
データ関係者が行うべき匿名化の基本

はじめに
個人情報保護が求められる現代において、データの匿名化は非常に重要なプロセスです。特に、個人情報が大量に含まれるデータセットを扱う場合、そのデータをどのようにして匿名化し、適切に利用するかが課題となります。本記事では、2つの匿名化手法やリスクベースの非特定化方法論に基づく具体的な実装手法について、SQLを用いて解説します。
個人情報とは
「個人情報」とは、生存する個人に関する情報であって、当該情報に含まれる氏名、生年月日、その他の記述等により特定の個人を識別することができるもの(他の情報と容易に照合することができ、それにより特定の個人を識別することができることとなるものを含む。)、又は個人識別符号が含まれるものをいいます。
よくある個人情報の誤解
特定の文字を直接識別する情報だけが個人情報ではありません。
当該情報に含まれる氏名、生年月日その他の記述等(文書、図画若しくは電磁的記録(電磁的方式(電子的方式、磁気的方式その他人の知覚によっては認識することができない方式をいう。次項第二号において同じ。)で作られる記録をいう。以下同じ。)に記載され、若しくは記録され、又は音声、動作その他の方法を用いて表された一切の事項(個人識別符号を除く。)をいう。以下同じ。)により特定の個人を識別することができるもの(他の情報と容易に照合することができ、それにより特定の個人を識別することができることとなるものを含む。)
個人情報のよくある誤解の1つに「直接的に個人を特定できる情報のみか個人情報」という考え方があります。名前、生年月日、その他の特定できるものだけを個人情報と考えてしまうと、本来守るべき個人情報の範囲を間違えたり、不適切な匿名化につながる恐れがあります。
また、下記でも紹介しますが、適切な加工を行った匿名加工情報にする必要があります。
匿名加工情報とは
匿名加工情報とは、特定の個人を識別することができないように個人情報を加工し、当該個人情報を復元できないようにした情報のことをいいます。

個人データを単にマスキングしただけで、法令に定める適切な加工を行っていない場合は、匿名加工情報ではなく、個人データです。匿名加工情報は、以下で紹介している事業者の適切な加工を行ったものを指します。
特定の個人を識別することができる記述等の全部又は一部を削除(置換を含む。以下同じ。)すること。
個人識別符号の全部を削除すること
個人情報と他の情報とを連結する符号を削除すること
特異な記述等を削除すること
上記のほか、個人情報とデータベース内の他の個人情報との差異等の性質を勘案し、適切な措置を講ずること
匿名化の手法
匿名化には2つの手法があります。
一つは、マスキング(masking)、もう一つは非特定化(de-identification)です。
①マスキング
マスキングは、データセット内の個人識別情報を隠す方法です。具体的には、データの一部を隠す、削除する、または変換することを意味します。 分析に必要のないフィールドを保護するもので、オリジナルのデータを完全に隠します。
通常であればマスクされたフィールドを用いて分析をすることは無いため、問題になる可能性は低くなります。
メリット
データプライバシーの保護: 個人情報や機密情報を保護し、法規制(GDPRなど)に準拠できます。
セキュリティリスクの低減: データ漏洩時の影響を最小限に抑えられます。
デメリット
データの有用性が低下: マスキングによって隠された情報が重要な場合、データの有用性が低下する可能性があります。
以下のフィールド秘匿は、センシティブなデータを固定の文字列や記号で置き換えます。これにより、実装が簡単で、データの存在を示しつつ内容を完全に隠蔽できます。
-- 1. フィールド秘匿
SELECT
id,
'XXXXX' AS masked_name,
'***-***-****' AS masked_phone,
email
FROM
customers;ランダム化は、元のデータを、同じ形式や特性を持つランダムな値で置き換えます。これにより、データの統計的特性を維持しながら、個別の値を保護できます。
-- 2. ランダム化
SELECT
id,
CONCAT(
CHAR(65 + FLOOR(RAND() * 26)),
CHAR(65 + FLOOR(RAND() * 26)),
CHAR(65 + FLOOR(RAND() * 26)),
CHAR(65 + FLOOR(RAND() * 26)),
CHAR(65 + FLOOR(RAND() * 26))
) AS random_name,
FLOOR(1000000000 + RAND() * 9000000000) AS random_phone,
email
FROM
customers;仮名化は、識別子を、元の値と一対一で対応する別の識別子(仮名)に置き換えます。これにより、データの関係性を保ちつつ、直接的な個人識別を防ぐことができます。
-- 3. 仮名化
SELECT
id,
CONCAT('User_', SHA2(name, 256)) AS pseudonym_name,
CONCAT('Phone_', SHA2(phone, 256)) AS pseudonym_phone,
email
FROM
customers;②非特定化
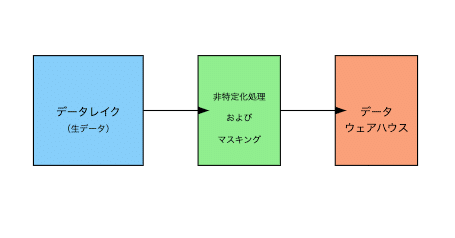
非特定化とは、個人を特定できる情報を取り除くか変換することで、データセットから個人を識別できないようにするプロセスです。これは、データのプライバシーを保護しつつ、そのデータの分析や研究、開発などの目的での使用を可能にするプロセスです。
分析に必要なフィールドを保護するもので、プライバシーと有用性に関してトレードオフがあります。
メリット
データ活用の促進:プライバシーを保護しつつ、データの分析や研究が可能になります。
法令遵守:GDPRなどのデータ保護法に準拠しやすくなります。
デメリット
再特定のリスク:他のデータソースと組み合わせることで、個人が再特定される可能性があります。
実装の複雑さ:効果的な非特定化には高度な専門知識が必要です。
非特定化をする手法はいくつかあります。詳しくは下記で紹介します。
非特定化
非特定化にはいくつかのアプローチがあります。そのアプローチの中でも代表的な非特定化方法論を紹介します。
非特定化方法論とは
非特定化方法論は、データセットから個人を特定できる情報を削除または変換するプロセスの体系です。リスクベースのアプローチを採用し、データの利用時のリスクを総合的に評価し、最小限のリスクでデータを利用可能にすることを目指します。。
以下に、リスクベースの非特定化方法論に基づく具体的なステップをSQLを用いて説明します。
非特定化のアプローチ
非特定化のアプローチには、一般化、秘匿、サブサンプリングの3つの方法があります。
1. 一般化
一般化は、データの詳細レベルを減らすことによって特定の情報を隠す手法です。たとえば、年齢を年代に一般化したりすることが挙げられます。
CREATE VIEW generalized_customers AS
SELECT
id,
CASE
WHEN age < 20 THEN '0-19'
WHEN age BETWEEN 20 AND 39 THEN '20-39'
WHEN age BETWEEN 40 AND 59 THEN '40-59'
ELSE '60+'
END AS age_group,
FROM
customers;2. 秘匿
秘匿は、データをランダムな値に変換して特定の情報を隠す手法です。たとえば、名前をランダムなIDに置き換えることが挙げられます。
CREATE VIEW suppressed_employees AS
SELECT
id,
name,
NULL AS birth_date,
salary
FROM
employees;3. サブサンプリング
サブサンプリングは、データセット全体を使用するのではなく、ランダムなサブセットを使用することによって特定の情報を隠す手法です。
CREATE VIEW subsampled_employees AS
SELECT
id,
name,
birth_date,
salary
FROM
employees
WHERE
id % 2 = 0;まとめ
マスキングは、分析に必要のないフィールドを保護するもので、オリジナルのデータを完全に隠します。非特定化は、分析に必要なフィールドを保護するもので、プライバシーと有用性に関してトレードオフがあります。
リスクベースの非特定化方法論は、データのプライバシー保護と利用価値のバランスを取るための効果的なアプローチです。SQLを用いることで、データセットの内容を把握し、識別リスクを評価し、適切な匿名化手法を適用することができます。
個人情報の再特定リスクを最小限に抑えつつ、データのセキュリティを強化する必要があります。
関連書籍
機微な個人情報を多く含むヘルスデータを題材に、プライバシー保護とデータ有用性という相反する命題をいかに満たすかについて、豊富な実例とともに解説する書籍です。
「仮名化/匿名化」「差分プライバシー」「秘密計算」の3つの主要技術を扱う書籍です。
この記事が気に入ったらサポートをしてみませんか?