
「GA4+機械学習」で何ができるのか?
この記事の目的
本記事のテーマはGA4と「機械学習」です。本記事での「機械学習」の定義は、一般社団法人 日本ディープラーニング協会監修『深層学習教科書 ディープラーニング G検定(ジェネラリスト) 公式テキスト』 (翔泳社、2018年)の下記の定義に従います。
機械学習とは、人工知能のプログラム自身が学習する仕組みです。コンピュータは与えられたサンプルデータを通してデータに潜むパターンを学習します。
一般社団法人 日本ディープラーニング協会監修『深層学習教科書 ディープラーニング G検定(ジェネラリスト) 公式テキスト』 (翔泳社、2018年) P49
2020年の後半にGA4が登場したことにより、ウェブ解析・改善担当者の間に「機械学習」を活用する人が増えています。たとえば、「ウェブへの集客の戦術を練るのは得意だけど、集客したユーザーのLTV(Life Time Value)最大化する戦術を練るのは苦手」という人がいると思います。そんな人が、「教師あり学習」の手法を活用すれば、「集客したユーザーのLTV最大化」も得意とすることができます。
「教師あり学習」は機械学習が対象とする課題の種類の一つです。「与えられたデータ(=入力)を元に、そのデータがどんなパターン(=出力)になるのかを識別・予測する」ものとなります。たとえば、過去の売上から、将来の売上を予測するというのも「教師あり学習」です。
*(「教師あり学習」説明の 参考文献:一般社団法人 日本ディープラーニング協会監修『深層学習教科書 ディープラーニング G検定(ジェネラリスト) 公式テキスト』 (翔泳社、2018年) P94-95)
「教師あり学習」の手法を活用すれば、「LTV 最大化」という観点に合致するセグメントのユーザーを特定して、集中的にコストを掛けてアプローチすることができます。
更に機械学習の「レコメンド」機能を使えば、LTVが大きくなる可能性が高いセグメントのユーザーに、そのセグメントのユーザーが好む訴求をぶつけることができます。
これだけでも、ウェブ解析・改善担当者の間に機械学習を活用する人が増えている理由が理解できると思いますが、機械学習には、それ以外にも魅力があります。
それは、「省力化、効率化、うまくいけば自動化」という魅力です。
機械学習を用いることで、ウェブの解析から改善施策の実装までを一気通貫で「省力化、効率化、うまくいけば自動化」できるようになります。
この記事の目的は、上記のように、「機械学習が、ウェブ解析・改善担当者をどう助けるか」を解説することにあります。
機械学習が、ウェブ解析・改善担当者をどう助けるか
機械学習は、ウェブ解析・改善担当者に
1)勘に頼らないデータ・ドリブンなマーケティング
2)業務の効率化・省力化
という2つのベネフィットをもたらします。
ウェブ解析・改善に機械学習を活用する上で大切なこと
今年から機械学習を活用したウェブマーケティングに取り組もうとしているウェブ解析・改善担当者は、以下の2つのことを行う必要があります。
1. 機械学習の概要を理解する(ここに時間を掛けすぎず、次の「2」に進むことが重要)
2. 業務のほんの一部でもいいので、実際に機械学習を活用して仮説を立てて施策を実装し、効果を計測する
弊社でも、昨年から上記の1, 2の案件のお手伝いを始めています。
2021年はまだ、機械学習を使ったウェブ解析・改善の「試行錯誤期」ですが、2022年からは「本格稼働期」に入ると考えられます。今のうちに、できることから手を付けて、トライ&エラーを重ねておく必要があります。
なお、上記で「教師あり学習」について触れましたが、ECサイト、人材サイト(転職など)、不動産サイトなどの情報量が多いウェブサイトでは、「教師なし学習」の活用も有益です。
「教師なし学習」とは
「教師あり学習」は入力と出力がセットとなったデータを用いますが、「教師なし学習」で用いるデータには出力がありません。つまり、「教師あり学習」「教師なし学習」の「教師」とは出力データのことを指します。
では「教師なし学習」ではいったい何を学習するのかというと、「データ(=入力データ)」そのものが持つ構造・特徴が対象となります。たとえば、
「ECサイトの売上データから、どういったユーザー層があるのかを認識したい」
「ユーザーが会員登録時に入力した入力データの各項目間にある関係性を把握したい」
といった時に、「教師なし学習」を用いることになります。
*(「教師なし学習」説明の 参考文献:一般社団法人 日本ディープラーニング協会監修『深層学習教科書 ディープラーニング G検定(ジェネラリスト) 公式テキスト』 (翔泳社、2018年) P95-96)
レコメンデーション システム
機械学習がビジネスの現場に入って来たのは、2010年から始まった「第3次AIブーム」の時からで、この時代は「機械学習・特徴表現学習の時代」と呼ばれます。知識を定義する要素(「特徴量」と呼ばれる対象を認識する際に注目すべき特徴を定量的に定義するもの)を人工知能が自ら学習するディープラーニング(深層学習)が登場したことが「第3次AIブーム」のトリガーです。
GA4登場以前のUAの時代から、既にウェブ解析に機械学習は導入されていました。たとえば、Googleの公式ドキュメント「TensorFlow でのレコメンデーション: Google アナリティクスのデータに適用する」においては、Google Cloud Platform(GCP)で TensorFlow(注1) と AI Platform(注2) を使用して、機械学習(ML)レコメンデーション システムを実装する方法が説明されています。
(注1)TensorFlow は、機械学習向けに開発されたエンドツーエンドのオープンソース プラットフォームです。
出典:https://www.tensorflow.org/?hl=ja
(注2)AI Platformは、Googleが提供する、データ サイエンスと機械学習向けのフルマネージドのエンドツーエンド プラットフォームです。
出典:https://cloud.google.com/ai-platform?hl=ja
GA4登場以降の流れ
GA4の登場に直接関連付けられているわけではありませんが、GA4の登場と、ほぼ時を同じくして昨年11月に飯塚修平さんの『ウェブ最適化ではじめる機械学習―A/Bテスト、メタヒューリスティクス、バンディットアルゴリズムからベイズ最適化まで』(2020年、オライリージャパン)という書籍が出版されました。まさにこの本の出版が、「新しい時代=ウェブ解析の世界への機械学習の本格導入時代」の幕開けとして位置づけられると筆者は考えています。
マーケティングやウェブ解析の世界で機械学習の活用が進むことは、既に以下のような記事やBlogでも紹介されています。
なぜ機械学習をマーケティングに使う企業が増えているのか│kotodori | コトドリ
Google アナリティクス 4プロパティ 機械学習モデルを活用した予測機能とプライバシー重視のデータ収集(アユダンテ株式会社)
「Googleアナリティクス4」活用で身近になる機械学習 (1/3)|ネット通販情報満載の無料Webマガジン「ECzine(イーシージン)」
2021年、GA4によってWeb解析がどう変わるのか | 株式会社プリンシプル
ウェブ解析への機械学習の浸透は、大きく分けると、下記の2つの流れで進んでいくと考えられます。
(1) GA4のUI上で利用可能な機械学習
(2) GA4のデータをBigQueryに入れた後での機械学習
ここからは、それぞれについて見ていきます。
GA4のUI上で利用可能な機械学習
この章では、GA4上で完結できるサービスについてご紹介します。ここで紹介するサービスに関してはGA4のデータをBigQueryに入れる必要はありません。
GA4では、実装したイベントを元にGoogleの機械学習モデルで解析を行う「予測指標」が導入されました。
「予測指標」についての公式ヘルプはこちらです。
予測指標 - アナリティクス ヘルプ
作成可能な「予測指標」
GA4の「予測指標」を使用すると、イベントデータを収集するだけで、ウェブサイトのユーザーについて、より詳しく知ることができます。
具体的には、以下の指標が利用可能となります。
■ 購入の可能性
過去 28 日間に操作を行ったユーザーによって、今後 7 日間以内に特定のコンバージョン イベントが記録される可能性です。2021年1月時点で、
・purchase イベント
・ecommerce_purchase イベント
・in_app_purchase イベント
がサポートされています。
上記のモデルは、直近 28 日間のデータでトレーニングされます。
■ 離脱の可能性
過去 7 日間以内にアプリやサイトで操作を行ったユーザーが、今後 7 日間以内に操作を行わない可能性です。
このモデルは、直近 28 日間のデータでトレーニングされます。
■ 収益予測
過去 28 日間に操作を行ったユーザーが今後 28 日間に達成する購入型コンバージョンによって得られる総収益の予測です。
上記の「購入の可能性」「離脱の可能性」「収益予測」の予測モデルを正常にトレーニングするには、幾つかの条件を満たしている必要があります。詳しくは、先述の「予測指標 - アナリティクス ヘルプ」をご参照ください。なお、「オーディエンス作成ツール」の「オーディエンス テンプレート」の候補内にある [予測可能] セクションで、各予測の要件ステータスを確認できます。
「予測指標」をどう使うか?(1) オーディエンス作成ツール
予測指標を使用して、「オーディエンス作成ツール」で「予測オーディエンス」を作成できます。
オーディエンスを作成する目的は?
アナリティクス アカウントを Google 広告にリンクすると、オーディエンスが Google 広告の共有ライブラリに表示され、広告キャンペーンで使用できるようになります。ここでは、既存のユーザーや以前のユーザーへのリマーケティングを設定したり、類似オーディエンスを作成して新しいユーザーを開拓したりすることが可能です。(詳しくは「オーディエンスの作成、編集、アーカイブ - アナリティクスヘルプ」を参照。)
【オーディエンス作成における「予測指標」の利用手順】
左側のメニューで [オーディエンス] をクリック。
↓
[新しいオーディエンス] をクリック。
↓
[オーディエンスの候補] で [予測可能] をクリック。
※使用可能となる条件を満たしていなければ「予測可能」の項目名は表示されない。
↓
予測モデルの要件を満たしている予測オーディエンスの候補は、[利用可能] とラベル付けされている。利用可能なテンプレートのいずれかをクリックする。
「予測指標」をどう使うか?(2) 分析
分析の [購入の可能性] と [離脱の可能性] は、ユーザーのライフタイムの手法で使用できます。
【「分析」における「予測指標」の利用手順】
左側のメニューで [分析] をクリック。
↓
[ユーザーのライフタイム] をクリック。(初回は「テンプレート ギャラリー」から作成)
↓
「指標 +」をクリック
↓

「予測指標」をクリック
↓
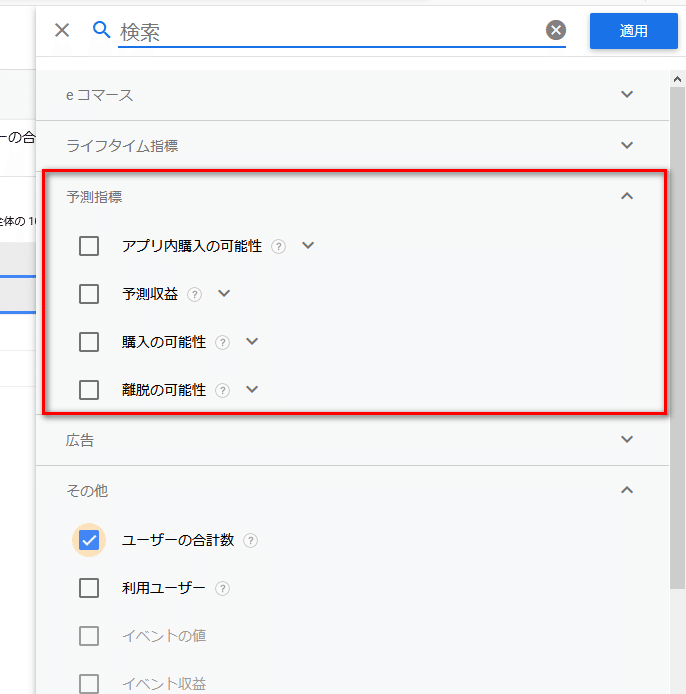
「予測指標」が選択できる。
GA4のデータをBigQueryに入れた後での機械学習
GA4登場で、なぜ機械学習が身近になったのか
UAからGA4への移行で、大きく変わるのは次の3点です。
(1) 「セッション ベース」から「ユーザー ベース」への計測の移行
(2) ほとんどのユーザーのアクションを「イベント ベース」で計測するように移行
(3) GA4が有料版でなくても(「360」でなくても)、「BigQuery Export」ができる(UAの場合は「360」でないと、「BigQuery Export」ができない。)
なお、「GA4」の「360」については、2021年1月現在、ベータテストが行われています。詳しくは、こちらをご覧ください。
Google アナリティクス 360 ベータ版(Google アナリティクス 4 プロパティ)(https://support.google.com/analytics/answer/9826983)
上記(1)と(2)により、UAよりもユーザーを「カスタマージャーニーマップ 上」でとらえやすくなったはずです。そして(3)で、GAのデータをBigQuery MLで分析しやすくなりました。
BigQuery ML とは
BigQuery ML を使用すると、BigQuery で標準 SQL クエリを使用して、機械学習モデルを作成し実行できます。BigQuery ML では、既存の SQL ツールやスキルを活用できるので、誰でも簡単に機械学習を利用できます。BigQuery ML では、データを移動する必要がないため、開発スピードを向上させることができます。
(中略)
大規模なデータセットで機械学習を行うには、ML フレームワークに対する高度なプログラミング技術と知識が必要になります。このため、どの組織でもソリューションの開発はごく限られたメンバーで行われています。データをよく理解していても、プログラミングの経験が少なく、機械学習に詳しくないデータ アナリストは除外されています。
BigQuery ML では、既存の SQL ツールやスキルで機械学習を使用できるため、データ アナリストも機械学習を簡単に利用できます。アナリストは、BigQuery ML を使用して BigQuery に ML モデルを構築し、評価できます。スプレッドシートや他のアプリケーションに少量のデータをエクスポートする必要はありません。データ サイエンス チームのリソースを待つ必要もありません。
出典:BigQuery ML とは:https://cloud.google.com/bigquery-ml/docs/introduction?hl=ja)
BigQuery ML の料金はこちらです。
https://cloud.google.com/bigquery-ml/pricing
BigQuery ML は次のモデルをサポートしています。
(1) 線形回帰(予測)
統計でも用いられる手法です。データの分布があった時に、そのデータに最も当てはまる直線を考えます。たとえば、横軸が身長、縦軸が体重だとします。既存の身長・体重の組み合わせから回帰直線を求めることによって、新しく身長のデータが来た際に、その直線の値を返すことで、体重を予測することができます。
*(「線形回帰」説明の 参考文献:一般社団法人 日本ディープラーニング協会監修『深層学習教科書 ディープラーニング G検定(ジェネラリスト) 公式テキスト』 (翔泳社、2018年) P96)
(2) 2 項ロジスティック回帰(分類)
線形回帰は回帰問題(注)に用いる手法でしたが、その分類問題と言えるものが、「ロジスティック回帰」です。名前に「回帰」とついていますが、回帰問題ではなく、分類問題に用いる手法です。ロジスティック回帰ではシグモイド関数という関数をモデルの出力に用います。
(注)「回帰問題」とは数値を予想する問題のことです。学習時に「入力データ」と「出力データ」から対応する規則を学習し、未知の「入力データ」に対して適切な「出力データ」を得る手法です。
任意の値を0から1の間に写像するシグモイド関数を用いることによって、与えられたデータが正例(+1)になるか、負例(0)になるかの確率がまります。出力の値が0.5以上ならば正例、0.5未満ならば負例と設定しておくことで、データを2種類に分類できるようになります。
*(「ロジスティック回帰」説明の 参考文献:一般社団法人 日本ディープラーニング協会監修『深層学習教科書 ディープラーニング G検定(ジェネラリスト) 公式テキスト』 (翔泳社、2018年) P97-98)
BigQuery ML でサポートされるモデルは、上記以外にも、下記の8つがあります。詳しくは、公式サポートページ(https://cloud.google.com/bigquery-ml/docs/introduction?hl=ja)をご参照ください。
(3) 多項ロジスティック回帰(分類)
(4) K 平均法クラスタリング(データ セグメンテーション)
(5) 行列分解(商品のレコメンデーション システムの作成)
(6) 時系列(時系列予測)
(7) ブーストツリー(XGBoostベースの分類モデルと回帰モデルの作成)
(8) ディープ ニューラル ネットワーク(DNN)
(9) AutoML Tables
(10) TensorFlow モデルのインポート
機械学習のウェブ解析への活用事例
最後に、弊社では昨年から機械学習をウェブ解析・改善に活用していますので、そのお話をさせていただきたいと思います。
機械学習は原則として、サンプルデータの数が多ければ多い程、望ましい学習結果が得られます。ということは、機械学習に適しているウェブサイトとして取り組みやすいのは、大規模ECサイト、大規模人材系サイト(転職など)、大規模不動産サイト(マンション賃貸など)、ユーザー数が多いゲームアプリなど、ということになると考えられます。
更に「機械学習の真価が発揮されるのは?」という視点で考えると、LTV重視の業種だと思われます。LTVの予測の精度が高ければ、広告予算の配分、サイト改修(アプリ改修)に掛けられるコストも計算しやすくなるはずです。
機械学習のウェブ解析への活用事例 分かりやすい取り組み方
まず、貴社にとって、「ありがたいユーザー」像を定量的に設定します。このユーザー像は、PDCAサイクルを回していく中で、当然変更の可能性が出てきます。「いったん決める」ということです。ここからはECサイトを例に考えてみましょう。
「ありがたいユーザー」像 設定例:
会員登録後2か月以内に5,000円以上課金してくれる。
さて、上記の「ありがたいユーザー」がウェブサイト内で「どんなコンテンツを見ているか」だけであれば、従来のUAのレポート画面があれば十分なので、機械学習の出番は無いかも知れません。
「流入元毎に」とか「新規、再訪を分けて」という与件であっても、データポータルの「コントロール」でプルダウンメニューを作れば、効率的なレポーティングができるので、まだ機械学習の出番は無いかも知れません。
しかし、以下のような与件に対してはどうでしょうか。いずれもユーザーベースを想定しています。
「コンテンツをどういう順番で見ると、LTVが高くなるか」
「どのコンテンツを繰り返し見るとLTVが高くなるか」
「LTVが高くなるパターンの行動と似通った行動をしているのに、LTVが低いユーザーの行動の特徴は?」
上記を「流入のチャンネル毎」さらに「広告別に」ユーザー行動の特徴を解析、という与件の場合、「UA+データポータル」だと、かなりの作業量になるはずです。サイトの構造にもよりますが、UAではおそらく、セグメントを数百作成する必要があるはずです。
こういう場合に活躍するのが、機械学習です。
クライアント様が必要としている「答え」は、たとえば、こういうものではないでしょうか。
ディスプレイ広告から入ってくる再訪問ユーザーは、
会員登録から3日以内に、
コンテンツを「A ⇒ D ⇒ F ⇒ A ⇒ D」の順に閲覧すると、LTVが2か月以内に5,000円を超える可能性が高い。
こうした解析ができれば、
・ユーザーが上記の「A ⇒ D ⇒ F ⇒ A ⇒ D」の順に遷移しやすいようにUIを整える
・リスティング広告の新規訪問の場合は上記とは異なる傾向が見られるので、ランディングしたページでFV(ファーストビュー)を切り替える
といった施策の検討が可能になります。
機械学習に基づいて立てた仮説で施策を考えて実装しているので、A/Bテストの勝率は高くなることが期待できます。
まとめ
「機械学習は色々できることがありそうだから、じっくり腰を据えて勉強してから取り掛かる」というのもいいのですが、新しいことを勉強するには担当者の「モチベーションの維持」が欠かせません。「機械学習を活用して施策を実装したら、会社の利益に貢献できた」という体験を担当者が1日でも早くすることが、大事だと筆者は考えます。
「そうは言っても、最初の設定がむずかしい」「導入できる人材が社内にいない」といったお悩みがありましたら、ぜひ弊社にご相談をいただけましたら幸いです。
記事作成にあたって参考にさせていただいた記事(前出の記事は除く)
Google BigQueryでお手軽機械学習(BQML) | marketechlabo
BigQuery MLの使い方についてのまとめ - Qiita
------------------------------------
弊社への「GA4導入」「機械学習活用」等などのご相談はサイトよりお願いします。
▼お問い合わせ
and,a(https://and-aaa.com/)
------------------------------------
この記事が気に入ったらサポートをしてみませんか?