
【Stable Diffusion】Google Colabで横長の画を作る方法

最近、ちまたで流行っているStable Diffusion。
開発環境を作るのが面倒だったり、ゲーミングPCがなくてもGoogle Colabを使えば手頃に絵を自動生成させることができるため、ここ1週間遊んでみました。
↑前回の遊んだ感想です。
しかし、1点問題がありました。
それはデフォルトの状態だとアスペクト比1:1の画しか作れないことだ。

noteのヘッダーを作ろうとしたり、可愛いキャラクターの全身立ち絵が欲しいとなった場合、このアスペクト比を弄りたいものである。
今回、下記の記事を参考に、アスペクト比を変えて画を生成するコードを確立させたので貼っていきます。自分はプログラマーではないので、細かい仕様についての解説は避けますが、次の方法で運用すれば、アスペクト比を変更しながら簡単に絵を作らせることができます。
なお、ソースコードは下記記事を参考に作りました。
前提
下記の作業が終わっていることを前提としています。
・Hagging Faceでアクセストークンを発行している。
・Google Colabが使える状態になっている。
1.Google Colabでノートブックを作成する。

Google Colabを開き、「ノートブックを新規作成」を選択します。
2.ランタイムの設定を変更する(None→GPU)

「ランタイム」→「ランタイムのタイプを変更」を選択。
「ハードウェア アクセレータ」を「None」→「GPU」へ変更し「保存」を選択。
これを行わないと、絵を描画する際にエラーとなります。
3.アクセストークン認証

3.1.ライブラリ設定コードの入力
ライブラリのインストール用に下記のコードをプログラミングしてください。
# ライブラリのインストール
!pip install diffusers==0.2.4 transformers scipy ftfy
# アクセス・トークン設定
Access_Token="アクセストークンを挿入してください"#@param {type:"string"}
# パイプライン構築
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", use_auth_token=Access_Token)
pipe.to("cuda")
from torch import autocast
import uuid
# NSFWの制限を外す
pipe.safety_checker = lambda images, **kwargs: (images, False)
3.2.アクセストークンの挿入
Hagging Face(https://huggingface.co/settings/tokens)のユーザー管理画面でStable Diffusion用のアクセストークンをコピーしてAccess_Token=""のカッコ内にペーストしてください。
3.3.実行
完了したら「▷」で実行してください。実行中は、「▷」の周りが動作しています。動作が完了したら項番4の作業を行なってください。
4.関数の設定
4.1関数設定コードの入力
下記を入力してください。
# 便利関数を準備
from PIL import Image
from torch import autocast
import uuid
# 画像を繋げる関数
def image_grid(imgs, rows, cols):
assert len(imgs) == rows*cols
w, h = imgs[0].size
grid = Image.new('RGB', size=(cols*w, rows*h))
grid_w, grid_h = grid.size
for i, img in enumerate(imgs):
grid.paste(img, box=(i%cols*w, i//cols*h))
return grid4.2.実行
完了したら「▷」で実行してください。実行中は、「▷」の周りが動作しています。動作が完了したら項番5の作業を行なってください。
5.描画
5.1下記を入力してください。
#@title 画像生成
# 生成(高さ512,横長768)
prompt = "" #@param {type:"string"}
image = pipe(prompt, height=512, width=768, num_inference_steps=50)["sample"][0]
# 保存
sentence = prompt.replace(' ','_')
out_path = sentence+'.png'
image.save(out_path)
# 表示
from IPython.display import Image,display
display(Image(out_path))
【補足説明】
・prompt:ここにAIに描いてほしい絵の指示を記述してください。
記述方法に関しては深津貴之さんの記事が参考になります。
・height:高さ(デフォルト→512)
・weight:横幅(デフォルト→512)
アスペクト比2:3の画を描いてほしいのであればheight:512,weight:768で設定すると出力してくれます。
・num_inference_steps:推論ステップ数(デフォルト→512)
数字を上げると画が緻密になるようです。その分、時間がかかります。
5.2.num_inference_stepsによる実行時間とクオリティ検証
実際にnum_inference_stepsの値を変化すると実行時間、クオリティにどのような影響を及ぼすか検証していきましょう。
今回、プロンプトに以下の文章を記述しました。
"A photograph of a businessman do telework in the toilet,taken with Canon 5D"(Canon 5Dで撮られたトイレの中でテレワークするサラリーマンの写真)
果たしてどのような絵を描いてくれるくれるのでしょうか?
【検証1】
・num_inference_steps=50の場合
・実行時間:1分01秒

トイレに引きこもっている絵を描いてくれました。パソコンは持っていませんね。
【検証2】
・num_inference_steps=100の場合
・実行時間:1分57秒

トイレの洗面器で仕事をしている雰囲気を醸し出すことができました。
【検証3】
・num_inference_steps=150の場合
・実行時間:3分16秒

ビデを覗き込む哀愁あるサラリーマンを描いてくれました。
【検証4】
・num_inference_steps=200の場合
・実行時間:3分53秒

パソコンを持ち始めました。
【検証5】
・num_inference_steps=250の場合
・実行時間:4分53秒

250に設定すると、トイレでテレワークするサラリーマンを正確に描いてくれました。
【実行時間について】
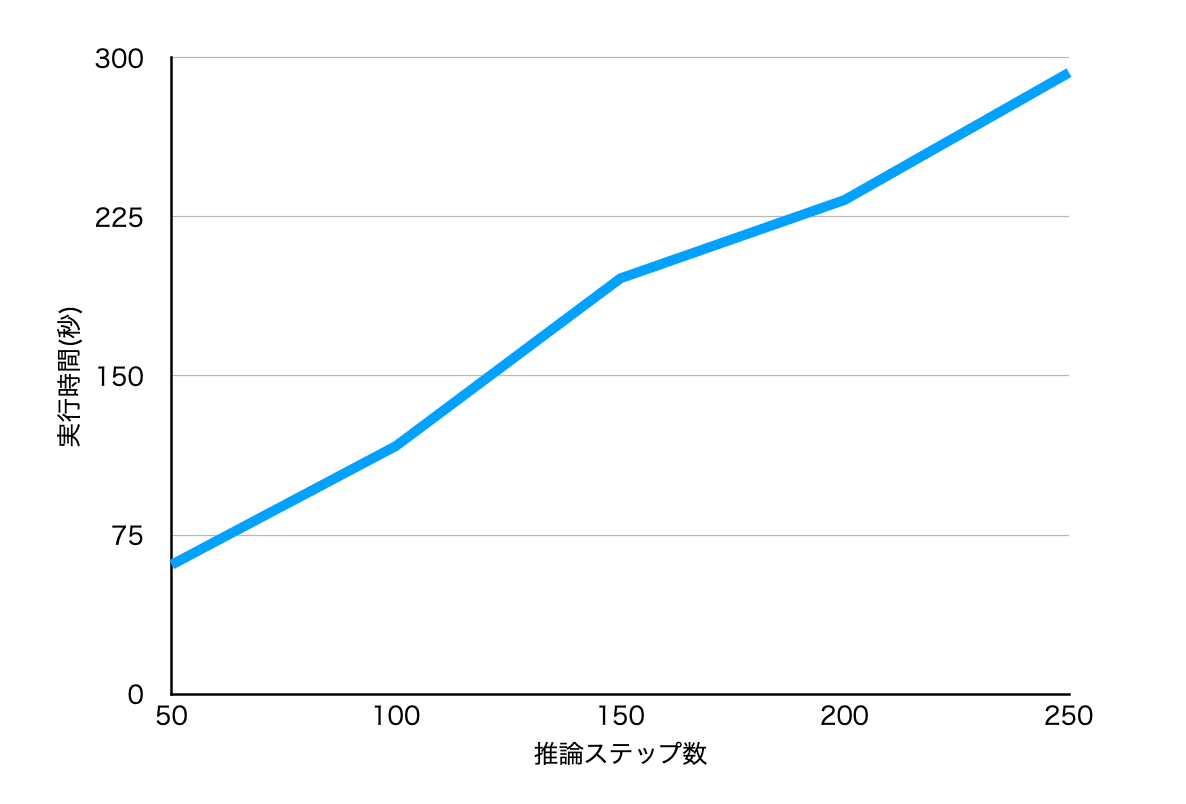
実行時間に関してグラフ化してみました。推論ステップ数50では1分程度だったが、ステップ数250にすると5分かかります。クオリティに関しては推論ステップ数50でも下記のような仕事をしているサラリーマンを生み出すことができます。ただ、150で自分の意図した構図を描画できるか検証してから250に上げたり、逆に50に下げたりすることで効率よくAIに絵を描かせることができるのではないでしょうか。

5.1動物を描かせてみる。
先日、映画館にウサギを出現させようと試みました。動物を描く場合、品種を指定するとグロテスクなものが現れます。

例えば、映画館にホーランドロップとドワーフホトを出現させようとすると、上記のような気持ち悪い絵が描画されます。
abubu nounankaさんの記事によれば、Stable Diffusionでは2つの要素を指定すると混ざってしまうようで、私の画像はホーランドロップとドワーフホトが融合したキメラとなってしまいました。

今度はホーランドロップ単体で試してみたのですが、ヨボヨボな犬のようなものが描画されました。

一旦、"Rabbit"で描画させてみたところ、我々が想像するウサギを描画してくれました。AIにとって耳垂れウサギことホーランドロップはマイナーで不慣れなようです。

そこで「映画館にいるホーランドロップ」から「映画館にいるウサギ」に抽象化して描かせてみました。大分いい感じになりました。少し冒険させてみましょう。映画館で3Dメガネを描くウサギと設定して描かせたらどうなるだろうか?その結果が下記である…

どういうことでしょうか?塚本晋也監督の『鉄男』さながらの地獄絵図となってしまいました。現実的ではない画を描かせる場合に推論ステップ数が重要となってくるそうです。試しに50から100へ上げてみましょう。

私の求めていた画を描いてくれました。可愛らしいウサギ、しかも首元にリボンをつけてオシャレをしております。このように検証しながら理想の絵を作り込んでいく。面白いですね。
5.2.具体的に指示をしよう
AIもプログラミング同様、正確な指示が求められます。例えば、「ウユニ湖に青い車を置きたい」としよう。我々は「ウユニ」と言っただけで、ウユニ湖の鏡面景色を思い浮かべる。しかしStable Diffusionにそのまま指示を出すと次のような絵を描きます。

ウユニに車を置いてくれましたが、想定していたウユニ湖には連れて行ってくれませんでした。

「ウユニ塩湖」と指示を出することで理想の絵を描いてくれます。このようにAIは人間と違ってあまり気が利かないので細かく指示を出す必要があります。
最後に…
いかがでしたでしょうか。最後にStable Diffusionで生成した画をいくつか置いておきます。プロンプトはメモってないです。AI描画のアイデアとして参考にしてみてください。




(Stable Diffusionは数式を描くのが苦手なようです)






この記事が参加している募集
映画ブログ『チェ・ブンブンのティーマ』の管理人です。よろしければサポートよろしくお願いします。謎の映画探しの資金として活用させていただきます。