
10章 三日月状のクラスタリング🌙

はじめに
シリーズ「Python機械学習プログラミング」の紹介
本シリーズは書籍「Python機械学習プログラミング PyTorch & scikit-learn編」(初版第1刷)に関する記事を取り扱います。
この書籍のよいところは、Pythonのコードを動かしたり、アルゴリズムの説明を読み、ときに数式を確認して、包括的に機械学習を学ぶことができることです。
Pythonで機械学習を学びたい方におすすめです!
記事の内容
この記事は「第10章 クラスタ分析-ラベルなしデータの分析」で作成したグラフがとても微笑ましくて、思わず書いたものです。
具体的には、以下のコードとグラフを紹介します。
三日月状のデータセット:make_moons
3つの手法による三日月データのクラスタリング
10章のダイジェスト
この10章は、教師なし学習であるクラスタリングを取り扱っています。
以下のクラスタリング手法をPythonで動かして、各手法の特徴を知ることができます。
k-means法
階層的クラスタリング
DBSCAN
また、k-means法のハイパーパラメータである「クラスタの個数$${k}$$」の探索に役立つエルボー法、シルエット分析を解説しています。
三日月、現る
三日月状のデータセット:make_moons
「10.3 DBSCANを使って高密度の領域を特定する」に面白いグラフがありました。
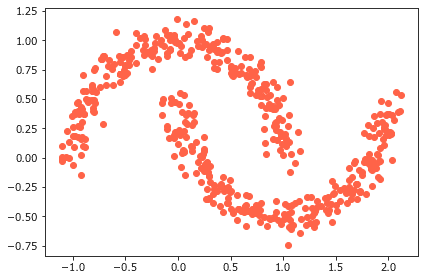
三日月状の帯が2本、握手するかのようにプロットされています。
なんだか微笑ましい気持ちになりました。
このグラフのもとになるデータは、scikit-learnのdatasetsクラスのmake_moonsをインポートすることで作成できます。
サンプルコードを添えておきます。
from sklearn.datasets import make_moons
import matplotlib.pyplot as plt
# 三日月状の構造を持つデータの生成
X,y = make_moons(n_samples=500, noise=0.08, random_state=0)
# 散布図を描画
plt.scatter(X[:, 0], X[:, 1], color='tomato')
plt.tight_layout()
plt.show()3つの手法による三日月データのクラスタリング
三日月状の2本の帯を2つのグループに識別できるかどうかについて、3つのクラスタリング手法の比較をします。
1つ目はk-means法。代表的なクラスタリング手法です。
2つ目は凝集型階層的クラスタリング手法の1つである完全連結法。グループ分けの様子を樹形図で可視化できる手法です。
3つ目はDBSCAN。データ点の局所的な密度に基づいてグループ分けする手法です。
3手法のグラフを並べて比較しました。

2つのグループを青(クラスタ1)と赤(クラスタ2)で塗り分けています。
k-means法と完全連結法は、1つの帯が複数のグループに分解されています。うまくグループ化できていないようです。
DBSCANは1つの帯が1つのグループに分類されている様子が分かります。
さまざまな手法を可視化して確認できるのは楽しいですね!
サンプルコードを添えておきます。
# k-means法、完全連結法、DBSCANを比較する
from sklearn.cluster import KMeans
from sklearn.cluster import DBSCAN
from sklearn.cluster import AgglomerativeClustering
from sklearn.datasets import make_moons
import matplotlib.pyplot as plt
# 三日月状の構造を持つデータの生成
# n_samples : 点の数
# noise : 点のばらつき
X, y = make_moons(n_samples=250, noise=0.1, random_state=0)
# リスト定義
clrs = [km, ac, db]
titles = ['k-means', 'Agglomerative clustering', 'DBSCAN']
colors = ['steelblue', 'tomato']
markers = ['o', 's']
# インスタンス生成
km = KMeans(n_clusters=2, random_state=0)
ac = AgglomerativeClustering(n_clusters=2, affinity='euclidean',
linkage='complete')
db = DBSCAN(eps=0.2, min_samples=5, metric='euclidean')
# 予測&描画
fig, ax = plt.subplots(1, 3, figsize=(12, 4))
for i, (clr, title) in enumerate(zip(clrs, titles)):
y_fit = clr.fit_predict(X)
for j, (color, marker) in enumerate(zip(colors, markers)):
ax[i].scatter(X[y_fit==j, 0], X[y_fit==j, 1],
color=color, marker=marker, edgecolors='lightgray',
s=50, lw=1, label=f'クラスタ {j+1}')
ax[i].set_title(title)
fig.suptitle('クラスタリング比較')
plt.legend()
plt.tight_layout()
plt.show()【参考:パラメータ説明】
■KMeans(n_clusters=2, random_state=0)
- n_clusters : クラスタの個数$${k}$$
■AgglomerativeClustering(n_clusters=2, affinity='euclidean', linkage='complete')
- n_clusters : クラスタの個数$${k}$$
- affinity : 類似度の指標(この例ではユークリッド距離)
- linkage : 連結方法(この例では完全連結法)
■DBSCAN(eps=0.2, min_samples=5, metric='euclidean')
- eps : 近傍点とみなす2点間の最大距離(半径$${\varepsilon}$$)
- min_samples : ボーダー点の最小個数(MinPts)
- metric : 距離の計算法(この例ではユークリッド距離)
まとめ
今回は、scikit-learnのデータセットに用意された三日月状のデータの形状と、クラスタリング結果の可視化に触れました。
機械学習を目で楽しみ、そして、愛でる。こんな感じです。
# 今日の一句
print('機械学習はArtかも')楽しくPython機械学習プログラミングを学びましょう!
おまけ数式
noteでは数式記法を利用できます。
今回はk-means法の最適化に用いられる「クラスタ内残差平方和」(SSE)の式を紹介します。
$${\mu^{(j)}}$$はクラスタ$${j}$$の中心点(セントロイド)です。
$$
SSE=\displaystyle \sum^n_{i=1} \sum^k_{j=1} w^{(i,j)} \bigl\lVert \boldsymbol{x}^{(i)} - \boldsymbol{\mu}^{(j)}\bigr\rVert^2_2\\
\\
w^{(i,j)}=
\begin{cases}
1 & (x^{(i)} \in j)\\
0 & (x^{(i)} \notin j)
\end{cases}
$$
おわりに
AI・機械学習の学習でおすすめの書籍を紹介いたします。
「統計検定2級対応 統計学基礎」
データサイエンスの基礎を補強する上で、確率・統計の知識は欠かせないものになっています。
統計分野の資格の代表格が「統計検定」。
大学基礎課程レベルである「2級」から学んでみませんか?
2級を足がかりにして、上位の準1級、1級に次々とチャレンジしていくのもいいと思います。
私はこの公式テキストと公式問題集を利用して、2級を(ぎりぎり)取得しました。
試験の詳しい内容は、統計検定のホームページでご確認下さい。
なお、最近、公式問題集が刷新されました。CBT方式に対応したとのこと。
最後まで読んでくださり、ありがとうございました。
この記事が気に入ったらサポートをしてみませんか?