
時系列データを分析してみる(1)

こんにちは、CTO室AI推進部アナリストグループの足立です。私たちアナリストグループは、主に「プロダクトの課題発見のためのデータ分析」に取り組んでいます。ユーザの皆さんがサービスをより利用しやすくなるよう、データ分析によって得られた知見は様々な場面で活用しています。
これから、データサイエンスの視点に立ち、時系列データ分析の進め方を複数回に分けて紹介していきます。まずは、時系列データの性質を掴むことから始めます。
時系列データとは
時系列データは、時間の経過に伴い値が変化するデータを指します。ある時点の値は、前後の値と関係があります。また、時系列データは系列データの一種です。系列データには、時間に依存するもののほか、並びに依存するものもあります。例えば、ある文章を構成する単語の並び(語順)は、系列データとして扱うことができます。語順によって、主語や目的語が変われば文章は異なる意味を持ちます。
データ分析の進め方
前回投稿した記事「CRISP-DMをうまく活用する」で紹介した、CRISP-DMに沿ってデータ分析を進めていきます。
分析問題を設定する
将来に発生する可能性がある何らかのイベントを事前に検出したい、また事前にその時期を知りたい、といった課題があるとします(実際は、5W1Hを考慮して課題はより詳細に設定します。)。
このとき、データを活用して、過去の挙動から将来に発生するイベントを検出するモデルを作成する、イベントが発生する時期を予測するモデルを作成する、といった問題を設定できます(実際は、5W1Hを考慮して問題はより詳細に設定します。)。
本記事では、特定の問題に絞り込まないようにして、幅広く使える手法を紹介します。
データを理解する
データについて
本記事では、時間の経過に伴うX,Y,Z方向の加速度の変化を記録したデータセットを利用します。ここで、データセットはCSVファイル形式のものとし、以後PythonのPandasによって操作することにします。
import pandas as pd # パッケージの読み込み
df = pd.read_csv('./data.csv', sep=',') # ファイルの読み込み
df.head() # 先頭5行を表示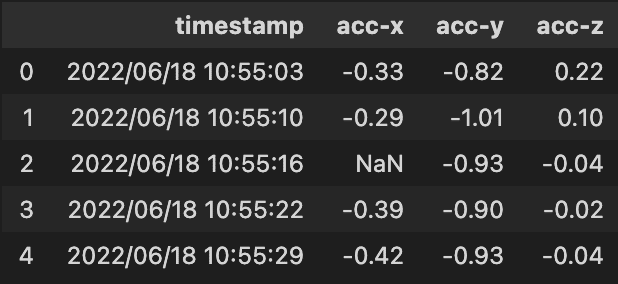
データの大きさを知りたい
データセットがどれくらいのデータ数(行数)、変数の個数(列)を持っているかを調べます。
print(df.shape) # データの大きさを出力
# output
# (323, 4) -> データは323行、変数は4つデータの型を知りたい
データセットが持つ各変数の値によって、変数のデータ型は異なります。例えば、整数値を持つ変数のデータ型はint型、小数値を持つ変数のデータ型はfloat型、日付時刻値を持つ変数のデータ型はdatetime型です。
print(df.dtypes) # データの型を出力
# output
# timestamp object
# acc-x float64
# acc-y float64
# acc-z float64データの統計量を知りたい
各変数の特徴を知りたいとき、データセットに含まれるデータの値を一つずつ確認していくことは非常に時間がかかります。そこで、各変数の代表値を計算し、まずは全体的な特徴を掴んでみましょう。
# データ型の変換
df['timestamp'] = pd.to_datetime(df['timestamp'], format='%Y-%m-%d %H:%M:%S')
# 全ての統計量を計算
df.describe(datetime_is_numeric=True)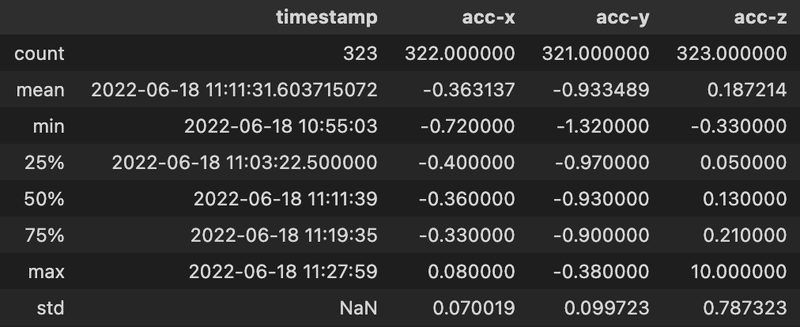
上から順に、各変数のデータ件数(count)、平均値(mean)、最小値(min)、第1四分位数(25%)、中央値(50%)、第3四分位数(75%)、最大値(max)、標準偏差(std)を意味します。
ここで、各変数のデータ件数が一致しないことに注目しましょう。全データ件が323であることから、変数acc-xとacc-yは値が欠損していることが分かります。
データの欠損値数を知りたい
データセットに欠損値がいくつ存在するか、確認してみましょう。ここでは、上記のdescribeを利用しない方法を紹介します。
print(df.isnull().sum(axis=1)) # 行方向の欠損値数
print(df.isnull().sum(axis=0)) # 列方向の欠損値数
# output
# 行方向
# 0 0
# 1 0
# 2 1
...
# 列方向
# timestamp 0
# acc-x 1
# acc-y 2
# acc-z 0データの重複数を知りたい
データセットに重複データ件数がいくつ存在するか、そしてどのデータが該当するか確認してみましょう。
print(df.duplicated().sum()) # 重複している行数
df[df.duplicated()] # 重複行の抽出
# output
# 2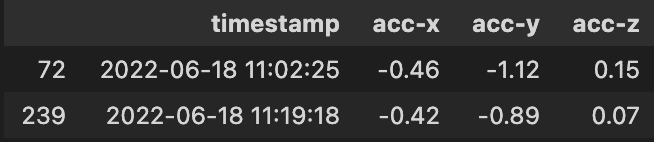
1つ以上の重複が存在するとき、データの大きさに影響を与えている可能性があります。データセットから重複データを除外して、再度データの大きさを確認するとよいでしょう。
データの値の推移を知りたい
各変数の特徴を代表値に集約すると、パッと見て理解しやすい反面、変数が持つ特徴を表現しきれないかもしれません。そこで、折れ線グラフにより、時間経過による値の推移を可視化してみましょう。代表値とグラフを併用すると、各変数の特徴について理解が深まります。
ここでは、Matplotlibによってグラフを作成します。
import matplotlib.pyplot as plt
# 横軸をyyyy/mm/dd hh:mm:ssで時系列を可視化
plt.plot(df['timestamp'], df['acc-x'], color='red', label='acc-x')
plt.plot(df['timestamp'], df['acc-y'], color='green', label='acc-y')
plt.plot(df['timestamp'], df['acc-z'], color='blue', label='acc-z')
plt.xlabel('timestamp')
plt.ylabel('acc')
plt.xticks(rotation=45)
plt.legend()
plt.show()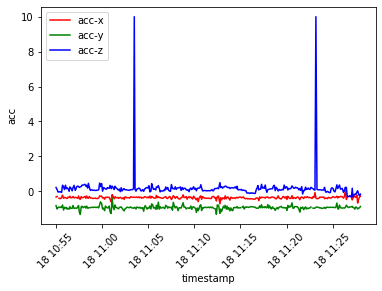
変数acc-zがとる値について、2ヶ所ほど、前後の値と大きく異なる値をとる部分があります。データを可視化することは、このような外れ値を見つけることにも役立ちます。
データの値がとる範囲を知りたい
各変数の値がとる範囲を箱ひげ図で表現してみましょう。箱ひげ図は、箱の底部が第1四分位数、箱の頭部が第3四分位数、箱の中央が中央値を意味します。そして、ひげの上部が最大値、下部が最小値を意味します。
df.boxplot() # 箱ひげ図を描画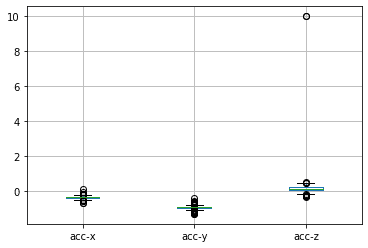
データの関係性を知りたい
もし、ある変数の値の推移が別の変数のものと連動しているようなら、散布図によって2つの変数の関係を可視化してみましょう。
# acc-xとacc-zの散布図を描画
plt.scatter(df['acc-x'], df['acc-z'])
plt.xlabel('acc-x')
plt.ylabel('acc-z')
plt.show()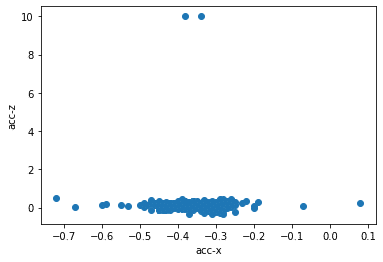
2つの変数の関係は、データ点群が右肩上がりの直線に見えるように(比例関係のように)存在していれば、正の相関が強いと言えます。逆に、データ点群が右肩下がりの直線に見えるように(反比例関係のように)存在していれば、負の相関が強いと言えます。
また、散布図を眺めて2つの変数の関係を測るより、相関係数によって測るほうがより定量的に理解できます。相関係数が1に近いほど、2つの変数の相関は強いと言えます。
print(df.corr()) # 相関係数を計算
# output
# acc-x acc-y acc-z
# acc-x 1.000000 0.506950 0.009638
# acc-y 0.506950 1.000000 0.030202
# acc-z 0.009638 0.030202 1.000000まとめ
本記事では、データを読み込んでまず理解することをいくつか取り上げて紹介しました。次回はこの続きとして、今回見つけたデータの重複、欠損値や外れ値をどのように処理するかを紹介します。