
リアルデバイスでProject Bonsaiを動かしてみた

こんにちは、アバナード関西オフィスの小林です。
今!!
盆栽が!!
アツイ!!!

ということで、大注目のProject BonsaiをRaspberry Piに載せて走り回らせてみたいと思います!
走り回らせて??
そう、今回はラジコン × Raspberry Pi × Bonsaiで障害物にぶつからないよう
自律的に走るラジコンを作ってみたいと思います。
内容が盛りだくさんになるので、2回に分け今回は概要部分をご紹介します。
達成させたい目標
1.自動で自由に走り回る
2.壁等の障害物に近づくとよける or バックする
3.特定の画像を判断させ、特別な挙動をおこなう
なお、今回は障害物との距離を測定するためのセンサーや、画像認識を行うためのカメラが必要となりますので、ベースとしてPiCar-Xを使用しております。

そもそもProject Bonsaiとは?
Microsoftの新しいAIの一種であり、現時点ではまた限定プレビュー版の公開となっていますが、機械教示と強化学習を使用してインテリジェントな産業用制御システムなどに活用することができます。
Bonsaiの1つのキーワードどとして、今まであまり耳にした事がない「機械教示」というものがでてきます。
(小林だけかもしれませんが…)
これは、機械学習を補完するための手段として用いられ、私のようにAIのスペシャリストでない人でも比較的容易にAIを使用する事ができるようになります。
一般的なAIは大量のデータやテキストをインプットすることで、関連性を学んだり、パターンを発見するといった使い方です。
しかし、Bonsaiはゴールを設定し、シミュレーター上でゴールに達成できるようトレーニングさせることにより、大量のデータを用意する必要がなく、自律的に学習を進めることができます。
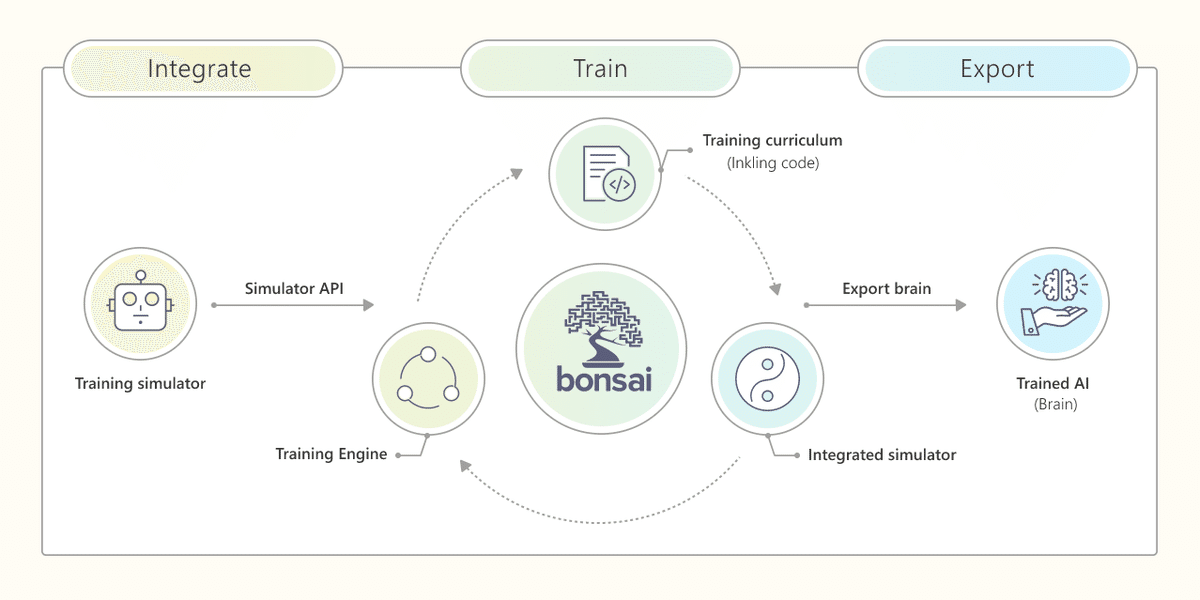
Bonsaiの特徴をまとめると、以下の3点です。
Ⅰ.ローコードのAI開発プラットフォーム
Ⅱ.深層強化学習とMachine Teachingを組み合わせる最先端の技術を使用
Ⅲ.データサイエンティストの関与は最低限で済む
Custom Visionの使用
今回、画像を判断するりあたり、Custom Visionを使用しています。これはAzure Cognitive Servicesに属するサービスで一言で表現すると画像認識に特化したサービスです。
また、Custom Visionでは「画像分類」と「物体検出」の2種類のAIモデルを作成することができますが、今回は後者の「物体検出」として利用しています。
画像認識と書くと「小難しそう」や、Bonsaiの項目であった通り大量のデータで学習させる必要があると思われるかもしれませんが、ご安心ください。
Custom Visionは学習させる画像とタグを同時にインプットさせるのですが、10枚程度のサンプルがあれば十分な精度が得られます(対象の複雑度にもよります)。
ですので、Custom VisionもまたProject BonsaiのようにAIのプロフェッショナルでなくても容易に高性能なAIモデルを作成することができるサービスになっています。
システム構成図
Bonsai Carの構成図をご紹介します。

今回、Brain(学習済みの頭脳)を直接RaspberryPiのDocker上にDeployしましたが、BrainをContainer Registry上にDeployし、Azure Function等でAPIを公開し外部から叩いて貰うほうが、より汎用性とセキュリティ性が高くなるかと思います。
では、なぜ直接RaspberryPiのDocker上にDeployしたかといいますと、Webを介すレイテンシの排除、APIを作成するのが面倒工数を削減するためです。
いかがでしょうか?
ぼんやりとでも、全体像が見えてきましたのではないでしょうか。
次回はBonsai部分の実装やトレーニングについて、もう少し掘り下げた内容と「達成させたい目標」の3の内容に触れたいと思います。
最後まで読んでいただき、ありがとうございました!
アバナード関西 小林 直樹
naoki.kobayashi(@)avanade.com