
【kaggleCassava Leaf Disease Classification】AIによるキャッサバの病害自動診断 ウィニングソリューションまとめ

ESTYLEのデータサイエンス事業部新メンバーの小林です。
本記事は、Kaggleコンペにチャレンジし始めて日が浅いビギナーに向けて、Kaggleコンペの内容とソリューションを分かりやすく伝えることに重きを置いています。
今回は画像分類コンペである[1]Cassava Leaf Disease Classificationのウィニングソリューションについてまとめてみました。画像分類に触れるのはこのコンペが初めてだったので、非常に楽しく勉強できました。
ソリューションの理解やモデリングの知識等間違っていることがございましたら、ぜひコメントでお知らせ下さい。
コンペ概要

キャッサバの葉の画像から、病気にかかっているかどうかを判別する
今回はキャッサバの葉が病気にかかっているかどうかを判別する画像分類のコンペを取り上げます。([1]Cassava Leaf Disease Classification )
キャッサバとはアフリカにおける主要炭水化物の一つで、過酷な条件でも生育可能であることから食料安全保障の観点から重要な作物です。
本作物の収量低下の主要因はウイルス性の病気です。病気を検出する既存の方法として、農家が農業専門家の協力を得て、植物を目視検査するという手法がありますが、そのリソースは限られています。また、農家が持つカメラによって得られる画像の質は低いです。
よって、本案件で求められるソリューションは低画質の画像データをもとに瞬時に病気を判別する機械学習モデルとなります。このモデルを構築することができれば、農家は病気にかかった植物を即時に特定し除去することで、収量を増加させることができます。
データセットについて
本コンペのデータは、21,367枚のラベル付き(4種類の病気カテゴリーと正常な葉)のキャッサバ画像です。
入賞者のソリューションについて
1.28位のソリューション([2])
画像分類タスクで決める必要があることは大きく分けて①画像前処理、②機械学習モデル、③モデルの学習方法、④推論方法です。
①画像前処理
まず画像前処理に関して、一般的にデータ数が多い程、機械学習モデルの精度は向上するとされています。一方で、今回のコンペのように画像をこれ以上増やすことは現実的に困難である場合、画像の水増し(Data Augmentation)を行います。具体的には、手持ちの画像の回転・反転等を行いデータを増やします。
実際今回のコンペで28位の参加者([2])は、教師データにランダムに拡大・縮小、転置、y軸を中心に水平反転、x軸を中心に垂直反転、ランダムにアフィン変換(平行移動、拡大縮小、回転)、ランダムに色相、彩度、輝度を変更(初期設定対比変化は微小になるように制限)、ランダムに明るさとコントラストを変更(初期設定対比変化が小さくなるように制限)、ランダムに黒塗り(CoarseDropout、Cutout)を行っています。
特に今回コンペの画像において、輝度・明るさとコントラストを初期設定のまま使用すると、あまりにも異なる画像ができてしまうことから、パラメータの調整を明示的に行っていることが印象に残りました。kaggleで上位を狙うには、テストデータの状況も踏まえながら、適切なAugmentationを行っていくことが重要なのかなと思いました。
本ソリューションでは、目新しいaugmentationの手法として以下の二つを扱っています。
1. Mixup
2つの画像を混ぜる手法です。CutMixのように2枚だけを組み合わせるのではなく、画像4枚を組み合わせることも可能です。こうすることで、ミニバッチのサイズを小さいままで学習することができます。ドメイン知識がなくてもAugmentation可能である事がこの手法の素晴らしい点です。
2. CutMix
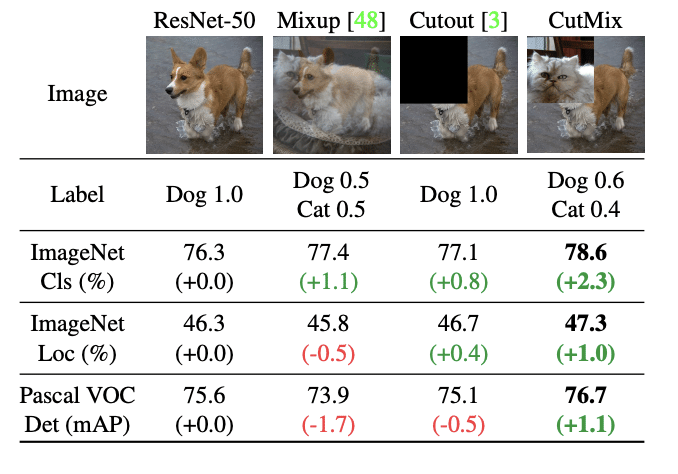
[3]Table1:Mixup,Cutout,CutMixそれぞれから得られた精度
CutMixの名前の由来はCutoutとMixupです。名前の通りCutoutとMixupの技術それぞれを合わせたような手法になっています。上図はCitMixの論文からの引用で、Mixup,Cutout,CutMixのそれぞれの手法についての画像イメージと精度が確認できます。
②機械学習モデル
一般的に機械学習モデルは大きく深層学習系と非深層学習系に大別されます。今回のコンペのように画像分類タスクは深層学習系が非深層学習系対比で良好な結果を示しており、実際画像分類のベンチマークモデルは深層学習系で占められています。
深層学習系のモデルとしては画像認識タスクで良好な精度を誇る、CNN(convolutional neural network)モデルと近年発展しているTransformerモデルがあります。
特にTransformerモデルは脱CNNとして自然言語処理で大きな成果を既に挙げていることから、近年では画像分類への適用も試みられており、2020年12月にGoogle よりコードとモデルがオープンソース化されました([5])。具体的には、入力データのどの部分を重視するかを決めるという手段(アテンション機構)を用いたモデルになります。例えばVision Transformerでは、入力画像を分解し1行に並べ、各画像をTransformer encoderに入力し、Attentionを計算しています。
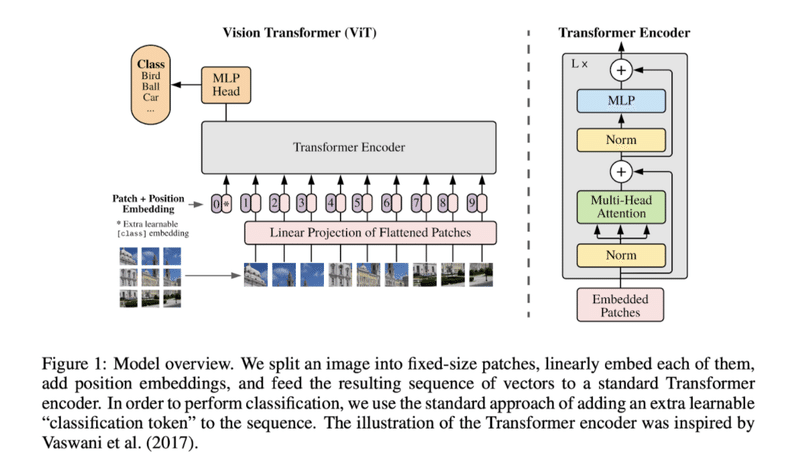
[6] AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
実際、今回のコンペで28位のソリューション([2])はCNNモデルとしてefficientnetとseresnext(SENetとResNextを組み合わせたモデル)、TransformerモデルとしてVision transformerを用いています。
また、efficient netとVision Transformerは画像分類タスクのベンチマークモデルの一つであり([7])、kaggleで上位を狙うには、SoTA論文を読み、最新のベンチマークモデルを実装する必要があるのかなと思いました。
③モデルの学習方法
本ソリューションでは、ラベルスムージング(Label Smoothing)という正則化手法(過学習を防ぐためのテクニックの一つで、回帰式をシンプルな形状に保つ方法)を用いています。この手法はノイジーなデータを含む深層学習において有効です。
ラベルスムージングは学習データの正解ラベルを少しぼかした値にする方法です。ハイパーパラメータ「ε」(0<ε<1)を設定し、正解クラスのラベル数値を「1」→「1-ε」、他の不正解クラスラベルの数値を「0」→「ε/(k-1)」(k:クラス数)に置換します。こうすることで、訓練データに対する過学習を防ぐことができるのです。
また、一般的に最適化手法で大きく決めなければならないことは下記の4点です。
・学習方法
・optimizerの種類
・ハイパーパラメーターの調整
・学習回数
学習方法とはモデルのファインチューニング(モデルの全てのレイヤーの重みを再学習)を行うのか、あるいはモデルを用いた転移学習(モデルの全結合層付近の重みのみを再学習)を行うのかといったことです。他のタスクで優秀な精度を出したモデルの構造を引っ張ってきて、今回のタスクに合うようにモデルを学習し直すことで、今回取り組むタスクに最適なモデルを構築できるのです。
一般的に、データ数が多いのであれば、ファインチューニングを行います。今回のコンペは画像数が2000枚を超えていることからファインチューニングを適用してもいいかもしれません。
optimizerとは推論データと教師データの誤差を最小化させるように、モデル内のパラメーターを調整するアルゴリズムです。以下に例として、単純なoptimizerであるSGD(Stochastic Gradient Descent : 確率的勾配降下法)を示します。尚、Eは誤差関数・wはモデル内のパラメーター・ηは学習係数・tは学習回数になります。
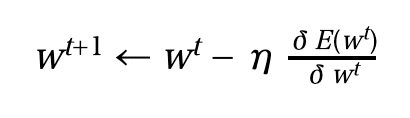
その他手法として、バリデーションデータのlossを学習毎に計算し、過学習を起こす前に学習を止めるearly stopping等々様々な手法もありますが、本記事内で網羅的に解説するのは難しいので、また別の記事で紹介できればと思います。
④推論
推論時には各モデルに対してTest Time Augmentation (TTA)を9回+Augementation無しを1回行い、各回の出力結果(ラベルの確率)を平均したものを最終的な推論結果としています(アンサンブル)。
TTAとは学習時ではなくテストデータを推論する時にAugmentationを行う手法であり、精度が上がることから画像コンペではよく用いられる手法です。また、本参加者はtrain augmentation対比でTTA時に複雑なaugmentation手法を削減しており、これも精度向上につながるポイントでした。
2.71位のソリューション([4])
①画像前処理
71位のソリューション([4])も、教師データに対して21位参加者と全く同様のData Augmentationを行っています。これは、公開された良好なData Augmentationのコードを他参加者が参考にして使っているからです。このように、参加者同士が自分の知見を公開しながら、お互いにスコアを上げていくのもKaggleの面白いところかと思います。
②機械学習モデル
本ソリューションもCNNモデルとしてefficientnet、TransformerモデルとしてVision transformerを用いています。
③モデルの学習方法
残念ながら本ソリューションもどのようにモデルを学習させているのかは開示していませんでした。
④推論
本参加者もTTA 4回とアンサンブルを行なっています。また、本参加者もtrain augmentation対比でTTA時にaugmentationを一部減らしています。なお、アンサンブルに当たって、efficientnet対比、Vision Transformerの推論結果の比重を大きくしています。各モデルを単体で比較した際にVision Transformerの方が精度が良かったのかもしれません。
まとめ(所感)
今回はkaggleの画像認識コンペと、コンテスト上位者のコードから見た有効な手法をまとめてきました。
所感としては、画像分類コンペでkaggle上位になるためにはSoTA論文を読み、最新のベンチマークモデルを実装するのはマストであり、その上でAugmentationとアンサンブルを工夫することが必要なのかなと思いました。また、学習モデルの最適化についても多くの手法が提案されており、有効な手法をピックアップするためにもkaggle等で更に学習を進め、自身で実装を行い実験を積んでいくことが必要だと感じました。
一方で、各モデルが過去モデル対比何を改善しなぜベンチマークを叩き出せたのか、というところの理解が足りておらず、各モデルの理解を深める必要性を感じました。また、学習モデルの最適化についても多くの手法が提案されており、有効な手法をピックアップするためにもkaggle等で更に学習を進め、自身で実装を行い実験を積んでいくことが必要だと感じました。
ライター紹介
名前:小林 勅三
経歴:素材メーカーで研究開発2.5年・事業開発1年を行った後、ESTYLE入社
担当業務:研修中
参考文献
[1] Kaggel,”Cassava Leaf Disease Classification”
https://www.kaggle.com/c/cassava-leaf-disease-classification
[2] Kaggle,”Cassava - Inference”
https://www.kaggle.com/imokuri/cassava-inference/notebook
[3] CutMix: Regularization Strategy to Train Strong Classifiers
with Localizable Features
https://arxiv.org/pdf/1905.04899.pdf
[4] Kaggle,”ViT: Ensemble CYD”
https://www.kaggle.com/yindachen/vit-ensemble-cyd/notebook
[5] Github,”google-researvh/vison_transformer”
https://github.com/google-research/vision_transformer
[6] OpenReview.net,” AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE”
https://openreview.net/pdf?id=YicbFdNTTy
[7] Browse State-of-the-Art
https://paperswithcode.com/task/image-classification
採用情報
ESTYLEは、「コウキシンが世界をカクシンする」という理念のもと、企業のDXを推進中です。経験・知識を問わず、さまざまな強みを持ったエンジニアが活躍しています。
弊社では、スキルや経験よりも「データを使ってクライアントに貢献したい」「データ分析から社会を良くしていきたい」という、ご自身がお持ちのビジョンを重視しています。
ご応募・問い合わせはこちら。
この記事が気に入ったらサポートをしてみませんか?