
条件によって保育士バンクの求人情報をスクレイピングする

保育士バンクとは?
保育士バンク!(運営:株式会社ネクストビート)は、これまでに30万人以上の保育者さんにご利用いただいてきたサービスです。また、個人情報を適切に扱う「プライバシーマーク」の認証を受け、情報管理を徹底しています。求人数は業界最大級だから、月給25万円以上、休暇がとりやすい、小規模保育、福利厚生充実などの人気求人はもちろん、地方在住、男性保育士、ブランク有り、未経験可など、あらゆるご要望にお応えいたします!
スクレイピングツールの概要
ScrapeStormとは、強い機能を持つ、プログラミングが必要なく、使いやすく人工知能Webスクレイピングツールです。違う基盤のユーザーに二つのスクレイピングモードを提供し、1-Clickで99%のWebスクレイピングを満たします。ScrapeStormにより、大量のWebデータを素早く正確的に取得できます。手動でデータ抽出が直面するさまざまな問題を完全に解決し、情報取得のコストを削減し、作業効率を向上させます。
抽出されたデータは下記のようにご覧ください

1.タスクを新規作成する
(1)URLをコピーする
今回は求人一覧ページを例として、スクレイピング方法を紹介します。まず、URLをコピーしてください。

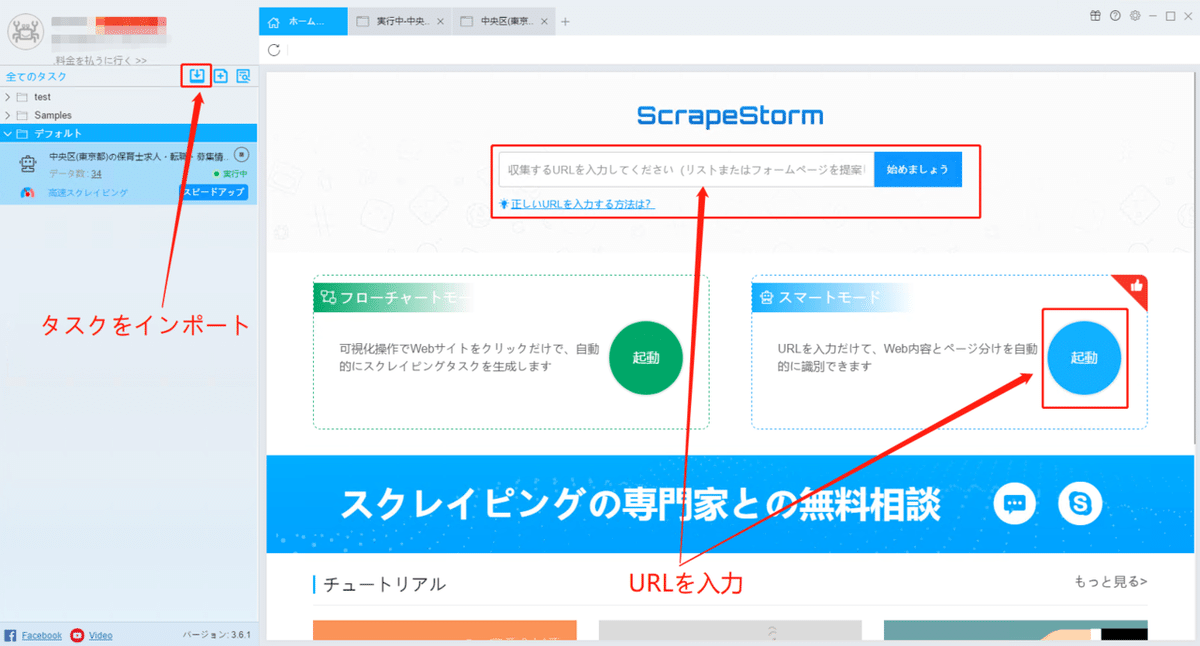
(2)スマートモードタスクを新規作成する
ScrapeStormのホムページ画面にスマートモードタスクを新規作成します。また、持っているタスクをインポートすることもできます。
詳細には下記のチュートリアルをご参照ください。
スマートモードタスクの新規作成方法
2.タスクを構成する
(1)事前操作
右上の緑ボタンをクリック、事前操作画面でコンポーネントを追加して、求人の条件を追加できます。各コンポーネントの紹介は下記のチュートリアルをご参照ください。
行動コンポーネントとは

(2)リスト要素
自動識別されたリストは誤差がありますから、Xpathを編集してください。
/html/body//section[contains(concat(' ', normalize-space(@class), ' '),' search-result--list ')]/div

(3)ページボタン
ページボタンの識別にはXpathが必要です、下記のようにご確認ください。チュートリアル【ページ分けの設定方法】もご参照してください。
/html/body/div[@id='main']/div[@id='search-result']/div[@class='main__container']/div[@class='main__container__col--left']/section[@class='search-result--list']/div[@class='pager']/a[@class='pager__link--forward']
(4)詳細ページに行く
抽出されたリンクをクリックして、求人の詳細情報ページに移動します。会社の所在地、定員などを抽出できます。

(5)フィールドの追加と編集
「フィールドを追加」ボタンをクリックして、画面に必要な要素を選択、データが自動的に抽出されます。また、必要に応じてフィールドの名前の変更または削除、結合できます。フィールドの設定の詳細には下記のチュートリアルをご参照ください。
抽出されたフィールドを配置する方法

3.タスクの設定と起動
(1)起動の設定
必要に応じて、スケジュール、アンチブロック、自動エクスポート、写真のダウンロード、スピードブーストを設定できます。
スクレイピングタスクを配置する方法については、下記のチュートリアルをご参照ください。
スクレイピングタスクを配置する方法

(2)しばらくすると、データがスクレイピングされる。

4.抽出されたデータのエクスポートと表示
(1)エクスポートをクリックして、データをダウンロードする
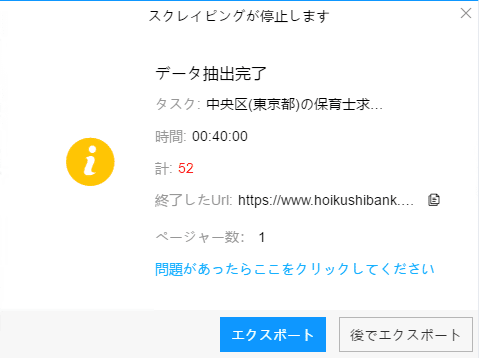
(2)必要に応じてエクスポートする形式を選択します。
ScrapeStormは、Excel、csv、html、txt、データベース、ローカルなどさまざまなエクスポート方法を提供します。ライトプラン以上のユーザーは、WordPressに直接投稿することもできます。
抽出結果のエクスポート方法の詳細には下記のチュートリアルをご参照ください。
抽出されたデータのエクスポート方法

この記事が気に入ったらサポートをしてみませんか?