

#大規模言語モデル


生成AI活用の試行錯誤〜Ubie社での取り組み〜
生成AIChatGPTをはじめとするGenerativeAI(生成AI)は、テレビや新聞で見ない日はないくらいに話題になっています。YouTubeでも芸人さんがChatGPTを紹介する動画が多数出ています。(個人的に、芸人かまいたちの「ChatGPTに漫才を作ってもらう」という動画が好きです。)
企業でも、ソフトバンクやNTTなどの大企業が、会社を上げて生成AIの開発・活用をしていくと発表してい

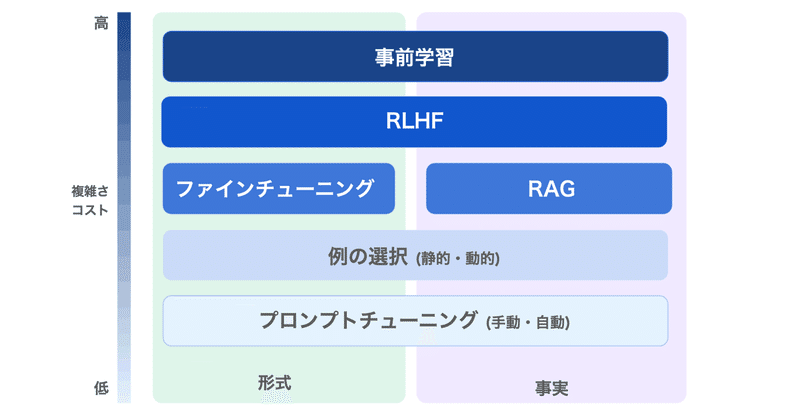
LLMのファインチューニング で 何ができて 何ができないのか
LLMのファインチューニングで何ができて、何ができないのかまとめました。
1. LLMのファインチューニングLLMのファインチューニングの目的は、「特定のアプリケーションのニーズとデータに基づいて、モデルの出力の品質を向上させること」にあります。
OpenAIのドキュメントには、次のように記述されています。
しかし実際には、それよりもかなり複雑です。
LLMには「大量のデータを投げれば自動


無料でGPT4越え!?ついに来たXwin-LM
今日のウィークリーAIニュースではnpaka大先生と一週間のニュースを振り返った。今週もいろいろあったが、なんといってもダークフォース、GPT-4越えと言われるXwin-LMである。中国製。
大先生もまだ試してないというので番組内で一緒に試してみた。
もちろんドスパラ製Memeplexマシン(A6000x2)を使用。
>>> from transformers import AutoToken


Rinna 3.6B の量子化とメモリ消費量
「Google Colabでの「Rinna 3.6B」の量子化とメモリ消費量を調べてみました。
1. 量子化とメモリ消費量「量子化」は、LLMのメモリ消費量を削減するための手法の1つです。通常、メモリ使用量が削減のトレードオフとして、LLMの精度が低下します。
AutoTokenizer.from_pretrained()の以下のパラメータを調整します。
2. Colabでの確認Colabで