
時系列データを分析してみる(2)

こんにちは、CTO室AI推進部アナリストグループの足立です。私たちアナリストグループは、主に「プロダクトの課題発見のためのデータ分析」に取り組んでいます。ユーザの皆さんがサービスをより利用しやすくなるよう、データ分析によって得られた知見は様々な場面で活用しています。
前回は時系列データを集計・可視化して、その性質を掴むことから始めました。今回は前回の結果をもとに、時系列データを前処理して、より分析しやすいよう形を整えていきましょう。
データを前処理する
データについて
前回と同じく、時間の経過に伴うX,Y,Z方向の加速度の変化を記録したデータセットを利用します。ここで、データセットはCSVファイル形式のものとし、以後PythonのPandasによって操作することにします。
import pandas as pd
# ファイルの読み込み
df = pd.read_csv('./activity-log-miss.csv', sep=',')
# データ型の変換
df['timestamp'] = pd.to_datetime(df['timestamp'], format='%Y-%m-%d %H:%M:%S')
print(df.shape) # データの大きさ
print(df.dtypes) # データの型
df.head() # 先頭5行を表示# output
# (323, 4) -> データは323行、変数は4つ
# timestamp datetime64[ns] -> 変数は日付時刻型
# acc-x float64 -> 変数は小数型
# acc-y float64
# acc-z float64
# dtype: object重複データを除外したい
前回は、データセットに重複データが存在することを調べました。重複データが存在することは、まったく同じパターンが存在することを意味します。後々、何らかのモデルを作成するとき、重複データはモデルの精度に悪い影響を与えるかもしれません。よって今回は、これらの重複データを除外しましょう。
df = df.drop_duplicates(keep='first') # 重複する行を除外
print(df.shape) # データの大きさ
# output
(321, 4)重複データは2件存在し、これらをデータセットから除外できました。
外れ値を除外したい
前回、Matplotlibを利用して、時間経過によるデータ値の推移を可視化しました。折れ線グラフを見ると、変数acc-zは2ヶ所、前後の値と大きく異なる値を取っていると確認できます。
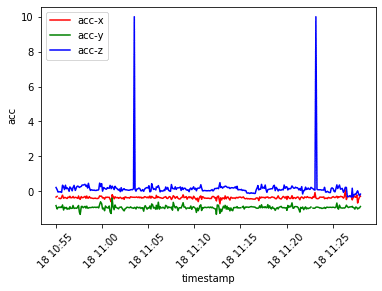
このような外れ値が存在したままだと、後々作成する何らかのモデルの精度に悪い影響を与えるかもしれません。よって今回は、これらの外れ値データを除外しましょう。
df['acc-z'].mask(df['acc-z']>2, inplace=True) # 外れ値を欠損値へ置換改めて、時間経過によるデータ値の推移を可視化してみましょう。データセットから外れ値を除外したため、先のグラフよりも各変数の挙動が分かりやすくなっています。

欠損データを除外したい
データセットに欠損値が残ったままでは、後で何らかのモデルを作成することができません。

よって欠損値に対し、該当するデータ(行または列)ごと除外する、何らかの方法をもって補完する等の処理を適用します。ここでは、欠損値を含む行または列を除外してみましょう。
df.dropna(how='any', axis=0) # 1つ以上の欠損値を持つ行を除外
df.dropna(how='any', axis=1) # 1つ以上の欠損値を持つ列を除外
欠損行を除外するとデータセットの行数は316件、欠損列を除外するとデータセットの列数は1つになります。
欠損値を補完したい
ここでは、ある欠損値について、その前の値によって補完する、その後の値によって補完する、その前後の値によって補完する方法を取りあげます。
df_ffill = df.fillna(method='ffill') # 直前の値で補完
df_bfill = df.fillna(method='bfill') # 直後の値で補完
# 前後の値で(線形)補完
df_lfill = df.set_index('timestamp').interpolate(method='linear')
3つの補完結果を比較すると、前後の値で補完したものは他の2つと比べて挙動が滑らかになりそうですね。
再びデータを理解する
前処理したデータに対し、前回と同じく統計量を算出し、他のグラフによって可視化してみましょう。
データの統計量を知る
前回の結果とは異なり、各変数のデータ件数(count)は揃っています。
# 全ての統計量を計算
df_lfill.reset_index().describe(datetime_is_numeric=True)
データの値がとる範囲を知る
変数acc-zの外れ値を除外しているため、前回の結果とは異なり箱の大きさが圧縮されておらず、各四分位数が見やすく反映されています。
df_lfill.boxplot() # 箱ひげ図を描画
データの関係性を知る
変数acc-zの外れ値を除外しているため、前回の結果とは異なり各データ点が密集することなく散らばっています。2つの変数に関係があるかどうか、判断しやすくなりました。
# acc-xとacc-zの散布図を描画
plt.scatter(df_lfill['acc-x'], df_lfill['acc-z'])
plt.xlabel('acc-x')
plt.ylabel('acc-z')
plt.show()
まとめ
本記事では、データに対しどのような前処理を適用できるか、その方法をいくつか取り上げて紹介しました。次回はこの続きとして、時系列データの傾向を掴みやすくする処理を紹介します。