
FLUX.1[dev]の実力は?比較しながらGoogle Colabで動かしてみた。

2024年8月1日、「世界最強」といわれるベンチャーキャピタル(VC)「アンドリーセン・ホロウィッツ」(a16z)が主導で投資する、Black Forest Labs(以下BFL)が、画像生成AIの新モデル「FLUX.1」を発表しました。
Stable Diffusionの元開発者たちを取り込み開発した画像生成モデルは「12B」つまり「120億パラメータ」という大規模なパラメータサイズで、『Midjourney v6.0、DALL·E 3、Stable Diffusion 3などを上回る性能を達成した』と伝えています。驚異的な画像生成能力を持つだけでなく、『これまでのAIが苦手としてきた人間の手の描写や複雑な場面の再現にも秀でている』と伝えています。さらに、商用からオープンソースまで、多様なニーズに応える3つのバージョンを用意し、ユーザーの需要を満たそうとしています。
本記事では、FLUX.1の実力をStability AIの「Stable Diffusion 3」と比較しながら調査してみます。そして実際にComfyUIとFLUX.1 [dev]を用いて画像生成を行うまでの手順と、Google Colabで動作するノートブックをメンバーシップ向けに共有します。
1. FLUX.1について

FLUX.1は、Black Forest Labsが開発した最新の画像生成AI技術です。VQGAN、Latent Diffusion、Stable Diffusionモデル ( Stable Diffusion XL、Stable Video Diffusion、Rectified Flow Transformers )、超高速のリアルタイム画像合成のためのAdversarial Diffusion Distillationの研究開発に関わった人々が参加しています。基本的な信念としては、広くアクセス可能なモデルは、研究コミュニティと学術界内での革新とコラボレーションを促進するだけでなく、信頼と幅広い採用に不可欠な透明性を高めるということです。
FLUX.1の主な特徴
1.最先端の性能: 既存の主要なAIモデル(Midjourney v6.0、DALL·E 3、Stable Diffusion 3など)を上回る性能を達成したと伝えています。
テキストから画像を生成する能力において新たな基準「ELO score」と、画像の詳細さ、プロンプトへの忠実性、スタイルの多様性、シーンの複雑さなどの面で優れた性能を示していると主張しています。
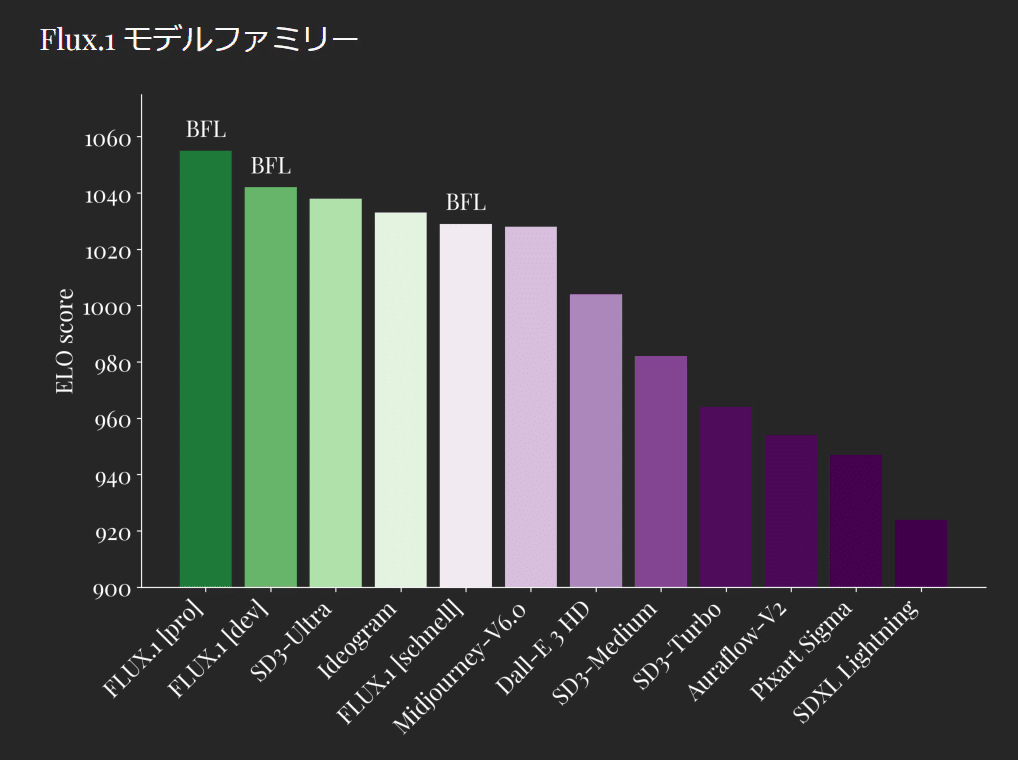
たしかに、BFLのモデルはELO scoreにおいて優位性があるようです。
順位としては FLUX.1 [pro] > FLUX1. [dev] > SD3-Ultra > Ideogram > FLUX.1 [schnell] > Midjourney-V6.0 > Dall-E 3 HD > SD3-Medium > SD3-Turboといった序列が付けられています。このバーグラフが正しければ、FLUX.1 [dev]はSD3-Ultra並であることがわかります。

2.多様なバリエーション: FLUX.1 [pro]、FLUX.1 [dev]、FLUX.1 [schnell]の3バージョンを提供します。それぞれ用途やライセンスモデルが異なります。

3.革新的な技術: マルチモーダルおよび並列拡散トランスフォーマーブロックのハイブリッドアーキテクチャを採用し、12Bパラメータにスケールアップ。
4.柔軟性: 0.1から2.0メガピクセルの範囲で多様なアスペクト比と解像度をサポート。

5.アクセシビリティ: APIを通じたアクセスと一部バージョンのオープンソース提供。
FLUX.1の3つのバリエーション
Black Forest Labsは、異なるニーズに対応するため、FLUX.1を3つのバリエーションで提供しています。
1. FLUX.1 [pro]:APIのみのフラッグシップ
FLUX.1 [pro]は、FLUX.1の最高性能を誇るバージョンです。
最先端のパフォーマンスを持つ画像生成
トップクラスのプロンプト追従能力
卓越した視覚的品質と画像の詳細さ
多様な出力
現在、Black Forest LabsはFLUX.1 [pro]の推論コンピューティング能力を徐々に拡大しているそうです。APIを通じてアクセスできるほか、ReplicateやFal.aiなどのパートナー企業を通じても利用可能です。さらに、企業向けのカスタマイズソリューションも提供するとのことです。
2. FLUX.1 [dev]:オープンウェイトモデル
FLUX.1 [dev]は、非商用アプリケーション向けのオープンウェイトモデルです。
FLUX.1 [pro]から直接蒸留された効率的なモデル
同等のサイズの標準モデルより高効率
高品質とプロンプト追従能力を維持
FLUX.1 [dev]の重みはHuggingFaceで公開されており、ReplicateやFal.aiで直接試すこともできます。ガイダンス蒸留を使用したトレーニングを行い、生成された出力は、ライセンスに記載されているように、個人的、科学的、商業的な目的で使用することができます。
3. FLUX.1 [schnell]:ローカル利用向け
FLUX.1 [schnell]は、ローカル開発と個人利用に特化した最速モデルです。
Apache2.0ライセンスで公開
Hugging Faceでweightsを入手可能
GitHubで推論コードを公開
ReplicateとFal.aiでも利用可能
各モデルの公開が非常に戦略的に進められていることが印象的です。
2. ComfyUIでFLUX.1[dev]を使用する
ComfyUIの作者であるcomfyanonymous氏が早速workflowを公開しています。以下のリンクに詳細がまとめられています。AICU AIDX Labではこのリンクの内容に従い、使用準備を進めていきます。
文末にメンバーシップ向けにGoogle Colabで動作するノートブックを公開します(AICUのGitHub上でも無償公開しています)。
weightsのダウンロード
以下のリンクよりFLUX.1[dev]のweightsをダウンロードします。flux1-dev.sft (23GB) をダウンロードし、ComfyUI/models/unetに格納してください。
CLIPのダウンロード
以下のリンクよりCLIPモデルをダウンロードします。clip_l.safetensors、t5xxl_fp16.safetensors(または省メモリ版のt5xxl_fp8_e4m3fn.safetensors)をダウンロードし、ComfyUI/models/clipに格納してください。
VAEのダウンロード
以下のリンクよりVAEをダウンロードします。ae.sftをダウンロードし、ComfyUI/models/vaeに格納してください。
Workflowのロード
以下の画像をダウンロードし、ComfyUIのキャンバスにドラッグ&ドロップしてください。画像ですが、workflowの情報が含まれているため、キャンバスにロードできます。
{kind=link}
この狐娘さんの画像にワークフローが仕込まれています!

✨️このあたりのGoogle Colabでの動作がよくわからない方には以下の記事がおすすめです。
キャンバスに上記のPNGファイルをロードすると、以下のようなフローがロードされます。
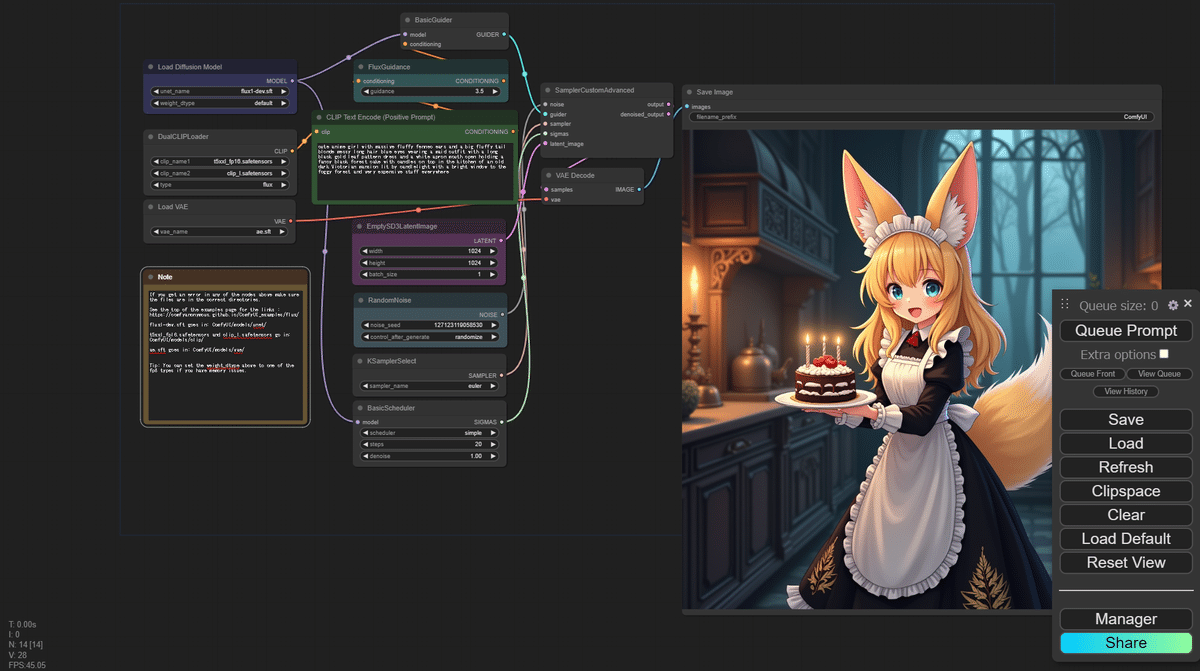
cute anime girl with massive fluffy fennec ears and a big fluffy tail blonde messy long hair blue eyes wearing a maid outfit with a long black gold leaf pattern dress and a white apron mouth open holding a fancy black forest cake with candles on top in the kitchen of an old dark Victorian mansion lit by candlelight with a bright window to the foggy forest and very expensive stuff everywhere
黒い金箔模様のロングドレスと白いエプロンのメイド服を着て、口を開けたまま、ろうそくの明かりに照らされた古い暗いビクトリア様式の邸宅の厨房で、ろうそくの上にろうそくを立てた黒い森のケーキを持っているかわいいアニメの女の子
生成できました!

FLUX.1 [dev]のモデルサイズ、Google Colabでは L4 GPU環境(GPU RAM 22.5GB)でギリギリ動作するように設計されているようです。

dev版で高品質の画像を生成するためには、50steps必要なので、BasicSchedulerのstepsを50に変更してください。
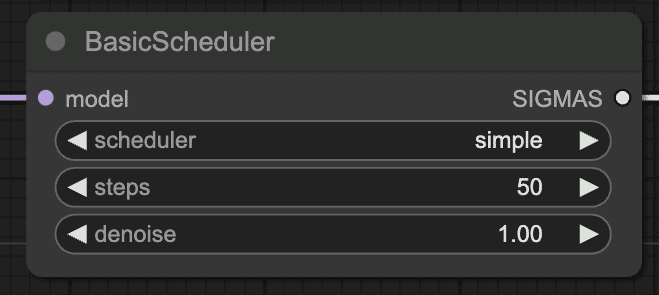

顔の表現が変わって、ろうそくが5本に増えてますね…
ネットワークを読み解く
グラフからFLUX.1のネットワークを分析してみます。
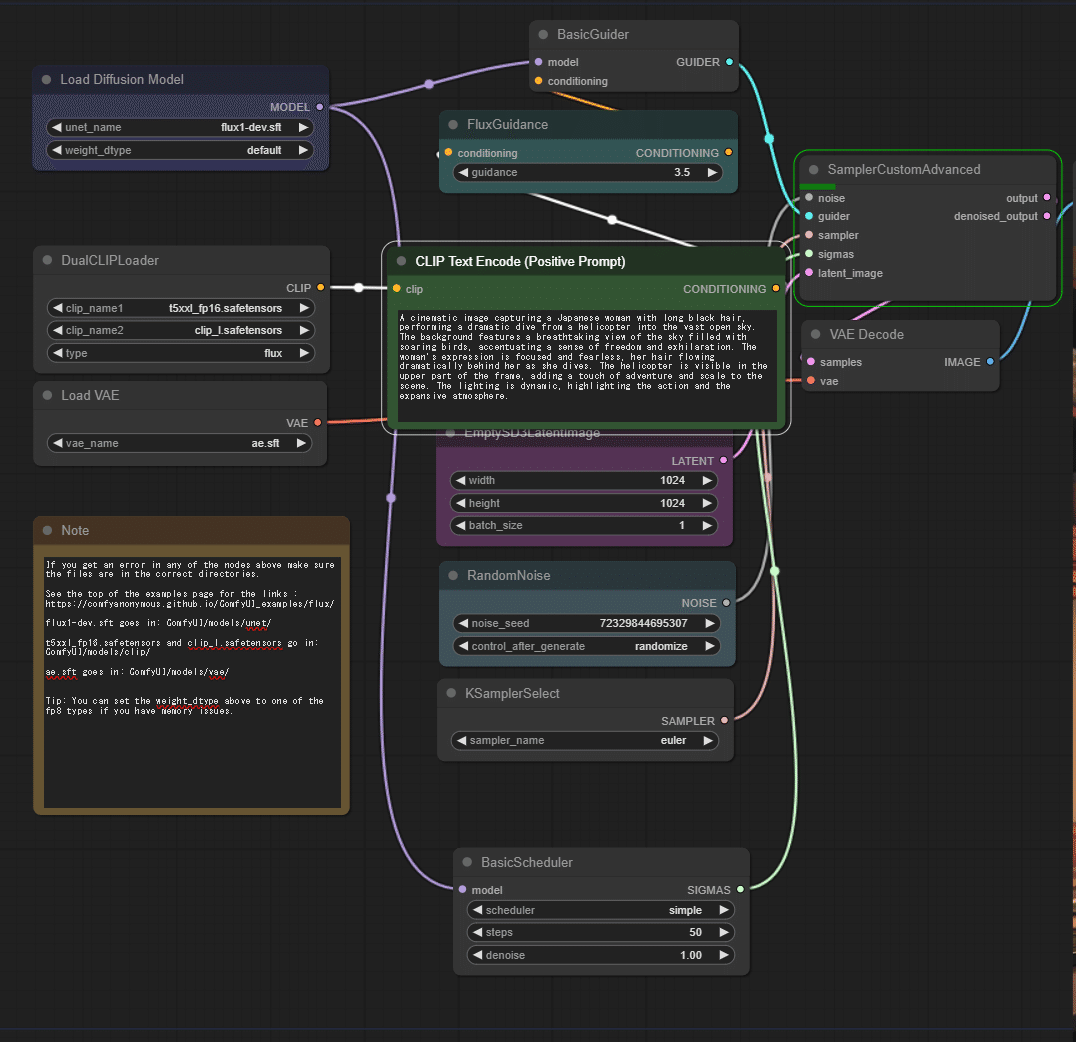
モデル→BasicScheduler→SIGMAS→[SamplerCustomAdvanced]
RandomNoize→[SamplerCustomAdvanced]
KSamplerSelect→[SamplerCustomAdvanced]
EmptySD3LatentImage(1024x1024)→[SamplerCustomAdvanced]
DualCLIPLoader→[CLIP]→FluxGuidance→(Conditioning)→[BasicGUider]→(Guider)→[SamplerCustomAdvanced]
[SamplerCustomAdvanced]→VAE Decode→Image

Stable Diffusion 3の構成によく似ています。
DualCLIP、EmptySD3LatentImageはStable Diffusion 3の部品と共通で、FluxGuidanceというノードがComfyUIによって新たに開発されています。これが従来のCFGにあたるプロンプトへの忠実度を示す値(現在は3.5)になるようです。ネガティブプロンプトやImage2Image、ControlNetはこのConditioningに与える形で提供されるのでしょうか。
ComfyUIの開発者を取り込んだ状況や、Kolorsの最近のコミュニティでの開発状況から予想するに、早い段階でControlNet等が提供される可能性もありえます。この分野はオープンソースへのモデル提供という貢献がプラスに働くコミュニティでサイクルさせていく戦略なのでしょう。
C2PAなどの対応はなし
オープンモデルを自前で立てたGoogle Colab上で動かしているので当然といえば当然ですが、C2PAの埋込情報はないようです。

有料APIでの対応がどのように提供されるのか興味深いところではあります。
3. FLUX.1[dev]による画像生成
実際にFLUX.1[dev]で画像生成してみました。以下に使用したプロンプトと生成された画像を貼付します。
ヘリコプターから飛び降りる女性
A cinematic image capturing a Japanese woman with long black hair, performing a dramatic dive from a helicopter into the vast open sky. The background features a breathtaking view of the sky filled with soaring birds, accentuating a sense of freedom and exhilaration. The woman's expression is focused and fearless, her hair flowing dramatically behind her as she dives. The helicopter is visible in the upper part of the frame, adding a touch of adventure and scale to the scene. The lighting is dynamic, highlighting the action and the expansive atmosphere.

ダッシュする髭マッチョ男性
A cinematic image depicting a rugged Japanese man with a beard, sprinting through the bustling streets of Shibuya, Tokyo. He is portrayed as muscular and intense, with his strong physique evident even through his clothing. The scene captures him mid-dash, with the iconic Shibuya crossing in the background blurred by the motion. Neon lights and the vibrant city life add to the dynamic and energetic atmosphere of the image. The lighting is urban and dramatic, emphasizing the man's determined expression and the fast-paced action of the scene.
ドラゴンと勇者
A cinematic fantasy image inspired by RPG themes, featuring a heroic scene with a dragon, a warrior, a wizard, a martial artist, and a cleric. Set in a mystical landscape, the dragon looms large in the background, spewing fire into the sky. The warrior, clad in armor, stands boldly in the foreground with a sword raised. Beside him, a wizard prepares a spell, glowing with magical energy. The martial artist, in dynamic pose, is ready to strike, and the cleric, with a staff in hand, invokes a protective spell. The scene is bathed in the ethereal light of magic and fire, creating a dramatic and epic atmosphere.
ゾンビと逃げるカップル
A cinematic image depicting a male and female couple frantically running from a massive horde of zombies. The scene is set in a chaotic urban environment with the army in the background, engaged in a fierce battle to contain the zombie outbreak. The couple appears desperate and terrified, dodging between abandoned cars and debris. Soldiers can be seen in the periphery, firing at the advancing zombies, providing a grim backdrop. The atmosphere is tense and suspenseful, with dark, ominous lighting amplifying the sense of impending danger.
足の生成テスト
A cinematic image of a Japanese woman casually displaying the soles of her feet, seated on a park bench. The scene captures her in a relaxed pose, perhaps during a leisurely afternoon in a tranquil urban park. The focus is on her bare feet, crossed elegantly as she enjoys a book or the peaceful surroundings. The background is softly blurred, emphasizing her and the detail of her feet. The lighting is warm and natural, highlighting the simplicity and quiet mood of the moment.
軍隊の上陸作戦
A cinematic image depicting a military landing at a beachfront during a defensive operation. The scene captures the intensity of the moment with troops disembarking from landing craft under the cover of smoke and gunfire. The ocean is rough, reflecting the turmoil of battle, with waves crashing against the shore. Soldiers in full gear advance onto the beach, facing resistance from defensive positions in the distance. The sky is overcast, adding a dramatic and somber tone to the scene, emphasizing the gravity of the military engagement.
複数の女性がプールで遊ぶ
A cinematic image featuring multiple Japanese women in swimsuits, enjoying a playful moment in a pool, surrounded by splashing water that creates a fantastical atmosphere. The scene captures them laughing and splashing water at each other, with the sun casting a shimmering glow on the droplets, creating a sparkling effect. The background shows a beautifully designed pool area that enhances the dreamlike quality of the image. The overall mood is joyful and ethereal, with soft, diffused lighting that adds a magical touch to the setting.
イラスト: 魔法使いが爆発魔法を唱える
A cinematic image inspired by anime, depicting a dramatic scene of magical alchemy leading to an explosion. The setting is a dark, mystic chamber filled with ancient symbols and glowing artifacts. In the center, a character performs a complex magical ritual, hands raised as they channel energy into a vibrant, swirling mass of light that culminates in a sudden, intense explosion. The explosion sends colorful magical energies radiating outward, casting vivid shadows and illuminating the room with a spectrum of light. The atmosphere is tense and charged with the power of unleashed magic.
イラスト: 異世界転生したプログラマ
A cinematic image blending realistic and anime styles, featuring a programmer who has been reincarnated into a fantastical other world. The scene shows the programmer sitting at a magical, glowing workstation filled with ancient scrolls and futuristic screens, coding to manipulate the laws of this new world. Around him, elements of a traditional fantasy setting—enchanted forests, distant castles, and mythical creatures—merge with digital effects to symbolize his unique role in this realm. The lighting is dynamic, highlighting the contrast between the old world's mystique and the new digital influence he brings.
Animagine XL 3.1のプロンプトでLuC4を生成してみる
AICUのキャラクターである「LuC4」をAnimagine XL 3.1用公式プロンプトで生成してみます。
1boy, solo, upper body, front view, gentle smile, gentle eyes, (streaked hair), red short hair with light highlight, hoodie, jeans, newest
特にアニメ要素は指定していないのですが、非常にいい感じのLuC4くんが生成されました。



1生成あたり平均129秒といったところです。これは大きい方のCLIPを使いLowVRAMモードで起動しているのでもっと高速化することもできるかもしれません。
4. 所感と疑問: 過学習?何故かアニメに強い
12B、ファイルサイズで22GB。
まず 触ってみた所感として、FLUX.1 [dev]はさすが12B、ファイルサイズで22GBという巨大なサイズです。言語理解力が高く、高品質の画像を生成するモデルではありますが、扱いやすいサイズとは言い難い。Google Colab環境のL4で快適動作するサイズのギリギリ上限として[dev]をリリースされたのは見事です。
商用利用は可能なのか?その品質は
商用利用可能ではありませんので、ホビーストが Text to Imageでの一発出しを楽しむレベルつまり、Midjourneyとしては十分な品質を持っているという印象があります。しかし商用ライセンスとしてはまだウェイティングリスト状態ですし、出力される画像はMidJourneyにNijiJourneyが混ざったような総花的な感覚を受けます。
人物の表現にも偏りや、実在感の不足を感じます。例えば最近のComfyUI環境で使われている「Kolors」はフォトリアル系人物に強い中国系企業によるモデルです。英語と中国語、文字レンダリング、指、そして東アジア各国の人物表現の分離がしっかりできています。
ComfyUIコミュニティとの協働は評価できる
上記の通り、BFLははComfyUIコミュニティとの協働を行っているようです。
ネガティブプロンプトやImage to Image、ControlNetはまだありませんが、KolorsでのComfyUIが公式からリリースされたように(※2024/8/6追記)、今後、オープンソースコミュニティと協働によって開発が進むのかもしれません。今後新しいワークフローがどこからリリースされるのか注目です。
[dev]と[pro]の互換性は?
[dev]で鍛えたナレッジが[pro]で活かせるのかどうか、プロユーザーは調査していきたいところではあります。蒸留された[dev]と商用API経由の[pro]がシードなどを介して互換性高く利用できるのであれば理想的ですが、特性がまるで異なるようであると、ビジュアル産業の用途には使いづらいと考えます。
余談ですが、APIモデルのライセンス提供やAPIプロバイダを介した提供などは、今後も各社が頑張っていくところだと予測します。例えばStability AIもFireworks.AI経由で高速なAPIを提供していますし、オープンモデルの商用ライセンスも提供しています。
オウンホストできる[dev]とAPI利用のみになる[pro]に互換性があるのであれば、ビジュアルエフェクトに関わるエンジニアにとって、パイプライン、ワークフローは組みやすくなります。しかし双方が全く異なるアーキテクチャーや特性をもっていると、別のシステムとして扱わなければなりません。
APIはドキュメントがあるが招待制
AICUでは [pro]を評価すべく https://api.bfl.ml/ において登録を行いましたが、招待制とのことで利用はできませんでした。

API化は演算環境のアウトソーシング化や品質の維持に貢献できますが、一方ではAPI提供企業によるブラックボックス化が進みやすい、透明性を下げる点もあります。
Stable Diffusionに例えて見回すと、Stable Diffusion 3 Medium や Stability AI が提供するAPIは過去のStable Diffusion 1.xや Stable Diffusion XL (SDXL)に比べてはるかに高速・高機能で高品質です。ですが市場にはまだたくさんのSD1.5やSDXLのモデルで画像生成サービスを提供している企業があるようです。市場の形成という意味では、画像生成AIをサービスしているプレイヤーがきちんと「最新のAPIを使っています」とか「商用ライセンスを買っています!」という企業が増えて欲しいところですし、消費者も目が肥えてきているので、選んで使っていきたいところです。例えばパープレはエンドユーザからの集金と、外部モデルの選択可能性の仕組みを上手くサービスとして構築しているように見えます。
今後も「とりあえず出せればいい用途」は限りなく無料化していく一方で、きちんと商業ライセンスが確立するサービスには圧倒的な画質と速度、価格と、C2PAなどの来歴データ提供などを含めたトータルな安心・安全までが整備された高品質APIに需要が向くと観測します。
▼「Stable Diffusion」の革命から2年、画像生成AIはAPIとコミュニティの時代へ ~倫理問題の「当たり前化」のその先に
追加学習しづらい
サイズが大きいということで、追加学習やファインチューニングが難しいという想像はできます。現在のリリースラインナップでは、コンシューマーレベルのGPUで扱えるサイズは[schnell]ということになるかと思います。こちらについて、評価する機会があればいずれ見てみたいと思います。
何故かアニメに強い
特にアニメや漫画に寄せたプロンプトの指定をしていなくてもいい感じのアニメ風の画像が出てきます。
AICUのコラボクリエイター犬沢某さん @InsBow の作品。
Chocolate 🐶#dogear #overall #DogEarOverAll #AIArtwork #AIArt #FLUX pic.twitter.com/zCeqSBS18w
— 犬沢某🐶BowInusawa (@InsBow) August 5, 2024
過学習の過学習をしている可能性
過学習とは、特定の学習元に最適化されたため汎化性能が下がってしまう例です。例えば「cyberpunk」というプロンプトに対してゲーム「Cyberpunk 2077」のアートが生成されてしまうような例です。これはMidJourney v6でも言われていることですが、それをベンチマークにすることで「過学習の過学習」をしてしまう可能性が感じられます。
具体的にはモデルの性質として、何も指定していないのにアニメ顔が出る点です。Danbooruタグと呼ばれる「1girl」という表現や、Animagine XL 3.1のプロンプトである「latest」などに反応している点からも、他のモデルの蒸留をして、さらに過学習をしている可能性があります。
過学習は特性として慣れれば扱いやすいかもしれませんが、一方では特定の画風や作者に対してのあらぬ嫌疑をかけられる可能性があります。
倫理的なキュレーションはされていない可能性
過学習と並んで、倫理的なキュレーションがされていない可能性を感じます。OpenAIや Stability AIといったAI基盤モデルの先駆者たちはデータセットの素性や倫理的な精査選別を行っています。このような作業を「curation」(キュレーション)、それを行う人を「キュレーター」といいます。
例えばOpenAIは「アライメント」や「キュレーション」に多大なコストを払っており、人間によって倫理的な調教を行っています。
画像生成モデルにおけるキュレーションの状態をテストすることは非常に簡単です。「NSFW」や裸体、子供や人種差別、大統領などを生成させればすぐに分かりますが、AICU mediaの紙面ではふさわしくないので、割愛します。
念の為「miku」だけSeed=39で生成してみます。

みっくみくです。念の為、Google画像検索をしてみましたが、一致する画像はありませんでした。
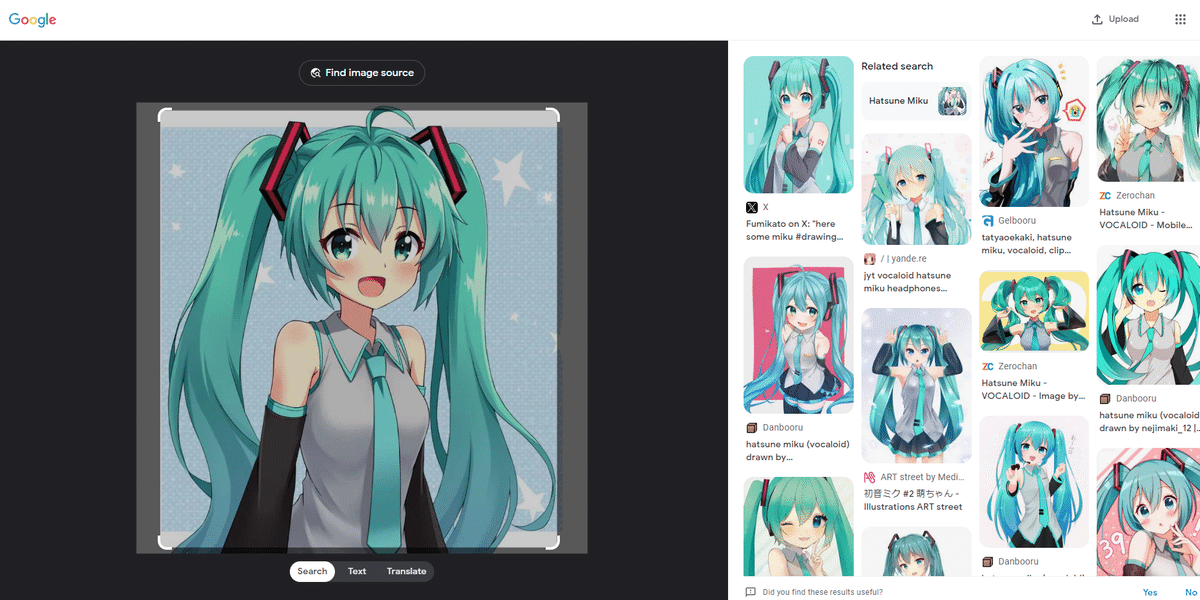
学習元のデータセットやオプトアウトといった手続きがないと新たな炎上や訴訟になる可能性があることは否定できません。
※いずれにしても生成側に責任があることは変わりません。
性能評価におけるベンチマーク対象が恣意的
いまいちどBFL提供の性能評価を確認してみます。

まず評価対象のトップにある「SD3 Ultra」ですが、ちょっと恣意的かもしれません。まず「SD3 Ultra」という名前のモデルは存在しません。Stability AIで「Ultra」と呼ばれているモデルは「Stable Image Ultra」であって「Stable Diffusion 3」でも「SD3 Ultra」でもありません。
Made from the most advanced models, including Stable Diffusion 3, Ultra offers the best of the Stable Diffusion ecosystem.
Stable Diffusion 3 を含む最も高度なモデルから作成された Ultraは、Stable Diffusionエコシステムの最高峰です。
Ultraが最高峰であるとすると、Stable Diffusion 3 シリーズで公開されているモデルの最高モデルは「Stable Diffusion 3 Large」でパラメーター数は8B、つまり推定80億パラメータ。「Stable Diffusion 3 Medium」は2B、20億パラメータです。「Ultra」はこれらの Stable Diffusion 3を含んだAPIサービスとなります。
単に最大パラメータサイズを売りにすると、120億vs80億で、「FLUX.1のほうが強そう」ですが、「同じパラメータ数のサービスとして評価すると、FLUX.1が劣後する可能性」すらあります。LLMを使った言語系サービスに例えれば「必要な課題への必要な回答」を「高い精度」で「低い費用」で利用できるためのモデルを考えてリリースする必要があり、必ずしも「辞書の大きさ」つまりパラメータ数が多いだけではなく「その最適化」、それ以外の変数やそもそも課題設定なども、求める性能を得るためには同じくらい重要です。これらを最適化するための機械学習の手法、ハイパーパラメータの最適化なども多くの技術があります。
このような課題や品質ををどう捉えているか、といった視点でもう一度リリースを見直してみると、Visual Quality, Prompt Following, Size/Aspect Variability, Typography, Output Diversity…といったレーダーチャートで表現をしています。Stable Diffusion 3 Ultraと比較して、「画質」はほぼ同等です。
その他の要素では「出力の多様性」、「サイズ・アスペクト比変動性」、「タイポグラフィ(文字)」は差が大きいようです。
多様性については評価手法が確立しているとはいい難いです。AICUではStability AI APIのCoreAPIが提供している17スタイルの評価を上位モデルと比較して1800枚程度の同一プロンプト、同一シードの画像で互換性評価を実施していますが、前述の通り『過学習の影響』は使い手が判断するしかないのが現状です。ファインチューニング手法が確立するのを待つしかないでしょうか。
タイポグラフィ
文字を打つ能力はStable Diffusion 3 Ultraよりは劣後するという表現になっており、[pro],[dev],[Schnell]で大きく差がつく要素になっていますが、実際には[dev]でもアルファベットはしっかりかけるようです。

日本語や漢字は苦手なようですが、今後はこの手の文字、特に日本語・中国語・韓国語(CJK)などの東アジア言語が主戦場になるのかもしれませんね。…といったところで実験していたら✂が出てきました。先にUnicodeでの絵文字の実装を狙っているのかもしれません。
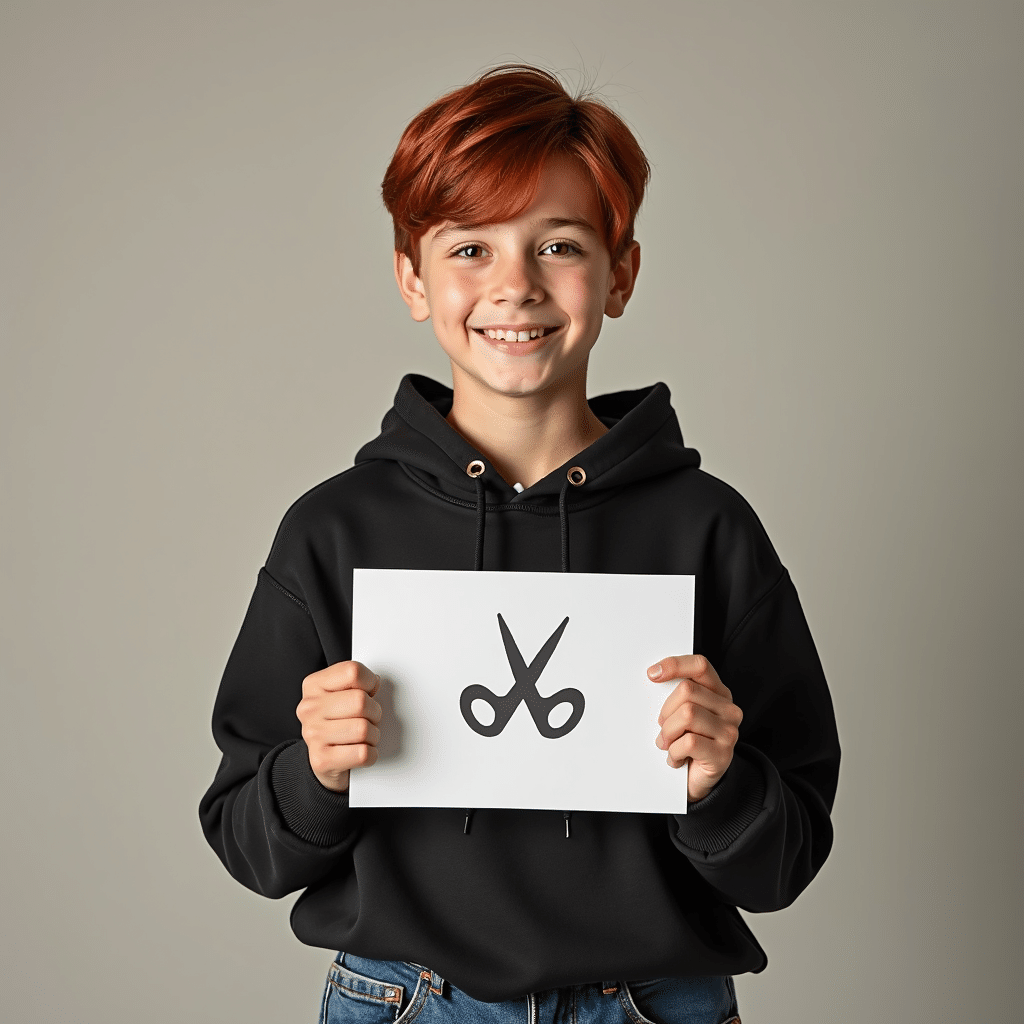
以上、FLUX.1 [dev]の実力についてのハンズオンレビューでした。
次は動画…[SOTA]が登場!?

次はすべての人のための Text-to-Video「SOTA」へ
本日「FLUX.1」 Text to Imageモデル・スイートをリリースしました。強力なクリエイティブ機能を備えたこれらのモデルは、競争力のあるジェネレーティブ Text-to-Videoシステムの強力な基盤となります。私たちのビデオモデルは、高精細でかつてないスピードでの正確な作成と編集を可能にします。私たちは、ジェネレーティブ・メディアの未来を開拓し続けることを約束します。
今後の画像生成AIにおける新しい常識がアップデートされるのでしょうか。期待して見守りたいと思います。
この記事に「いいね!」と思ったら、いいねとフォロー、おすすめをお願いします!
https://note.com/aicu/ X(Twitter)@AICUai
✨️本記事は Yas@BizDev支援のエンジニア さんの寄稿をベースにAICU AIDX Labおよび編集部にて大幅に加筆・検証したものです。ご寄稿いただきありがとうございました。
✨️初稿から評価面を大幅に加筆しています(2024年8月6日)
メンバーシップ向けボーナス・コンテンツ
Google Colabで動くノートブックを公開しています。
ここから先は
この記事が参加している募集
この記事が気に入ったらサポートをしてみませんか?