
時系列データを分析してみる(5)

こんにちは、CTO室AI推進部アナリストグループの足立です。私たちアナリストグループは、主に「プロダクトの課題発見のためのデータ分析」に取り組んでいます。ユーザの皆さんがサービスをより利用しやすくなるよう、データ分析によって得られた知見は様々な場面で活用しています。
前回は、時系列データから他とは異なる(異常な)挙動をとる箇所を取り出してみました。今回は、検出した異常を学習して、その箇所を予測してみましょう。
前回のおさらい
データから異常を検出する
これまで扱ってきた時系列データについて、他とは異なる挙動をとるデータ点やデータ群を見つけ可視化しました。そして、閾値を設けて異常とみなす箇所を取り出しました。
今回は、上記で見つけた異常な箇所を事前に予測してみましょう。そのために、前回の「異なる挙動をとるデータ群を見つけたい」で作成した部分時系列part_x、part_y、part_zと異常フラグxflg、yflg、zflgを結合して、データセットを作成します。
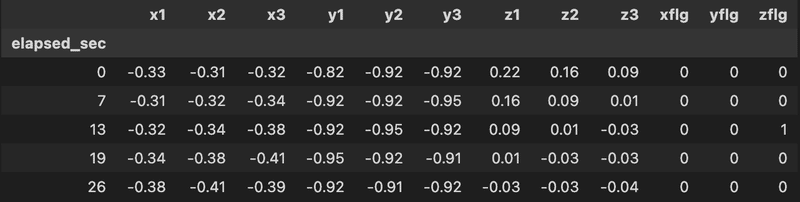
データから異常を予測する
目的変数を作成したい
ここでは、3つの異常フラグのうち1つでも1であれば、そのデータは異常とみなすことにしましょう。そして、3時刻先(elapsed_secの差が12〜14程度)に異常が発生するかどうかフラグを立てます。
そして、データセットには特徴量と目的変数のみ残しましょう。

予測モデルを作成したい
何らかの機械学習アルゴリズムを利用して、作成したデータ(学習)から予測モデルを作成しましょう。あらかじめ、学習データの不均衡をなくす、学習データを訓練とテスト用に分割しておきます。そして、決定木アルゴリズムを利用し、交差検証を実行します。
また、アルゴリズムのパラメータを最適化する、最適な特徴量の組合せを探す、といった作業は省略します。
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_val_score
# 決定木モデルを作成
clf = DecisionTreeClassifier(max_depth=5, criterion='entropy').fit(trainX, trainY)
accs = cross_val_score(clf, trainX, trainY) # 交差検証を実行
print(accs.mean(), accs.std()) # モデルの平均精度と標準偏差実行すると、訓練データから作成したモデルの平均精度と標準偏差を得られます。
検証結果を眺めたい
テストデータにモデルを適用し、性能を確認しましょう。そのために、テストデータに対する精度や混同行列をみたり、モデルの構造を可視化します。
from sklearn.metrics import accuracy_score
from sklearn.metrics import confusion_matrix
pred = clf.predict(testX) # テストデータへモデルを適用
print(accuracy_score(testY, pred)) # テストデータに対する精度
print(confusion_matrix(testY, pred)) # テストデータに対する混同行列from sklearn.tree import plot_tree
# 木構造を可視化
plot_tree(clf,
feature_names=['x1', 'x2', 'x3', 'y1', 'y2', 'y3', 'z1', 'z2', 'z3'],
class_names=['0', '1'])
まとめ
本記事では、前回検出した異常を学習して、その箇所を予測する方法を紹介しました。また、本連載はこれにて終了です。本連載において、時系列データの扱いを一通り紹介してきました。これらの内容が、読者の皆さんの参考になれば幸いです。