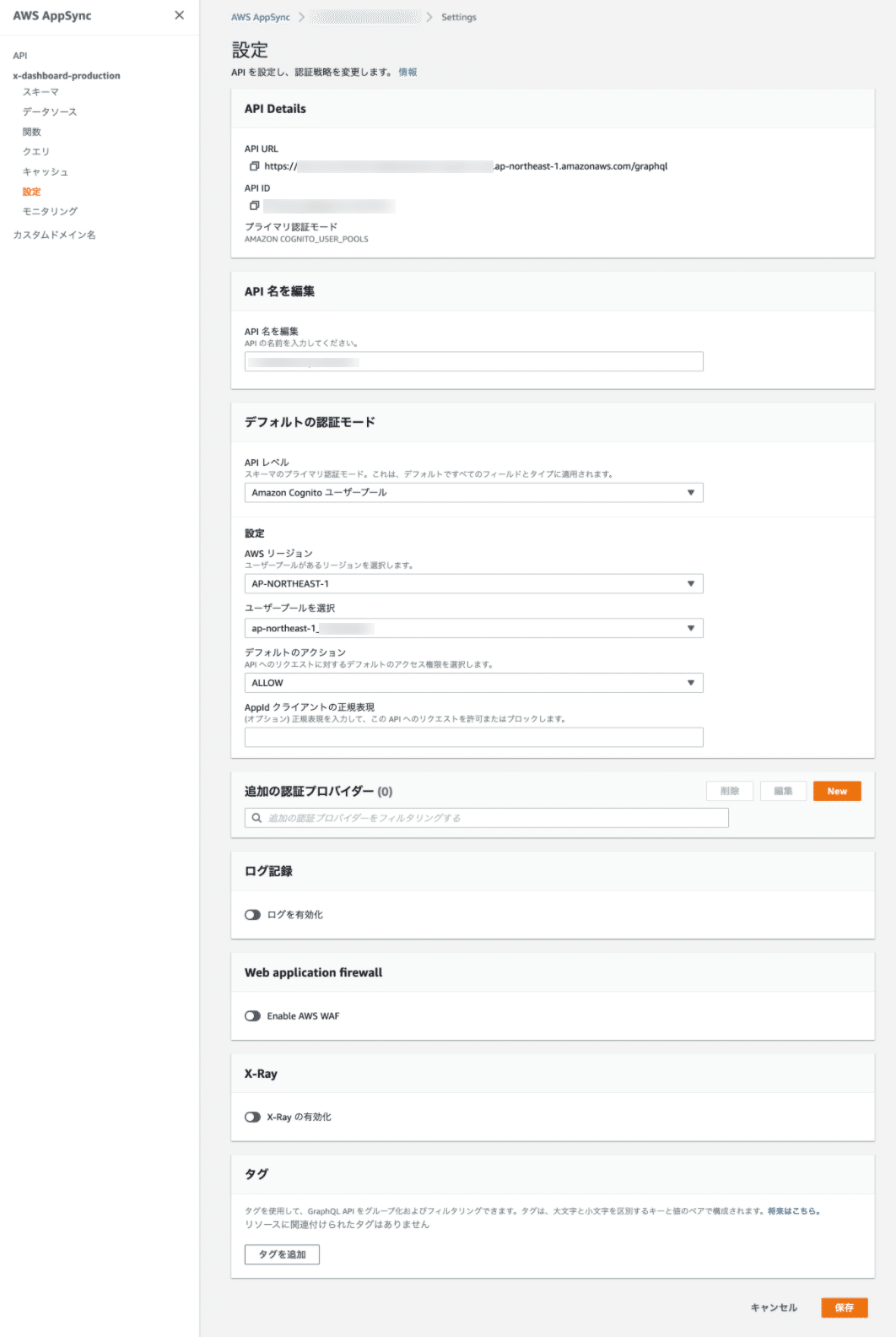
上記がAppSyncの基本的な部分の設定で、今回はユーザー認証でCognitoをしようするので、"authenticationType"や"userPoolConfig"を設定しています。
※ ${self:*}や${env:*}となっている部分はそれぞれ、任意の値を設定してください。
スキーマの指定は、
"schema": "./schema.graphql",という記述のみで、プロジェクトディレクトリ直下のschema.graphqlを使用します。
AppSyncの下記のAWSコンソール画面で行う設定となります。
データソースの設定
"dataSources": [
{
"type": "AWS_LAMBDA",
"name": "${opt:stage}_appsync_datasource_rds",
"description": "RDSとの接続用",
"config": {
"functionName": "appsync_datasource_rds",
"lambdaFunctionArn": "【Lambdaのarn】",
"serviceRoleArn": "【Lambdaが使用するIAMロールのarn】",
"iamRoleStatements": [
{
"Effect": "Allow",
"Action": ["lambda:invokeFunction"],
"Resource": ["*"]
}
]
}
}
],先程設定したLambdaをAppSyncのデータソースとして稼働させるための設定になります。
リゾルバ(マッピングテンプレート)
"mappingTemplatesLocation": "mapping-templates",
"mappingTemplates": [
{
"type": "Query",
"field": "user",
"dataSource": "${opt:stage}_appsync_datasource_rds",
"request": "Query.user.request.vtl",
"response": "Query.user.response.vtl"
},
...
],
},
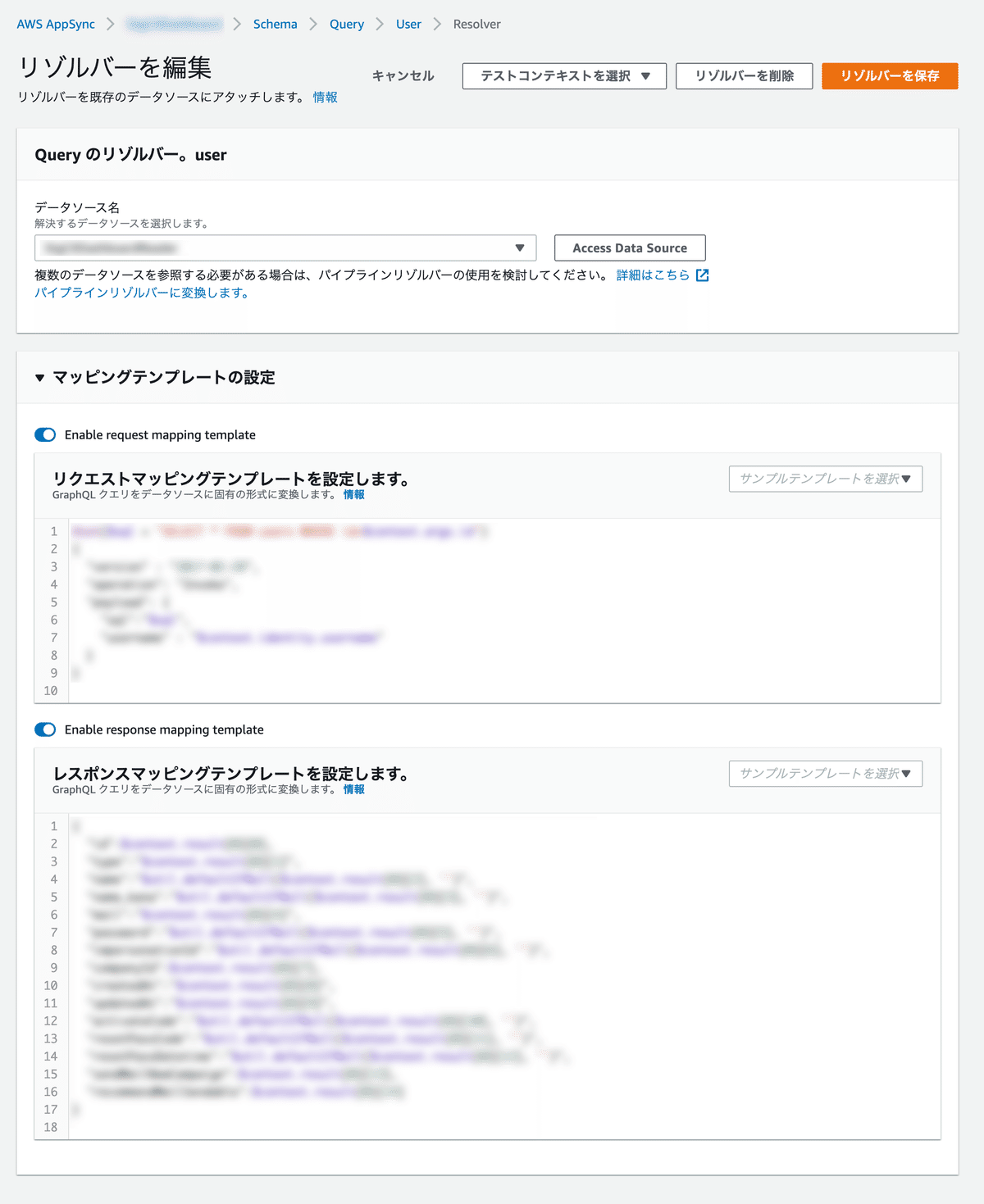
},"mappingTemplatesLocation"にディレクトリ構成のところで作成したmapping-templatesディレクトリを指定します。
"request"と"response"で対応するvtlのファイルを指定し紐つけていくイメージです。
AWSコンソールでは、下記の画面あたりの設定になります。
プラグイン
"plugins": [
"serverless-appsync-plugin",
"serverless-appsync-simulator",
"serverless-offline"
]
};プラグインはnpm installでインストール
今回は3つのプラグインを使用しますのでここに記載します。プラグインは、npmでインストールできるので、下記のコマンドでインストールしておきます。
npm install serverless-appsync-plugin serverless-appsync-simulator serverless-offlineここまでのserverless.ts設定の全体像としては、下記のようになります。ところどころ具体的なパラメータは任意で記載してください。
serverless.ts
import type { AWS } from "@serverless/typescript";
const serverlessConfiguration: AWS = {
"service": "project_name",
"useDotenv": true,
"frameworkVersion": "2",
"provider": {
"name": "aws",
"stage": "${opt:stage}",
"region": "ap-northeast-1",
"lambdaHashingVersion": "20201221",
"environment": {
"Foo": "${ssm:Params01}",
"Bar": "${ssm:${opt:stage}Params02}",
...
},
},
"functions": {
"appsync_datasource_rds": {
"name": "${opt:stage}_appsync_datasource_rds",
"runtime": "python3.8",
"role": "【appsync_datasource_rds用IAMのarn】",
"handler": "datasources/appsync_datasource_rds.lambda_handler",
"memorySize": 128,
"environment": {
"DB_HOST": "${env:DB_HOST}"
},
"vpc": {
"securityGroupIds": [
"【セキュリティグループID】"
],
"subnetIds": [
"【サブネットID】",
"【サブネットID】",
"【サブネットID】"
]
},
"package": {
"exclude": [
"**"
],
"include": [
"datasources/**"
],
"individually": true
}
}
},
"custom": {
"defaultStage": "Dev",
"appSync": {
"name": "${opt:stage}_dashboard",
"apiId": "${env:AppsyncApiId}",
"authenticationType": "AMAZON_COGNITO_USER_POOLS",
"userPoolConfig": {
"userPoolId": "${env:DashboardUserPoolId}",
"defaultAction": "ALLOW"
},
"schema": "./schema.graphql",
"dataSources": [
{
"type": "AWS_LAMBDA",
"name": "${opt:stage}_appsync_datasource_rds",
"description": "RDSとの接続用",
"config": {
"functionName": "appsync_datasource_rds",
"lambdaFunctionArn": "【Lambdaのarn】",
"serviceRoleArn": "【Lambdaが使用するIAMロールのarn】",
"iamRoleStatements": [
{
"Effect": "Allow",
"Action": ["lambda:invokeFunction"],
"Resource": ["*"]
}
]
}
}
],
"mappingTemplatesLocation": "mapping-templates",
"mappingTemplates": [
{
"type": "Query",
"field": "user",
"dataSource": "${opt:stage}_appsync_datasource_rds",
"request": "Query.user.request.vtl",
"response": "Query.user.response.vtl"
},
...
],
},
},
"plugins": [
"serverless-appsync-plugin",
"serverless-appsync-simulator",
"serverless-offline"
]
};
module.exports = serverlessConfiguration;設定が完了すれば、諸々の操作が動くようになります。
デプロイについて
下記のコマンドでデプロイができます。
npx sls deploy --verbose --stage Dev--verboseオプションを付けれていれば、進捗を確認でき、エラーなどなければ、大体、下記のような表示になります。
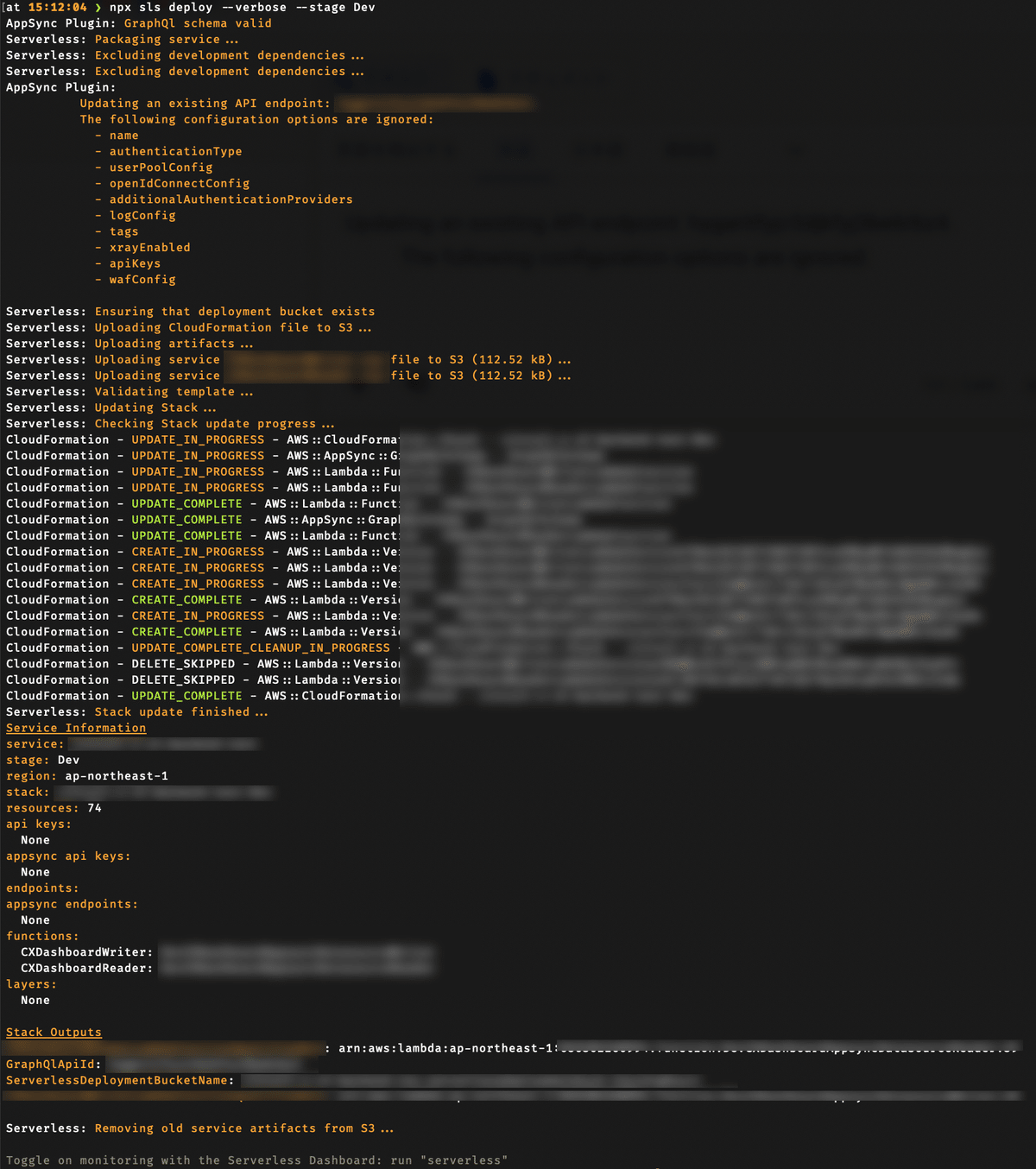
途中で何かしらのエラーが発生した場合は、元の状態へ戻すロールバックまで自動で行われます。
弊社ではローカルから直接デプロイすることはほとんどなく、通常はCircleCIでデプロイを行っています。
ローカルの開発環境について
ローカルの開発環境は、下記のコマンドを実行するとAppSyncのシミュレーターとそのクライアントのGraphiQLが立ち上がります。
npx sls offline start
ターミナルの表示にあるように、この場合、
http://192.168.1.85:20002
をブラウザ表示するとGraphiQLが立ち上がっており、vtlの変更などバックエンド側の開発を進める時は、GraphiQLでリクエストを叩きつつ進めます。
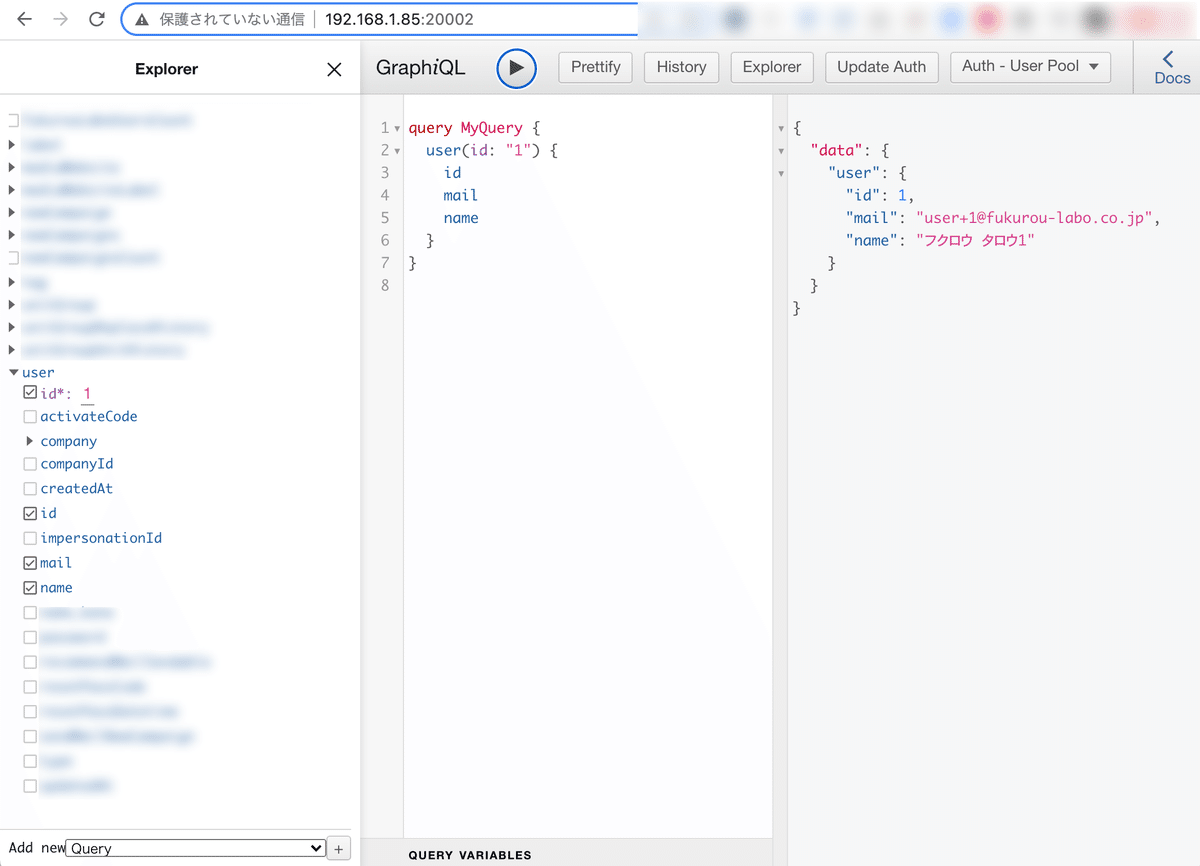
フロントの開発は、ローカルのAppSyncのエンドポイントとして
http://192.168.1.85:20002/graphql
が与えられているので、そこをエンドポイントとして進めるイメージです。
ちなみにここでシミュレートできているのは、AppSyncとLambdaのみなので、DBは別途でdockerで立ち上げ、Lambdaがそちらを見るように設定しています。
テストについて
ここでのテストは、Jestを使い、ローカルのAppSyncのエンドポイントに対してリクエストを出し、そのレスポンスが想定通りかのテストを想定しています。まず、テストに使用するパッケージをインストールします。
npm install --save-dev jest ts-jest @types/jest typescript graphql-requestまず、プロジェクトディレクトリ直下に"jest.config.js"というファイルを作成します。内容としては下記です。
module.exports = {
"roots": [
"<rootDir>/test"
],
"testMatch": [
"**/__tests__/**/*.+(ts|tsx|js)",
"**/?(*.)+(spec|test).+(ts|tsx|js)"
],
"transform": {
"^.+\\.(ts|tsx)$": "ts-jest"
},
}また、同じくプロジェクトディレクトリ直下に"test"というディレクトリを作成し、そこに下記のようなテスト用コードを作成します。
test/graphql-operation.test.ts
import { request, gql, GraphQLClient } from 'graphql-request'
export const user = gql`
query testQuery($id: ID!) {
user(id: $id) {
id
mail
name
}
}`;
const client = new GraphQLClient(
'http://localhost:20002/graphql',
{
headers: {
"Authorization": "xxx.eyJzdWIiOiI3ZDhjYTUyOC00OTMxLTQyNTQtOTI3My1lYTVlZTg1M2YyNzEiLCJlbWFpbF92ZXJpZmllZCI6dHJ1ZSwiaXNzIjoiaHR0cHM6Ly9jb2duaXRvLWlkcC51cy1lYXN0LTEuYW1hem9uYXdzLmNvbS91cy1lYXN0LTFfZmFrZSIsInBob25lX251bWJlcl92ZXJpZmllZCI6dHJ1ZSwiY29nbml0bzp1c2VybmFtZSI6InVzZXIxIiwiYXVkIjoiMmhpZmEwOTZiM2EyNG12bTNwaHNrdWFxaTMiLCJldmVudF9pZCI6ImIxMmEzZTJmLTdhMzYtNDkzYy04NWIzLTIwZDgxOGJkNzhhMSIsInRva2VuX3VzZSI6ImlkIiwiYXV0aF90aW1lIjoxOTc0MjY0NDEyLCJwaG9uZV9udW1iZXIiOiIrMTIwNjIwNjIwMTYiLCJleHAiOjE1OTY5NDE2MjkwLCJpYXQiOjE1NjQyNjQ0MTMsImVtYWlsIjoidXNlckBkb21haW4uY29tIn0.xxx"
}
}
);
describe("Resolver test", () => {
test("query", async () => {
const valiables = {
"user": {
id: 1,
mail: "user+1@fukurou-labo.co.jp",
name: "フクロウ タロウ1"
}
};
expect(
await client.request(
user, {id: valiables.user.id}
)
).toEqual(valiables);
});
});queryでuserを取得できるかのシンプルなテストです。
下記のコマンドでテストを実行できます。
npx jest --watch問題なければ、下記のような表示で完了します。
PASS test/graphql-operation.test.ts
Resolver test
✓ query (307 ms)
Test Suites: 1 passed, 1 total
Tests: 1 passed, 1 total
Snapshots: 0 total
Time: 3.053 s
Ran all test suites related to changed files.もろもろ所感
駆け足でAppSync周りの環境構築についてご紹介しました。もっと詳細について記載したい内容もあるのですが、書いているうちにボリュームが増えてしまったことと、詳細部分については何か特定のサンプルアプリを作るなどの設定がないと書きにくいため、一旦、ざっくり全体像が把握できる形でこの記事を書きました。ただ、実際に環境を構築してみて感じたこととして、VPCやセキュリティーグループ、各セクションのIAMでの権限とstage毎のSystemManagerでのパラメータ管理などの細かい部分の設定まで記事にすると複雑になりすぎるためこの記事では省略しているのですが、実際にはそういった細かい設定に、多くの時間を取られます。
また、プロジェクト内のディレクトリ構成は、まだ推敲の余地がありそうで、現段階でもすでに「変更して整理したい」と思ってしまっています^^;このあたりはプロジェクトの規模に応じてファイル分割を行い、ディレクトリもフレキシブルに変更するつもりで進めていった方が良いのだと思います。
引き続き、開発を進めますので、その過程でチーム内でディスカッションしながらより良いプラクティスを見つけていきたいと思います!