文系大学生がAPIを使って、論文情報をスクレイピングしてみた

はじめに
こんにちは!私は文系の大学生ですが、最近、プログラミングの授業でAPIの利用方法を学び、それを使って実際に学術論文の情報を収集してみることに挑戦しました。今回はJ-STAGEという学術ジャーナルのプラットフォームから、特定の研究トピックに関する論文情報を抽出する方法を共有したいと思います。技術的な詳細を理解するのは少し難しいかもしれませんが、一緒に学んでいきましょう!
この記事でできること
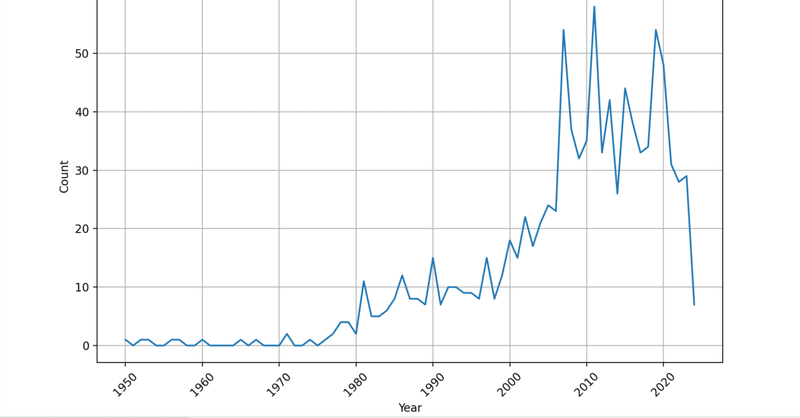
このコードがあれば、自分の好きなキーワードで論文発行数の推移が表示できちゃいます!
指定した学問分野の歴史的な流れが一目で分かっちゃいますね。
環境設定
まず、Pythonというプログラミング言語を使います。Pythonにはデータ収集と分析を簡単にするライブラリが多くあります。今回使用する主なライブラリは以下の通りです。
Requests: ウェブからデータを取得するために使います。
BeautifulSoup: 取得したデータから必要な情報を抜き出すのに便利です。
Pandas: データを表形式で扱いやすくします。
Matplotlib: データをグラフにして視覚化します。
これらのライブラリをインストールするには、以下のコマンドを実行します。
pip install requests beautifulsoup4 pandas matplotlibAPIリクエストの実行
次に、J-STAGEのAPIを使って、興味のあるトピック「organization economics」に関する論文データをリクエストします。APIのエンドポイントに適切なパラメータを設定して、データをリクエストします。
データの解析と整形
BeautifulSoupを使ってXML形式のレスポンスから必要な情報を抽出します。論文のタイトル、リンク、公開年を取り出し、これをPandasのデータフレームに保存します。
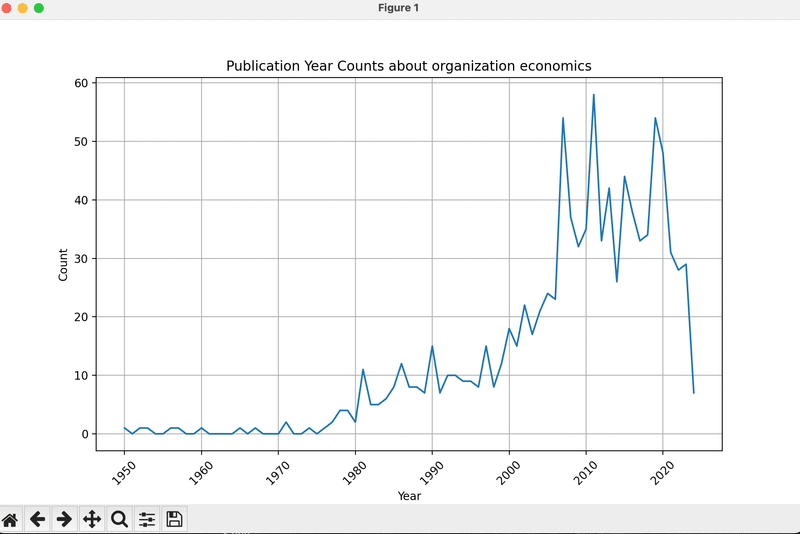
データの可視化
最後に、Matplotlibを使って論文がどの年にどれだけ発表されたかをグラフにしてみます。これにより、研究のトレンドが時間とともにどのように変化しているかが一目でわかります。
サンプルコード
以下のコードが、私が実際に使用したスクリプトです。このコードを実行することで、論文のデータを取得し、年度別に可視化することができます。
import requests
from bs4 import BeautifulSoup
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
searchword= "organization economics"
base_url = "http://api.jstage.jst.go.jp/searchapi/do?service=3&text={keyword}"
base_url = base_url.format(keyword = searchword)
# APIリクエストを送信
response = requests.get(base_url)
# レスポンスのXMLをBeautifulSoupで解析
soup = BeautifulSoup(response.content, 'lxml-xml')
# entryで検索し、その中の指定したタグを抽出する
articles = []
entries = soup.find_all('entry')
for etag in entries:
title = etag.find('article_title').ja.get_text()
link = etag.find('link')['href']
pubyear = etag.find('pubyear').get_text()
articles.append({'Title': title, 'Link': link, 'Publication Year': pubyear})
df = pd.DataFrame(articles)
# 'Publication Year'列を整数型に変換
dfplot = df['Publication Year']
dfplot = pd.to
_numeric(dfplot)
# 年度ごとの出現回数をカウント
counts = dfplot.value_counts()
# 登場しない年度も含めた範囲を指定(最小年から最大年)
year_range = range(dfplot.min(), dfplot.max() + 1)
counts = counts.reindex(year_range, fill_value=0)
# カウントをプロット
counts.plot(figsize=(10, 6))
plt.title('Publication Year Counts about {}'.format(searchword))
plt.xlabel('Year')
plt.ylabel('Count')
plt.xticks(rotation=45)
plt.grid(True)
plt.show()注意点
検索する際のキーワードとなる「searchword」は、そのままだと英語しか入りません。日本語を入れたい場合は、それをエンコードして暗号のようなものにすればできます。
以下に日本語をエンコードできるサイトのリンクも載せますね。
まとめ
プログラミングは難しそうに感じるかもしれませんが、実際には色々なツールが用意されており、これを使うことで私たちの学びや研究がより便利になります。
この記事が皆さんにとって、プログラミングやデータ分析の楽しさを少しでも感じる一助となれば幸いです。
私は今後もたくさんコードを書いていく予定です!
参考文献
↓J-STAGEが出してるapiの使い方マニュアルです!
この記事が気に入ったらサポートをしてみませんか?