
時系列データを分析してみる(3)

こんにちは、CTO室AI推進部アナリストグループの足立です。私たちアナリストグループは、主に「プロダクトの課題発見のためのデータ分析」に取り組んでいます。ユーザの皆さんがサービスをより利用しやすくなるよう、データ分析によって得られた知見は様々な場面で活用しています。
前回は、時系列データを前処理して形を整えました。今回は、前回の結果とは違った軸でデータ前処理し、挙動を俯瞰して見てみましょう。
データを前処理する
データについて
前回の結果から得られたデータセットを扱います。元のデータセットは、時間の経過に伴うX,Y,Z方向の加速度の変化を記録したCSVファイルです。以後、PythonのPandasによって操作することにします。
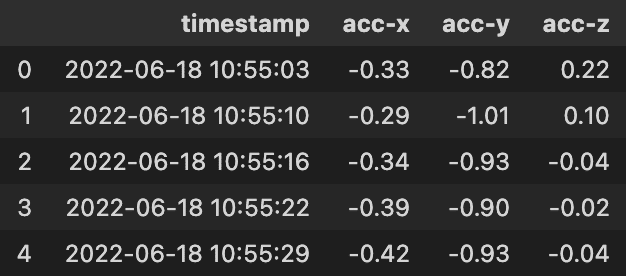
経過時間を知りたい
前回は、データセット含まれる記録時間(変数timestamp)をそのまま利用して、データを集計・可視化しました。後々、何らかのモデルを作成するとき、時間は一意な値よりも経過(累積)値のほうが扱いやすいかもしれません。よって、値を記録し始めてからの経過時間を計算しましょう。
# 累積秒を計算
df['dif_sec'] = df['timestamp'].diff().dt.total_seconds().fillna(0)
df['elapsed_sec'] = df['dif_sec'].cumsum().astype('int')
# 秒をインデックスに指定
df_sec = df.drop(['timestamp', 'dif_sec'], axis=1).set_index('elapsed_sec')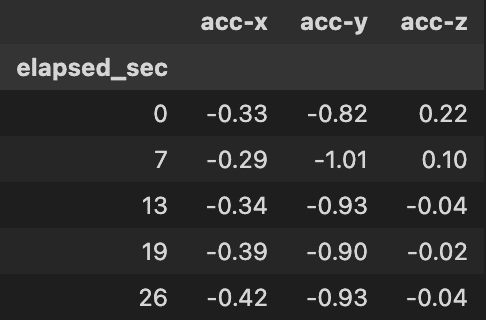
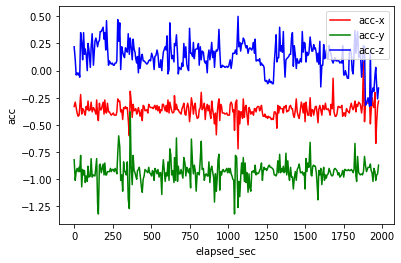
また、Matplotlibを利用して、時間経過によるデータ値の推移を可視化しましょう。このグラフの挙動は、前回の結果と同じです。
大まかな挙動を知りたい(1)
データの記録時間の間隔が短いほど、取得したデータ値の個数は多くなるため、挙動を細かに見ることができます。しかし後々、何らかのモデルを作成するとき、特徴量としてこれら全ての値をそのまま利用しなくても、集約した値を利用すればよいかもしれません。このような場合に備え、データ値を集約して見ましょう。
15秒単位でデータ値を集約してみましょう。このとき、時間区間は重複しません。また、同じ時間区間の平均値に集約します。
# 15秒をインデックスに指定
df['grouped_sec'] = (df['elapsed_sec']/15).astype(int)*15
df_grouped_sec = df.drop(['timestamp', 'dif_sec', 'elapsed_sec'], axis=1).set_index('grouped_sec')
# 15秒ごとの平均値を計算
df_grouped_mean = df_grouped_sec.groupby(level=0).mean().round(2)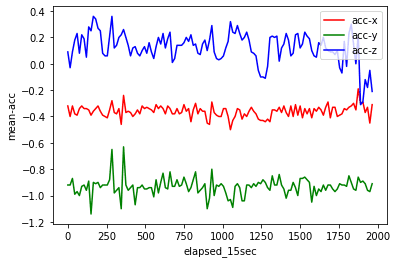
元の値と集約した平均値を描画して比較してみましょう。平均値の挙動は、元の挙動の形を残しているように見えます。また、他の値とは絶対値が大きく異なるものの影響が小さくなっているように見えます。
plt.plot(df_sec.index, df_sec['acc-x'], color='gray',
linestyle='dashed', label='acc-x_original') # 元の値
plt.plot(df_grouped_mean.index, df_grouped_mean['acc-x'], color='black',
linestyle='solid', label='acc-x_mean') # 平均値
plt.xlabel('elapsed_15sec')
plt.ylabel('acc, mean-acc')
plt.legend()
plt.show()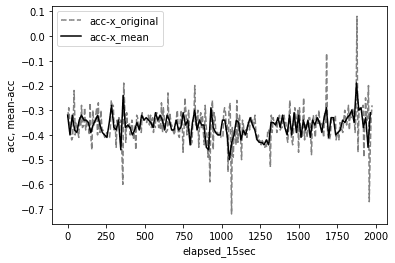
加えて、同じ条件で標準偏差も計算してみましょう。平均値と標準偏差をまとめて可視化すると、値の範囲が大きい箇所が分かります。また、一部の処理にNumpyを利用しています。
# 15秒ごとの標準偏差を計算
df_grouped_std = df_grouped_sec.groupby(level=0).std().round(2)
# 平均値と標準偏差をまとめて描画
x = np.array(df_grouped_mean.index)
# acc-x
plt.plot(x, df_grouped_mean['acc-x'], color='red', label='acc-x')
plt.fill_between(x,
df_grouped_mean['acc-x']+df_grouped_std['acc-x'], # 上限
df_grouped_mean['acc-x']-df_grouped_std['acc-x'], # 下限
alpha=0.2, color='red')
# acc-y
plt.plot(x, df_grouped_mean['acc-y'], color='green', label='acc-y')
plt.fill_between(x,
df_grouped_mean['acc-y']+df_grouped_std['acc-y'], # 上限
df_grouped_mean['acc-y']-df_grouped_std['acc-y'], # 下限
alpha=0.2, color='green')
# acc-z
plt.plot(x, df_grouped_mean['acc-z'], color='blue', label='acc-z')
plt.fill_between(x,
df_grouped_mean['acc-z']+df_grouped_std['acc-z'], # 上限
df_grouped_mean['acc-z']-df_grouped_std['acc-z'], # 下限
alpha=0.2, color='blue')
plt.xlabel('elapsed_15sec')
plt.ylabel('mean-acc')
plt.legend()
plt.show()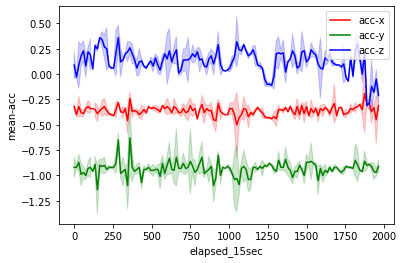
大まかな挙動を知りたい(2)
先ほどと同じく、15秒単位でデータ値を集約してみましょう。このデータセットでは、3データに相当します。またこのとき、時間区間は重複し、同じ時間区間の平均値に集約します。つまり、移動平均を取ってみましょう。
先ほどの時間区間が重複しない平均値(区間平均)と、今回の時間区間が重複する平均値(移動平均)を描画して比較してみましょう。どちらの挙動も概ね同じ形を取っているように見えます。移動平均値は、集約しない元の値の特徴を残しているように見えます。
# 3データの移動平均を計算
df_rolling_mean = df_rolling_mean.rolling(3, min_periods=1).mean().round(2)
# 平均値と移動平均値を可視化
plt.plot(df_grouped_mean.index, df_grouped_mean['acc-x'], color='black',
linestyle='solid', label='acc-x_mean') # 平均値
plt.plot(df_rolling_mean.index, df_rolling_mean['acc-x'], color='gray',
linestyle='dotted', label='acc-x_m-mean') # 移動平均値
plt.xlabel('elapsed_15sec')
plt.ylabel('mean-acc, m-mean')
plt.legend()
plt.show()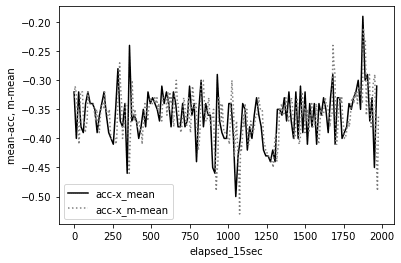
加えて、同じ条件で標準偏差も計算してみましょう。平均値と標準偏差をまとめて可視化すると、値の範囲が大きい箇所が分かります。
# 3データの移動標準偏差を計算
df_rolling_std = df_rolling_std.rolling(3, min_periods=1).std().round(2).fillna(0)
# 平均値と標準偏差を描画
x = np.array(df_rolling_mean.index)
# acc-x
plt.plot(x, df_rolling_mean['acc-x'], color='red', label='acc-x')
plt.fill_between(x,
df_rolling_mean['acc-x']+df_rolling_std['acc-x'], # 上限
df_rolling_mean['acc-x']-df_rolling_std['acc-x'], # 下限
alpha=0.2, color='red')
# acc-y
plt.plot(x, df_rolling_mean['acc-y'], color='green', label='acc-y')
plt.fill_between(x,
df_rolling_mean['acc-y']+df_rolling_std['acc-y'], # 上限
df_rolling_mean['acc-y']-df_rolling_std['acc-y'], # 下限
alpha=0.2, color='green')
# acc-z
plt.plot(x, df_rolling_mean['acc-z'], color='blue', label='acc-z')
plt.fill_between(x,
df_rolling_mean['acc-z']+df_rolling_std['acc-z'], # 上限
df_rolling_mean['acc-z']-df_rolling_std['acc-z'], # 下限
alpha=0.2, color='blue')
plt.xlabel('elapsed_sec')
plt.ylabel('mean-acc')
plt.legend()
plt.show()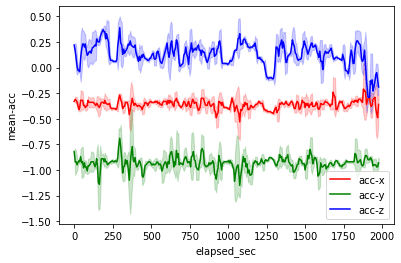
まとめ
本記事では、時系列データの挙動を俯瞰して見るための、いくつかの方法を取り上げて紹介しました。次回はこの続きとして、データセットにおいて他とは異なる挙動を持つ箇所を取り出してみます。