
AIにテレビCMの絵コンテの仕上げさせたら余裕、と思っていた話

こんにちは。
今日は、ControlNetという手法を使って、テレビCMの絵コンテをリアルに仕上げていきたいと思います。
注:著者はAIエンジニアでもCMクリエイターでもないので、双方の視点からいろいろお見苦しい点はありますが、ご容赦ください。
ControlNetとは?
ControlNetとは、画像生成アルゴリズムであるStable Diffusionの制御手法の一つで、2週間ほど前から話題になっているものです。
これは端的に言えば、「事前に設定した構図で画像が生成されるよう制御する」というものです。プロンプトとは別に以下のような情報を構図として入力可能で、かなり強力に生成される画像の構図を制御してくれます。
別の画像から抽出した輪郭線
骨格(OpenPose)
深度
セグメンテーション(色面による区分)
手書きのラフ
などなど
これにより、Stable Diffusion をはじめとする画像AIが抱えていた「想定の構図が出るまで生成し続ける(いわゆる生成ガチャ)」をする必要がなくなったため、非常に流行しています。いわゆるimg2imgに近いのですが、構図だけ保持したまま、まったく違う色や対象にすることができます。

ControlNetの使い方
2月23日時点でControlNetは「Stable Diffusion webUI(automatic1111)」上でサポートされていて、webUIのプラグインと、対応するモデルをダウンロードすることで利用が可能です。
詳しい使い方は割愛します。たくさん記事があるので調べてみてください。
ちなみに私のPCはグラボがないので、「CPUのみ版」で動かしています。そのため1枚生成するのに数分かかり、たくさんの検証をしていると疲れます(伏線)。
CMの絵コンテをつくってみる
ここから多少、広告会社っぽい話になります。
コンテとは、テレビCMを制作する際に、CMプランナーやクリエイティブディレクターという立場のクリエイターが、おおまかなCMの流れを設計するための資料です。
正確には、CMの構成を決めるためにクリエイターが作成するものが「企画コンテ」、演出家がカット割りなど細部を決めるためのものが「演出コンテ」などと呼ばれています。また「企画コンテ」も、走り書きレベルのラフなものもあれば、クライアントに提案するために丁寧に仕上げられたものもあります。
今回は、ControlNetを使うことで、走り書きレベルの「企画コンテ」から、より説得力のある提案用のコンテがつくれないかに挑戦をします。
サンプルコンテをつくる
ネットに落ちているものの多くは著作権が広告主にあるので、仕方なく自分で作ってみました。ネタはいつも通り愛用のPixe7にして、代表的な機能である「消しゴムマジック」にフォーカスした企画にしました。
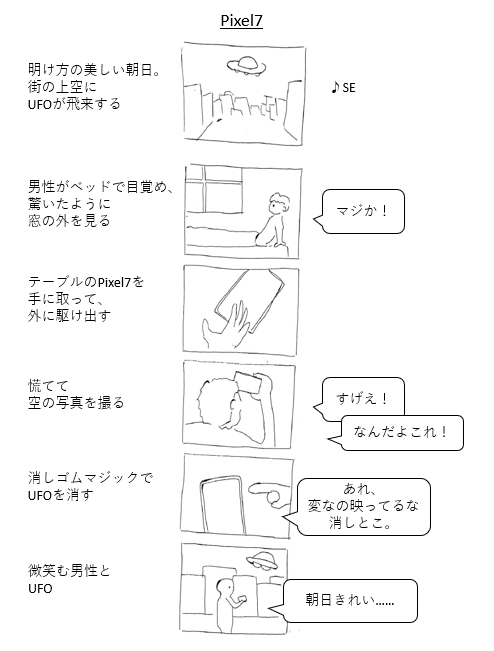
私は広告会社でクリエイティブの試験に何度か落ちているので、これが限界です。今回は企画の面白さの検証ではありません。
今回は、企画の面白さの検証ではありません。
この手描きコンテを、ControlNetを使って、できる限り実写に近づけていきます。
シーン1

このひどい絵を、ためらいなくControlNetに突っ込みます。
使用するStable Diffusionのモデルは1.5(現状SD1.5にしか対応していない様子)、ControlNetのモデルは手書きのラフに対応している「Scribble」にしています。Stable Diffusionのモデルを、実写に特化したものに差し替えることでより精度は上がると考えられます。

概ね良い感じにできました。プロンプトも標準的なので紹介を省きますが、使用されるシーンに応じて、プロンプト内のカメラのレンズの画角を変えています。このシーンは広角なのでSIGMA 18㎜ f2と入れてみました(実際はそんなレンズはない)。
シーン2
続いてはこのシーンです。
一応補足すると、「わざと雑に描いている」ので、そこはご理解ください。

これもためらいなくControlNetに突っ込みます。

プロンプトが悪かったようなので、改良します。
ちなみに、ネガティブプロンプト(こういう絵は出さないでねという指示)をうまく使わないと、上半身裸の男性ばかりが出力されます。なぜだ?

もうこれでいいです。
シーン3

手の出力はStable Diffusionの苦手とするところですが、ControlNetを使うことでだいぶ改善します。

このあたりで自分の絵心の無さに絶望します(伏線です)。
シーン4
どこまでラフでいけるのか試すため、あえてぐちゃぐちゃにしたのですが、改めて見てみるとひどすぎて言葉を失います。

このカットだけは、何度やっても、良いアウトプットができませんでした。
本来はもう少し丁寧に描きなおすべきでしたが、試しに使っていたプロンプトを、ControlNet無しの通常のStable Diffusionに突っ込んでみました。

ついでにinpaintingでUFOを加筆したものです。物語の流れ的に、ここはUFOが映っていてもよさそうです。
シーン5
もうすでに私のやる気がゼロなのでラフも雑を極めます。

右の何かが手だと気づいた人は少ないと思いますが、実際Stable Diffusionも手だと思ってくれなかったようで、

背景のボケのなめらかさだけが、SIGMA 85㎜ f2(架空)を感じさせます。
シーン6

生成スピードが遅いためどんどん投げやりになってきました。が、少し複雑なこの構図も、ControlNetは捉えてくれました。

まとめてみる
それでは、最初の手書きのコンテの画像を差し替えてみます。
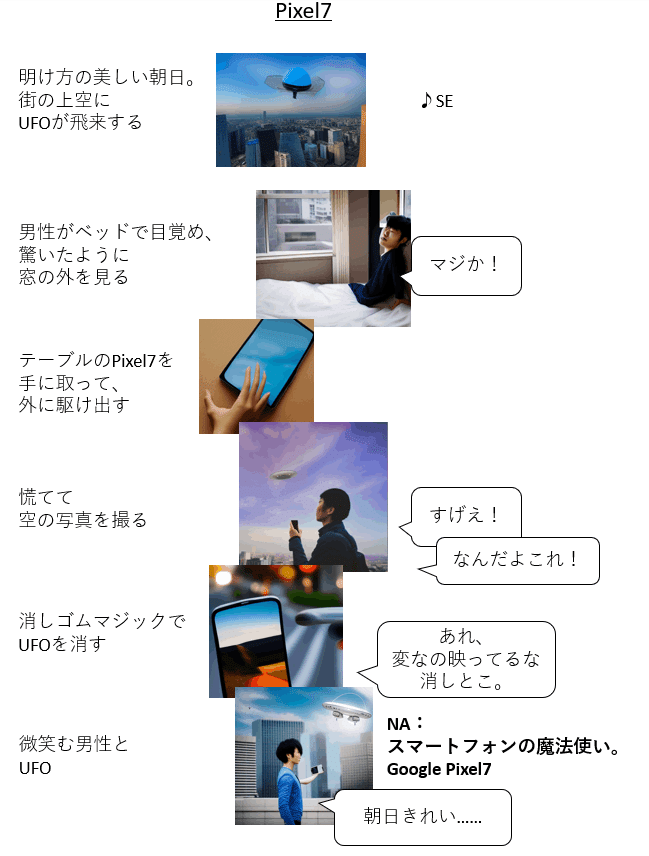
うーん、、、微妙な出来ではあります。「AIでつくったんですねー」以上の感想が出てきません。
後半は力尽きたので、もう少し丁寧にやれば、もっとよくなりそうです。
ちなみに、「スマートフォンの魔法使い。」というキャッチフレーズを追加しています。これは前回の記事で解説した、GPTコピーライターが生成してくれたものです。

GPTコピーライターも、前回より改良が入っているので、それもどこかでご紹介したいと思います。
前回の記事はこちら↓
もう1チャレンジ
ここで、ふと気づいたことがあって、別のやり方を試しました。それがこちらです。
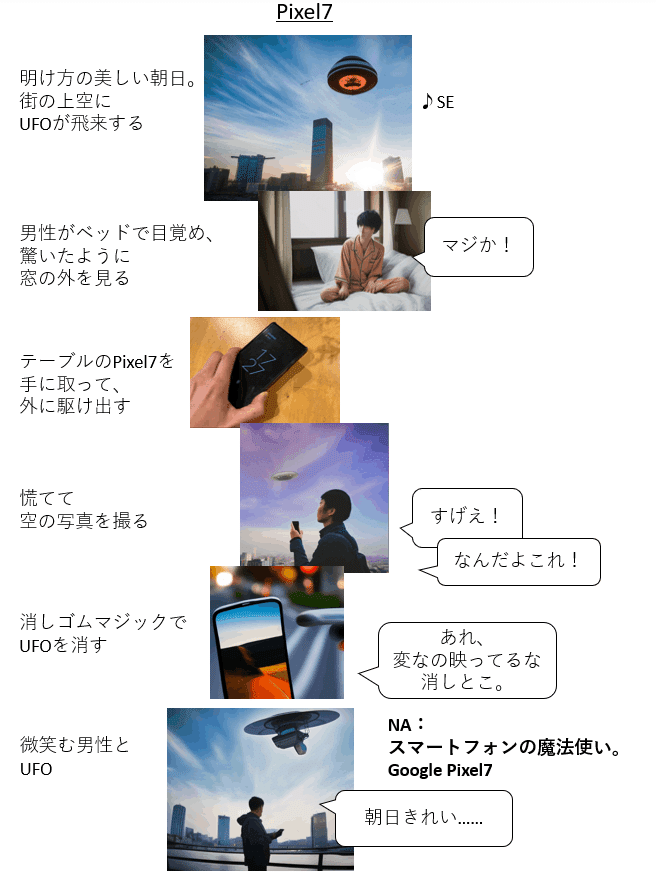
前回のものと、シーン1、2、3、6の画像が変わっています。構図は私が指定したものではないですが、より迫力があるものとなっており、特にシーン1やシーン6などは結構説得力があります。シーン2も、前ボケが使われていて奥行き感があり、良いカットです。
やったことは単純で、ControlNetを使わず、まったく同じプロンプトで普通にStable Diffusionに出力させただけです。
そのほうが迫力があるというのは、つまり、私のつくった構図がしょぼかったということに他なりません。
Stable Diffusionは、大量にすぐれた写真を学習しているため、私が考えるよりも迫力のある構図で、出力することができたのでしょう。下手に素人が構図を考えるより、このほうが合理的でした。おそらくこの出力にさらにControlNetを噛ませて、空の色や人の髪型に一貫性を持たせれば、より良くなるでしょう。
そして、シーン3は、AIで生成したものですらありません。私が手元にあったPixe7を掴んで、それを撮ったものです。
要は、使い分けということですね。
まとめ
やってみてわかったことをまとめます。
ControlNetを使った構図指定はかなり精度が高いが、あまりにラフすぎる手描きだと認識してくれないこともある。
構図の指示ができるので指示したくなってしまうが、素人が考えるより、AIに任せたほうが良いこともある。
構図まで指定するか、AIにゆだねるか、ほかの方法を考えるか、最適な方法論は状況によって異なる。
また、結局AIのほうが良い構図を出してきて強く思ったのですが、これからの人間のクリエイターに求められるのは
「良い表現とは何かを知っている・判断できる」
ことにほかなりません。
誰でも臨む表現が自由に創作できるAI時代にあって、小手先の技術はコモディティ化していきます。どのような表現が優れているか・心を動かすか・美しいと感じるか、などの知識や判断力こそ、クリエイターに求められる最大のスキルだなと、改めて感じました。
世間はAI教育、プログラミング教育に躍起になっていますが、一度開発されたものは専門知識が要らなくなってどんどん身近になっていきますし、これから育つ「AIネイティブ」世代にとってAIを乗り回すのは当たり前になります。
AIなどすべて使いこなしたうえで何をするか・何を見出すかに価値が生まれるのは間違いありません。
「ChatGPTすげえ~! これからはAIの時代! AIスキルを身に付けよう! まずはデータサイエンス! プログラミングで副業月10万!」などなど騒ぐのもよいですが、もっと本質的なところを磨いていかないと、それこそAIにとってかわられてしまうな、と感じました。
……だからクリエイティブ試験に落ちたんだな!(理解
今日はここまでです。
この記事が気に入ったらサポートをしてみませんか?