Tableauで一段上のビジュアライゼーションを目指す|Viola chart(中編)

前回のエントリではViola chart作成に向けた前編としてExcelで必要になる準備を説明しました。
今回は実際にTableauを用いて作業を進めていきます。作業ファイルは前編でご作成いただいたExcelか、私が用意した下記のファイルをダウンロードして作業を開始しましょう。
※私の今回のTableau使用環境は2020.2です。このバージョンと異なるものでも正常に機能しますのでご安心ください。
実践①:Data Densificationを実行する
Tableauを開いたらまずは今回使用するExcelをつなげましょう。つなげることができたらデータソースからシート1に移り、まずはData paddingを実行します。「To Pad」というメジャーデータを右クリック→作成→ビンに移行します。
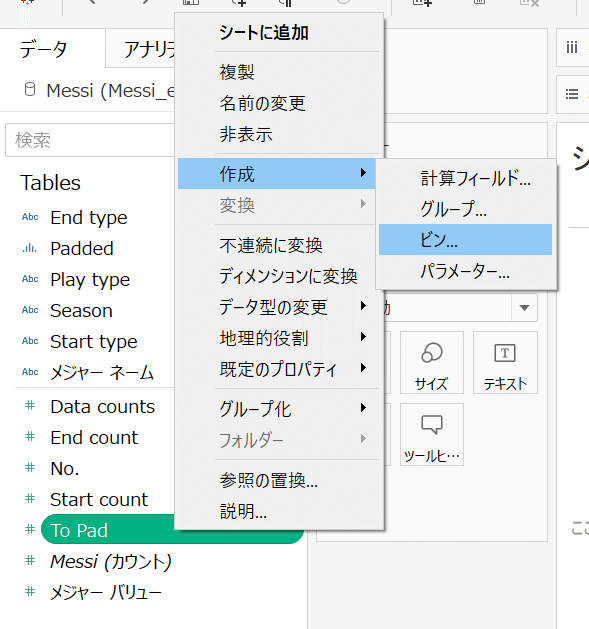
今回は滑らかな曲線を描きたいため、ビンのサイズは1にし、新しいフィールド名は「Padded」と名付けます。これを列に入れると1~49まで画面に表示されるのを確認できると思います。
ここで行に下記関数を直接入力してみましょう。
行:index()
すると下記のような画面になったかと思います。
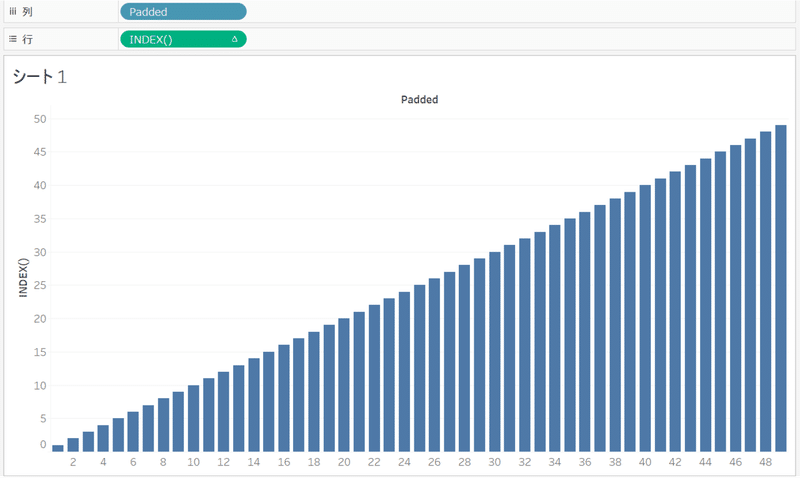
index()関数というのは、 表計算内でパーティション(分割された特定の領域)の現在の行のインデックス(順番)を返す関数となります。今後よく使う概念なので頭の片隅に置いておいてください。
実践②スケーリング係数(t)の作成
ではいったん行のindex()関数を削除いただき、スケーリング係数(t)の作成に移ります。
計算フィールドを起動して下記の計算式を入力します。
計算フィールドタイトル:t
(index()-25)/4
この式の意味について少し解説します。
今回はToPadに1と49という元となるデータを入れていたため、その約半分の25でマイナスし、indexがちょうど真ん中で分岐する関係を表現し、4で割ることで行の範囲を±6に納め、スムーズなグラフに仕立てています。
※4で割らなくても見た目上に変化はありませんが、±25の範囲になるので、少し見づらくなります。
tはこれから使用していく曲線の基になる計算です。
実践③Sigmoidの作成
Sigmoidとは、下記グラフのようなことです。
![]()
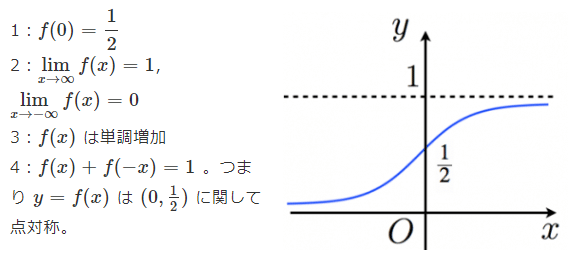
出典は画像リンクに貼ってあります。
いや、わかるかい!ってなったと思います。
ここでは、下記のように理解しておいてください。
入力した値を0から1の間に収めてくれる関数の1つ。S字曲線を描き、分布を表すときに使用されるもの。
要は今回は滑らかな曲線を描きたいからSigmoidとやらを使うんだなとご理解いただければ幸いです。
計算フィールドを下記式に入力しましょう。
計算フィールドタイトル:Sigmoid
1/(1+EXP(1)^-[t])
これは、上記で貼り付けたこの式を再現したものになります。ここでは-[t]を乗数にしてスケーリング係数を挿入しています。[t]の中にはindex()関数が含まれているため、expを行にドラッグアンドドロップすると下記のような図になります。
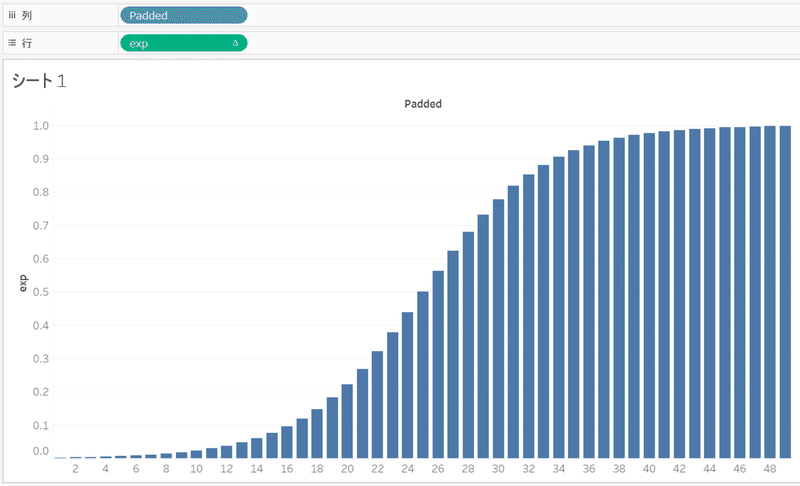
行が0~1の間に収まっていることが確認できるかと思います。
【確認】
Start counts(もしくはEnd counts)を入れると2つの数字しか出てきません。これは当然ですが、1と49しかデータセットの中に入れていないことが原因です。よって、表計算にすることでData densificationを実施しています。
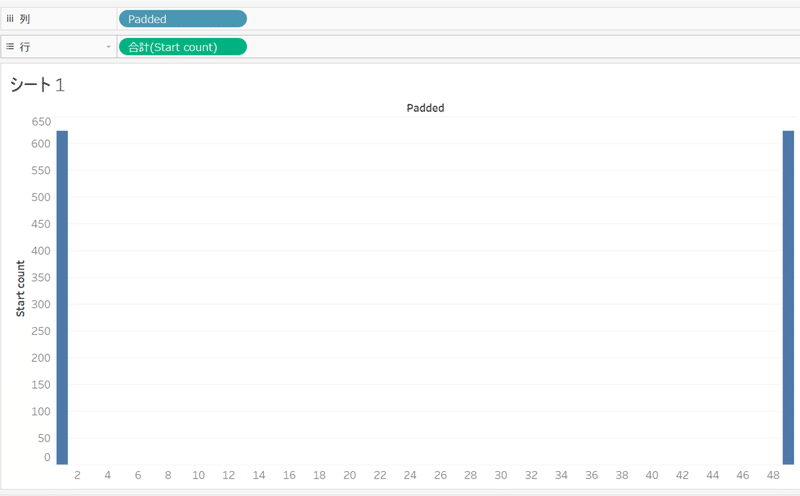
実践④Start countとEnd countのData densification
続いてメッシのプレーの集計が入っているData densificationを実施したいと思います。
計算フィールドを立ち上げて
計算フィールドタイトル:Table Start count
ZN(RUNNING_AVG(SUM([Start count])))
ここの計算フィールドの解説をしたいと思います。
ZNはもし値がなかった場合は空白を返すのではなく、0を返してねという関数になります。
Running_AVGではStart countの横に沿った表計算を平均した数値を返すことになります。
関数の解説
RUNNING_AVG(expression)
パーティション内の最初の行から現在の行までの、指定された式の累積平均を返します。
<似て非なるもの>
WINDOW_AVG(expression, [start, end])
ウィンドウ内の式の平均を返します。ウィンドウは現在の行からのオフセットにより定義されます。
参考リンク:表計算関数(画像付きなのでぜひこちらもご確認ください)
Start countとTable Start countの比較をすると下記の写真のようになります。
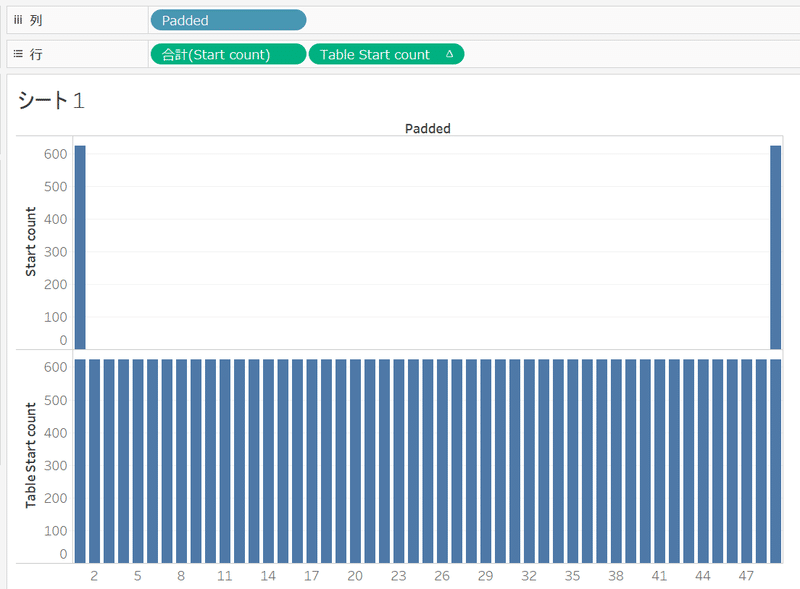
これと同様の作業をEnd countにも適用したいので、Table Start countを複製して下記のように書き換えます。
計算フィールドタイトル:Table End count
ZN(RUNNING_AVG(SUM([End count])))
これでData padding 及びData densificationが完了しました。
正直ここに至るまでに、何をやっているんだ…というのがあったと思います。ここまで問題なく理解できるのは、そもそもSigmoidや表計算にかなり精通していないと難しいです。
不明な点はぜひコメントお待ちしています!
次回はいよいよ完結編になります。
この記事が気に入ったらサポートをしてみませんか?