
ニューラルネットワークを「行列」を使って書き換えた

この記事は、改定&整理統合されました。新版はこちら⬇です。
前回はニューロンを使ってニューラルネットワーク「Fiber」を実装しましたが、今回はこれを行列を使って書き換えました。以降は、それぞれをニューロン版、行列版と呼ぶことにします。
読み始める前に
行列版の実装を通じて分かったことを書いています。
実装に使用したプログラミング言語はPython 3です。
実行環境はGoogle Colabです。動作確認も同様です。
本稿には「ライブラリのインポート」「活性化関数」「損失関数」「動作確認」「ユーティリティ」などの多くのコードを掲載していません。
全てのコードはGitHubにあります。[Open in Colab]アイコンをクリックするとすぐにGoogle Colabで実行できます。
最低限の数式が登場します。数式の展開は行わずに展開済みの結果を利用するだけです。
準備編
チートシート
次の図は行列版を実装するためのチートシートです。これにはA4用紙1枚に「数式」「行列の形状」「データの流れ」を詰め込んであります。数式を時系列で展開しているせいでパッと見は仰々しいですが、実際には数式編で整理する通りシンプルです。

行列の形状
図では特徴量$${\!X\!}$$の形状を 6 × 5(バッチサイズ × 入力ノード数)とした上で、3つのレイヤのノード数をそれぞれ 4, 3, 2 としています。そうすると、すべての行列の形状は必然的に図に示した形状に決まります。Fiberでモデルを構築する場合は、それぞれの値を次のように指定します。
model = Model(5, eta=0.001) # 入力ノード数 = 5
model.add(4, tanh, tanh_der) # レイヤ1のノード数 = 4
model.add(3, tanh, tanh_der) # レイヤ2のノード数 = 3
model.add(2, softmax) # レイヤ3のノード数 = 2
model.set_metrics(mul_xentropy, mul_accuracy)
model.fit(X, T, batch_size=6) # バッチサイズ = 6行列同士の演算で意識すること
ニューラルネットワークの実装において、行列同士の「積」についてはドット積(内積)とアダマール積(外積)の2種類を使います。ドット積を計算する場合は$${X\cdot W}$$と$${W \cdot X}$$のように前後の項を入れ替えることが出来ません。さらに、逆伝播では行列同士のドット積を可能にするために一方の行列を転置します。とりあえずこの辺は深追いせずに、演算の形すらも行列の形状から必然的に決まるものだと考えることにしました。
数式編
チートシートの数式を整理します。式番号はコードのコメントにも記入してあるので数式の実装を確認するのは簡単です。
添字の説明
$$
\def\arraystretch{1.5}
\begin{array}{c:ll}
添字&意味&表記例 \\
\hline \\[-15pt]
l & レイヤ番号 \\
k & レイヤ数 & (\,l\,=1,2,\ldots,\,k\,) \\
r & 行列の行番号 \\
m & バッチサイズ & \sum_{r=1}^{m} \\
\end{array} \\
$$
出力値の計算
$$
\tag{1.1}
U^{(l)}=X^{(l)}\cdot W^{(l)}+\vec{b}^{(l)}
$$
$$
\tag{1.2}
Y^{(l)}=f^{(l)}(U^{(l)})
$$
誤差の計算
$$
\tag{1.3}
Δ^{(l)}=Y-T
$$
$$
(l=k)
$$
$$
\tag{1.4}
Δ^{(l)}=X_{grad}^{(l+1)}\odot f'^{(l)}(U^{(l)})
$$
$$
(l\lt k)
$$
勾配の計算
$$
\tag{1.5}
X_{grad}^{(l)}=Δ^{(l)}\cdot W^{(l)\mathrm{T}}
$$
$$
\tag{1.6}
W_{grad}^{(l)}=X^{(l)\mathrm{T}}\cdot Δ^{(l)}
$$
$$
\tag{1.7}
\vec{b}_{grad}^{(l)}=\displaystyle\sum_{r=1}^{m}Δ^{(l)}[r,:]
$$
パラメータの更新
$$
\tag{1.8}
W^{(l)}:=W^{(l)}-η\,W_{grad}^{(l)}
$$
$$
\tag{1.9}
\vec{b}^{(l)}:= \vec{b}^{(l)}-η\,\vec{b}_{grad}^{(l)}
$$
実装編
ニューロン版は4つのクラス(ニューロン、レイヤ、コーテクス、モデル)で構成しましたが、行列版は数は同じ4つですがニューロンが無くなってメトリクスを追加しました。メトリクスは評価指標を管理します。ということで行列版はレイヤ、コーテクス、メトリクス、モデルの4つのクラスで構成します。ニューロン版に比べてコードは30ステップ以上削減されていますが、それ以上に可読性がアップしていると思います。
主な変更点
行列版では訓練データと検証データの両方について損失と精度を測定するようにしました。演習編ではこれらの評価指標を4本の折れ線グラフで表示します。過学習が起こり始めると検証データの損失が減少から上昇に転じることで分かります(これほど単純な話ではないと思いますが手掛かりの1つとして利用できるかと思います)。
行列版は処理速度が速すぎて進行状況を表示する意味がなくなったのでverbose機能を削除しました。Fiberで処理速度が気になるほど大きなモデルを構築をすることは無いだろう、というのも理由の1つです。
Fiber(行列版)
#--------------------------------------------------
# レイヤ(パラメータを管理)
#--------------------------------------------------
class Layer:
def __init__(self, rows, cols, funcs):
(self._fact_, self._fder_, self._fini_) = funcs
core = self._fini_(rows+1, cols)
self.W = core[0:rows] # 重み
self.b = core[-1] # バイアス
def output(self, X): # 出力値を計算
self.X = X
self.U = X @ self.W + self.b # 式 (1.1)
return self._fact_(self.U) # 式 (1.2)
def calc_delta(self, X_grad): # 誤差を計算
return X_grad * self._fder_(self.U) # 式 (1.4)
def calc_grad(self, delta): # 勾配を計算
self.W_grad = self.X.T @ delta # 式 (1.6)
self.b_grad = np.sum(delta, axis=0) # 式 (1.7)
return delta @ self.W.T # 式 (1.5)
def update(self, eta): # パラメータを更新
self.W -= eta * self.W_grad # 式 (1.8)
self.b -= eta * self.b_grad # 式 (1.9)
#--------------------------------------------------
# コーテクス(レイヤを管理)
#--------------------------------------------------
class Cortex:
def __init__(self, cols, eta):
self.layers = [] # レイヤの一覧
self.rows = cols # 最初のレイヤの行数を確定
self.eta = eta # 学習率
def add(self, cols, funcs): # レイヤを追加
layer = Layer(self.rows, cols, funcs)
self.layers.append(layer)
self.rows = cols # 次のレイヤの行数を確定
def forward(self, X): # 順伝播
for layer in self.layers:
X = layer.output(X)
return X
def backward(self, delta): # 逆伝播
layers = list(reversed(self.layers))
X_grad = layers[0].calc_grad(delta)
for layer in layers[1:]:
delta = layer.calc_delta(X_grad)
X_grad = layer.calc_grad(delta)
def batch(self, X, T): # バッチ
Y = self.forward(X)
delta = Y - T # 式 (1.3)
self.backward(delta)
def update(self): # パラメータを更新
for layer in self.layers:
layer.update(self.eta)
#--------------------------------------------------
# メトリクス(評価指標を管理)
#--------------------------------------------------
class Metrics:
def __init__(self, flos, feva):
self.train = Object() # 測定結果(訓練データ)
self.valid = Object() # 測定結果(検証データ)
self.train.loss = []
self.train.accu = []
self.valid.loss = []
self.valid.accu = []
self._flos_ = flos # 損失関数
self._feva_ = feva # 評価関数
def update(self, dst, Y, T): # 測定結果を更新
dst.loss.append(self._flos_(Y, T))
dst.accu.append(self._feva_(Y, T))
#--------------------------------------------------
# モデル
#--------------------------------------------------
class Model:
def __init__(self, cols, eta):
self.cortex = Cortex(cols, eta)
@staticmethod
def idx_mini(total_size, batch_size): # ミニバッチ用のインデックスを作成
whole = np.random.permutation(total_size)
idx_slice = range(0, total_size, batch_size)
return [whole[i:i+batch_size] for i in idx_slice]
def add(self, cols, fact, fder=lambda x:None, fini=glorot_uniform): # レイヤを追加
funcs = (fact, fder, fini)
self.cortex.add(cols, funcs)
def set_metrics(self, flos, feva): # 評価指標を設定
self.metrics = Metrics(flos, feva)
def measure(self, X_train, T_train, ds_valid):
Y = self.cortex.forward(X_train) # 訓練データを測定
self.metrics.update(self.metrics.train, Y, T_train)
if ds_valid is not None:
Y = self.cortex.forward(ds_valid[0]) # 検証データを測定
self.metrics.update(self.metrics.valid, Y, ds_valid[1])
def fit(self, X_train, T_train, ds_valid=None, epochs=1, batch_size=1): # 最適化
for epo in range(epochs):
self.measure(X_train, T_train, ds_valid)
whole = self.idx_mini(len(X_train), batch_size)
for mini in whole:
self.cortex.batch(X_train[mini], T_train[mini])
self.cortex.update()
return self.metrics
def predict(self, X): # 予測
return self.cortex.forward(X)演習編
演習のお題目は次の2つです。
【演習1】二値分類―ワインの特徴から品種を推測する
【演習2】多値分類―アヤメの特徴から品種を推測する
どちらのお題目についてもFiberとKerasの両方を使っています。Kerasについては設定をFiberに合わせてあるので、本来のKerasの力を発揮できていないと思います。
演習で使用するデータセットを取得
def drop_rows(ds, colm, cond): # 条件に一致する行を削除
ds.frame = ds.frame[cond(ds.frame[colm])]
ds.data = ds.frame[ds.feature_names]
ds.target = ds.frame[colm]
return ds
print('▣ ワインの特徴')
wine = load_wine(as_frame=True)
wine = drop_rows(wine, 'target', lambda colm: colm < 2) # 品種を2種類(0と1)に限定する
display(wine.frame.head())
print('\n▣ アヤメの特徴')
iris = load_iris(as_frame=True)
display(iris.frame.head())
【演習1】二値分類―ワインの特徴から品種を推測する
#--------------------------------------------------
# 初期設定(FiberとKerasで共通)
#--------------------------------------------------
(X_train, X_test, T_train, T_test) = preproc_bin(wine)
eta = 0.01 # 学習率
epochs = 50
batch_size = 5
limit = 10 # 予測で使うテストセットを10件に制限
#--------------------------------------------------
# ワインの品種を推測(Fiber)
#--------------------------------------------------
print('▣ Fiber')
model = Model(13, eta=eta)
model.add(8, tanh, tanh_der)
model.add(1, sigmoid)
model.set_metrics(bin_xentropy, bin_accuracy)
fit = model.fit(X_train, T_train,
ds_valid=(X_test, T_test),
epochs=epochs, batch_size=batch_size)
Y_test = model.predict(X_test[:limit])
show_progress(fit)
show_summary_bin(Y_test, T_test[:limit])
#--------------------------------------------------
# ワインの品種を推測(Keras)
#--------------------------------------------------
print('\n▣ Keras')
model = keras.Sequential()
model.add(Dense(8, 'tanh', input_shape=(13,)))
model.add(Dense(1, 'sigmoid'))
model.compile(
optimizer=keras.optimizers.SGD(learning_rate=eta),
loss='binary_crossentropy',
metrics=['accuracy'])
fit = model.fit(X_train, T_train,
validation_data=(X_test, T_test),
epochs=epochs, batch_size=batch_size, verbose=0)
fit = adapt_metrics(fit)
Y_test = model.predict(X_test[:limit], verbose=0)
show_progress(fit)
show_summary_bin(Y_test, T_test[:limit])▣ Fiber


▣ Keras


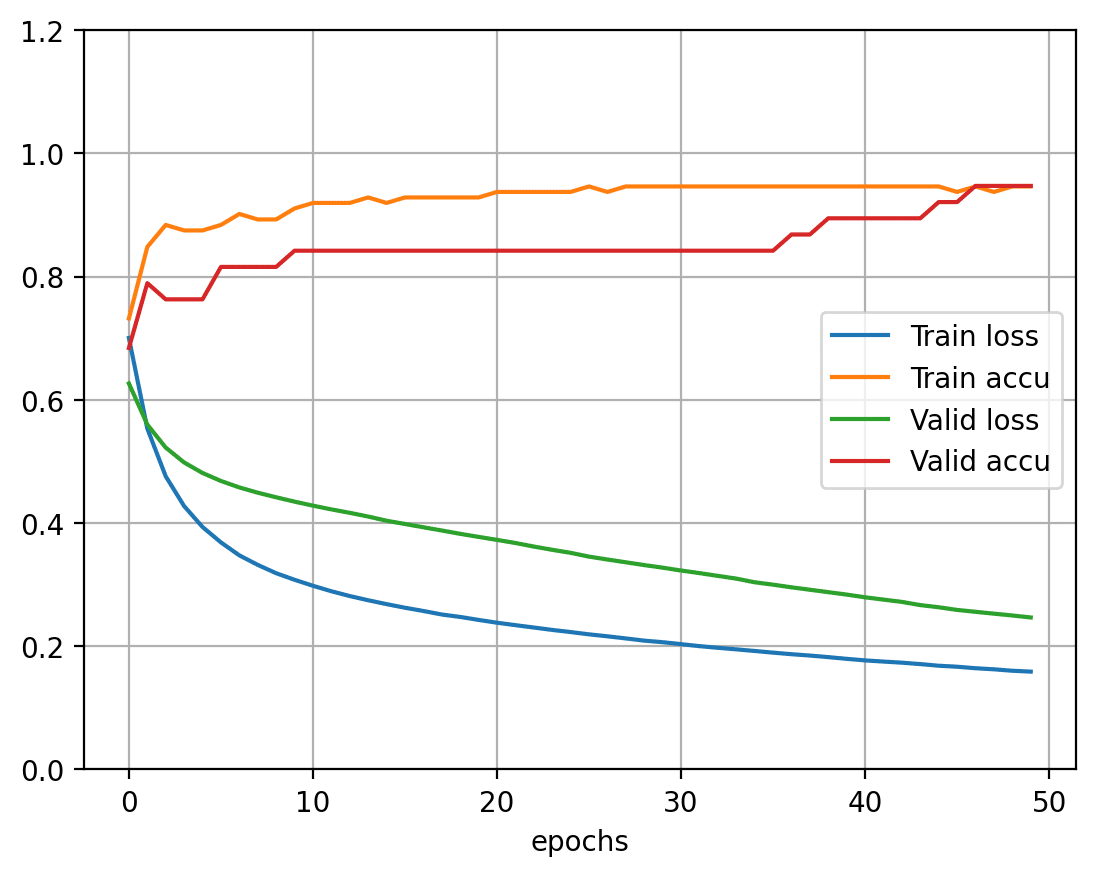
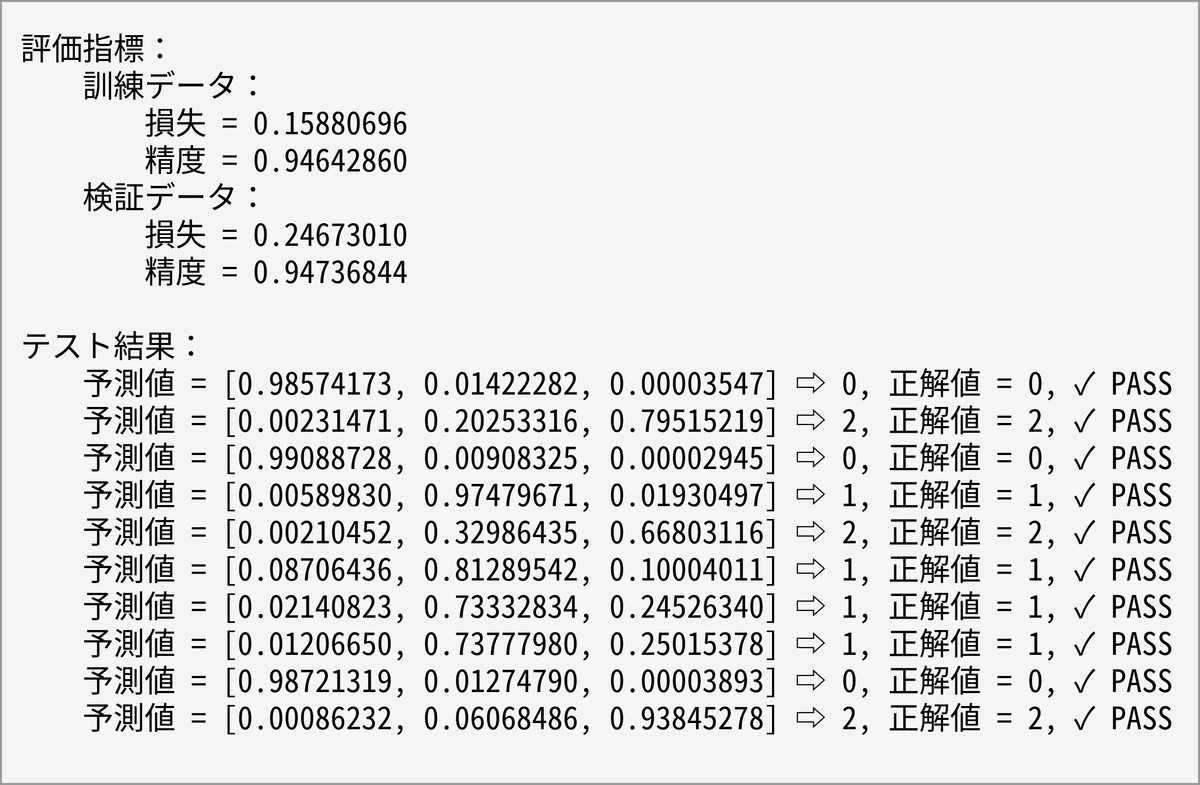
【演習2】多値分類―アヤメの特徴から品種を推測する
#--------------------------------------------------
# 初期設定(FiberとKerasで共通)
#--------------------------------------------------
(X_train, X_test, T_train, T_test) = preproc_mul(iris)
eta = 0.01 # 学習率
epochs = 50
batch_size = 5
limit = 10 # 予測で使うテストセットを10件に制限
#--------------------------------------------------
# アヤメの品種を推測(Fiber)
#--------------------------------------------------
print('▣ Fiber')
model = Model(4, eta=eta)
model.add(32, tanh, tanh_der)
model.add(3, softmax)
model.set_metrics(mul_xentropy, mul_accuracy)
fit = model.fit(X_train, T_train,
ds_valid=(X_test, T_test),
epochs=epochs, batch_size=batch_size)
Y_test = model.predict(X_test[:limit])
show_progress(fit)
show_summary_mul(Y_test, T_test[:limit])
#--------------------------------------------------
# アヤメの品種を推測(Keras)
#--------------------------------------------------
print('\n▣ Keras')
model = keras.Sequential()
model.add(Dense(32, 'tanh', input_shape=(4,)))
model.add(Dense(3, 'softmax'))
model.compile(
optimizer=keras.optimizers.SGD(learning_rate=eta),
loss='categorical_crossentropy',
metrics=['accuracy'])
fit = model.fit(X_train, T_train,
validation_data=(X_test, T_test),
epochs=epochs, batch_size=batch_size, verbose=0)
fit = adapt_metrics(fit)
Y_test = model.predict(X_test[:limit], verbose=0)
show_progress(fit)
show_summary_mul(Y_test, T_test[:limit])▣ Fiber


▣ Keras
おわりに
行列版を実装することでニューロン版を実装したあとの「物足りない感」を解消することが出来ました。高速で見通しの良いコードが手に入ったこと、そして行列の演算に向き合ったことも収穫です。
更新履歴
2023-08-16、初版
2023-08-23、評価指標を管理するためのクラスとしてメトリクスを追加。損失関数と評価関数をメトリクス対応に書き換え。
2023-09-14、マガジン内の表記を統一 ①ベクトル版⇨ニューロン版 ②レイヤ数($${n}$$⇨$${k}$$)③レイヤ番号は右肩に($${W_{i}^{(grad)}}$$ ⇨ $${W_{grad}^{(l)}}$$)④行列は大文字に($${δ}$$⇨$${Δ}$$)⑤アダマール積($${\circ}$$⇨$${\odot}$$)⑥縦軸の総和($${\sum_{r=1}^{m}Δ^{(l)}[r]}$$⇨$${\sum_{r=1}^{m}Δ^{(l)}[r,:]}$$)
この記事が気に入ったらサポートをしてみませんか?