
AWSで文字起こしをしたjsonファイルをMAXQDAで読み込む手順

質的研究では,言語データを扱う特性上,インタビュー等で収集した音声データを文字起こしすることが多くあります.短いデータであればそのまま手作業で行うこともあまり手間にはなりませんが,数十分〜数時間のデータとなると,かなりの時間をとられます.
ここでは,AWS(Amazon Web Service)で音声データを文字起こししたファイルを,QDAソフトのMAXQDAに,扱いやすい形でインポートするための手順について,備忘録代わりに書き留めておきます.
作業環境 Mac Book Pro(2019),macOS Big Sur ver11.4 , MAXQDA2020 Analytics Pro,python ver.2.7.16(3系推奨ですが,2系でも問題なく作業できています)
※以下の作業はMAXQDAで公式にサポートされている方法ではありません.あくまでも自己責任でお願いします.
まずはICレコーダー等で録音したファイルをAWSのAmazon Transcribeで文字起こしをします.Amazon transcribeに音声データを直接アップロードすることはできないので,最初にS3(AWSのクラウドストレージ)に音声ファイルをアップロードします.S3へのファイルのアップロード方法は以下のリンクを参照してください.
Amazon S3 でのオブジェクトのアップロード、ダウンロード、操作
次に,Amazon TranscribeでS3にアップロードした音声ファイルの文字起こしを行います.方法の詳細は以下のリンクを参照してください.
音声を文字起こしする(Amazon Transcribeを使用)
※無料アカウントでも,最初の12ヶ月は,毎月60分間の音声データを無料で文字起こしできます(2021.07.21現在).詳細はAWSで確認してください.無料分を超過しても,格安で文字起こしが可能です.料金の目安は以下を参照してください.
文字起こしが完了したら,S3のバケットから,文字起こしされたファイルをダウンロードします.拡張子は(json)です.
このままではMAXQDAに読み込むことができません.jsonファイルをテキストエディットで開き,Wordにコピー&ペーストしてMAXQDAにインポートすることは可能ですが,話者やタイムスタンプが識別されず,その後の作業が非常に面倒になります.
ここからは,S3からダウンロードした文字起こししたjsonファイルを,MAXQDAで扱いやすい形に変換する作業について説明していきます.
まず,有志によって作成されたPythonコード,aws-transcribe-transcript を使用しますので,下記URLより、transcript.pyを入手します。
https://github.com/trhr/aws-transcribe-transcript
transcript.pyファイルを入手したら,フォルダを1つ作成し,その中にtranscript.pyファイルとS3からダウンロードしたjsonファイルを入れます.フォルダは任意の名前をつけて好きな場所に保存してください.
次に,Macのターミナルを開きます.Spotlightで「ter」と入力するとすぐにターミナルアプリを開くことができます.

ここからは,①さきほど保存したフォルダの場所まで移動して,②さきほど入手したtranscript.pyを実行することで,文字起こししたjsonファイルを扱いやすいテキストファイルに変換し,③データを綺麗に整えてMAXPDAにインポートする.するという流れで進めていきます.
①フォルダの場所まで移動する
まず,今回は基本的なコマンド3つを使用します.cd(change directory):別の場所に移動する.pwd(print working directory):いま自分がいる場所を確認する.ls(list segments):いま自分がいる場所に何があるのかを確認する.cd だけでも作業は可能ですが,ターミナル上の作業に慣れていないと,正確に作業できているか不安になるものです.途中で作業が正確にできているかを確認するために,今回はpwdとlsも使用します.
ためしに自分がいる場所を確認します.「pwd」と半角で入力します.※スペースなどは入れずにそのまま入力します.
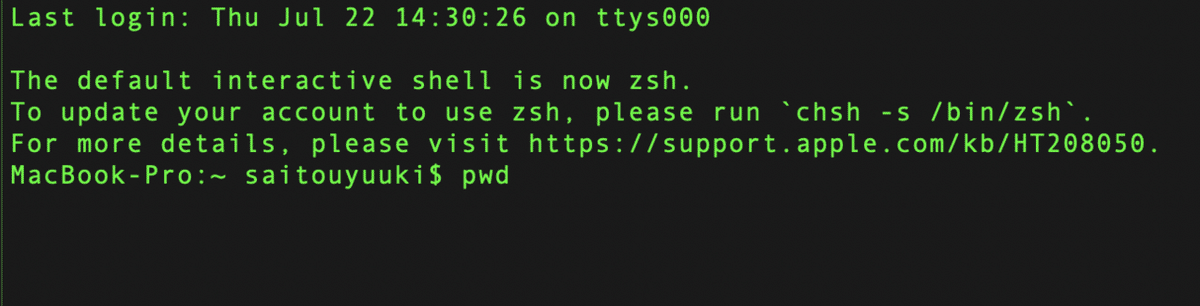
入力したら実行「return」します.
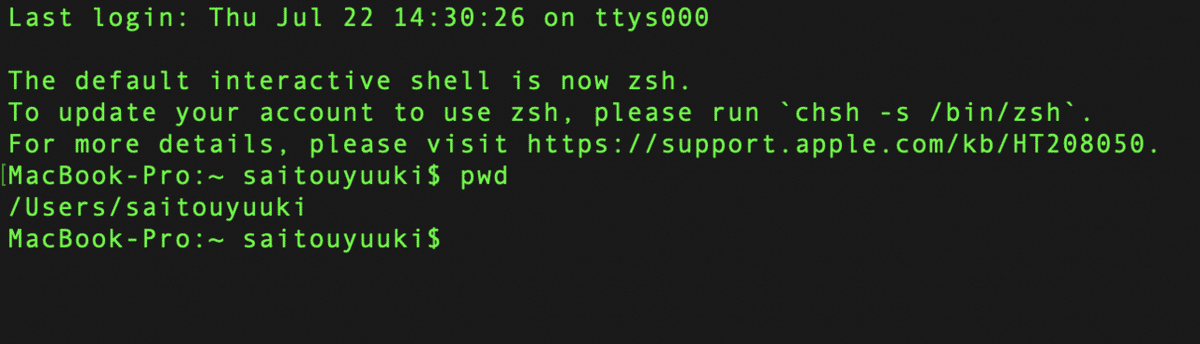
いまいる場所が表示されました.次は,さきほど保存したフォルダがある場所に移動していきます.私の場合,Dropbox → 20_研究 → MAXQDA の中に,transcript というフォルダ名で保存しているので,そこまで移動していきます.最初にDropboxに移動します.ターミナルに cd(半角スペース)Dropbox と入力して実行します.
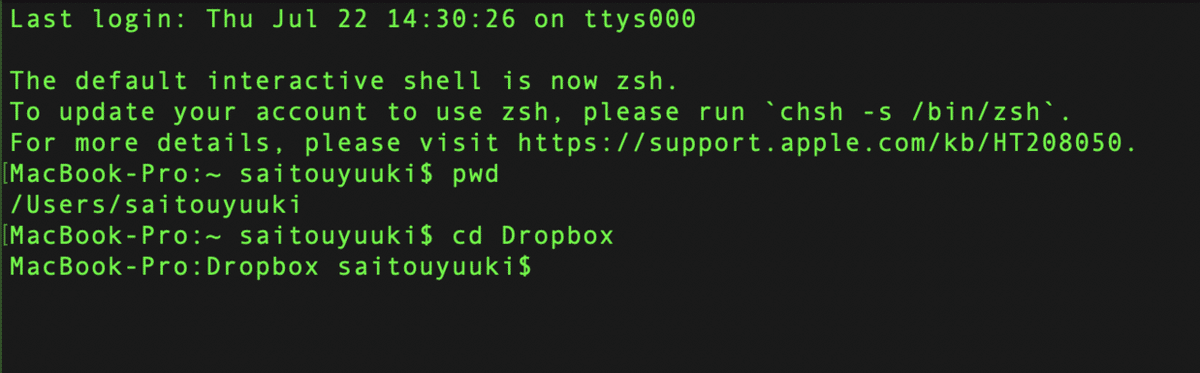
つぎは,20_研究 フォルダに移動します.上記同様に,cd(半角スペース)20_研究 と入力し,実行します.
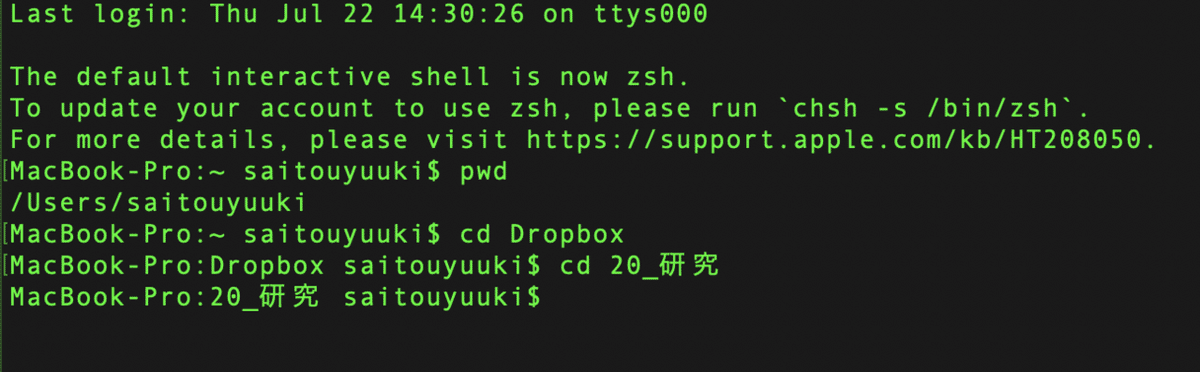
同じ手順で,MAXQDAフォルダに移動します.cd(半角スペース)MAXQDAと入力し,実行します.
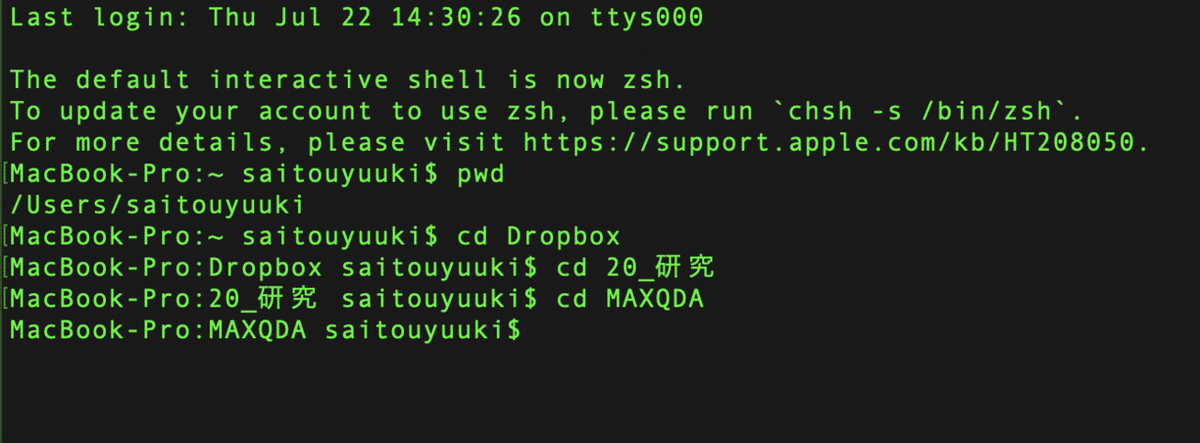
次に,さきほど作成した transcript フォルダに入ります.手順は全く同じです.cd(半角スペース)transcript と入力し,実行します.
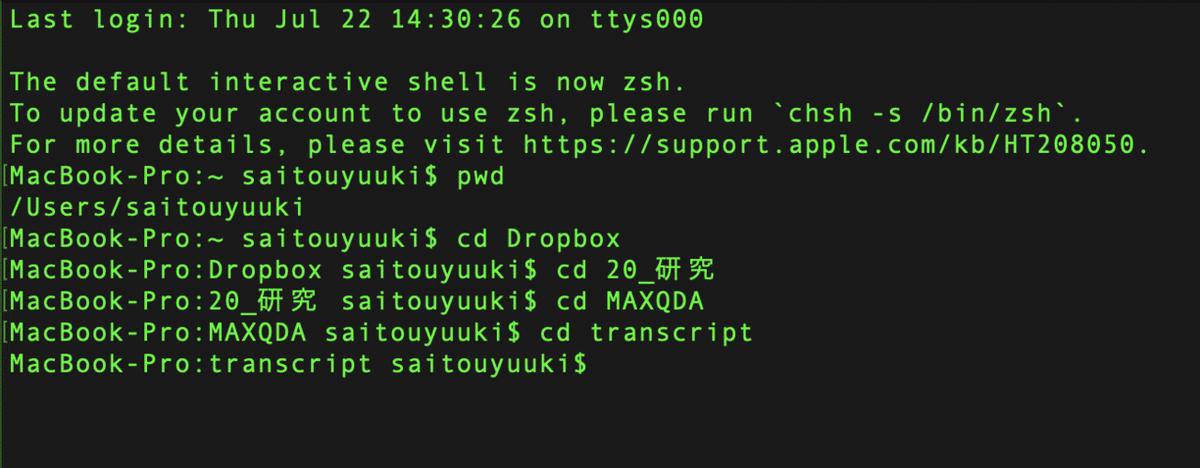
これでさきほど作成したフォルダの中に入ることができました.本当に入れたかどうか確認するためには,上述したpwdを入力します.
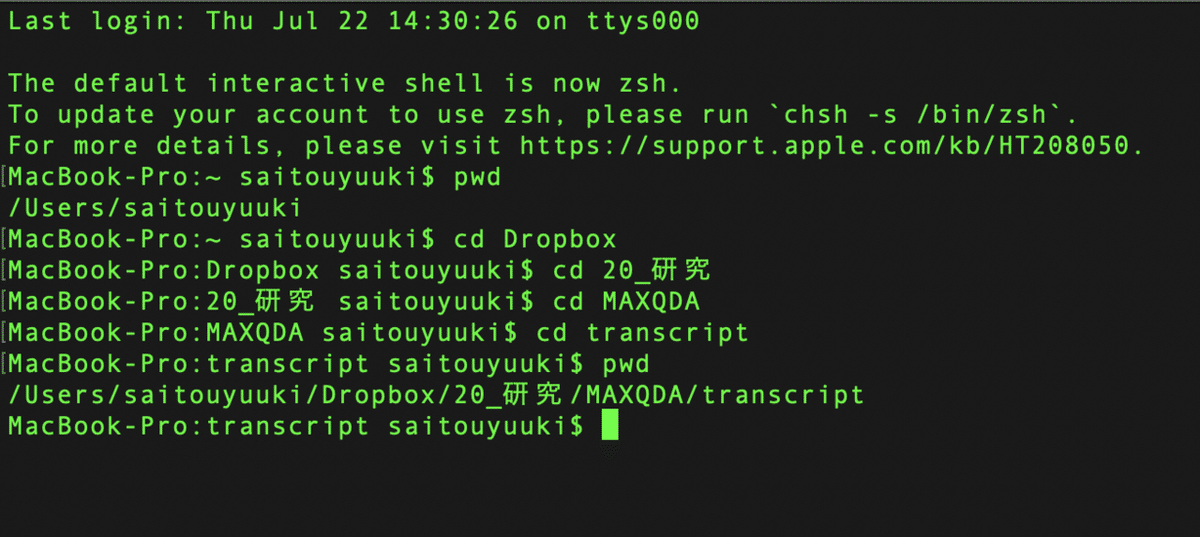
ためしにpwdを入力して実行した画面です.下から2行目を見てみると,Dropbox→20_研究→MAXQDA→transcript とフォルダの階層を潜ってきたことがわかります.pwd ではいま自分がいる場所を確認できますが,lsと入力すれば,いまいる場所にどのようなファイルが保存されているのかを確認することもできます.
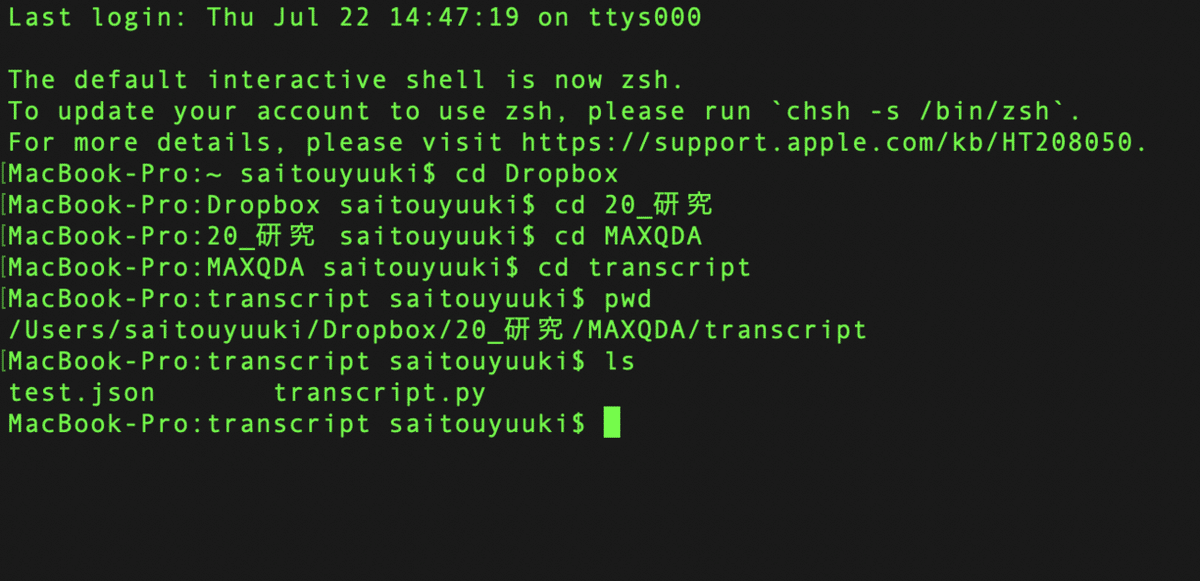
ためしに ls と入力し実行してみました.作成したtranscript フォルダに,ファイルが2つ(test.json,transcript.py)保存されているのが確認できます.test.jsonファイルがAWSで文字起こししたファイルになります.
②transcript.pyを実行して文字起こししたjsonファイルを変換する.
いよいよjsonファイルを変換する作業に入ります.ターミナルに,python transcript.py(半角スペース)test.jsonと入力し実行します.

これでファイルが変換されました.ターミナルを閉じて,Finderからフォルダを確認してみます.
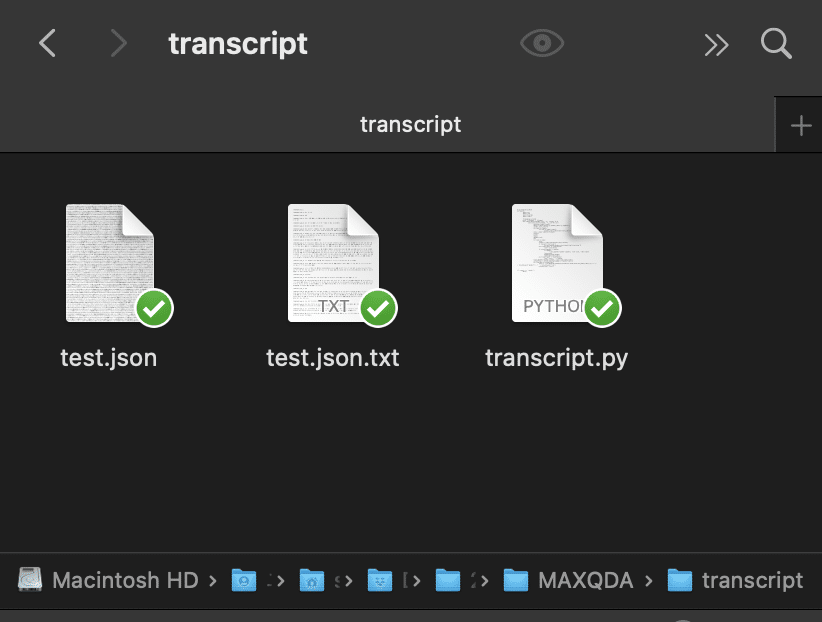
test.jsonとtranscript.pyに加えて,test.json.txtという名前のテキストファイルが作成されているのが確認できます.これが変換されたファイルになります.
③データを綺麗に整えてMAXQDAにインポートする
このテキストファイルをそのままMAXQDAにインポートすることも可能ですが,Amazon transcribe が単語ごとに音声データを認識している関係で,単語と単語の間に大量の半角スペースが入ってしまっています.そこで,txtファイルを開き,全文選択(command+Aで一括選択)し,Wordに貼り付けを行い,半角スペースをすべて削除します.半角スペースは,Wordの置換機能で「検索と置換」に半角のスペースを入力し,置換後の欄に何も入力せずに「すべて置換」すればすぐに削除できます.
半角スペースを削除したWordファイルはそのままMAXDQAにインポートすることが可能です.今回は「フォーカスグループのトランスクリプト」から「タイムスタンプなしのトランスクリプト」を選択し,Wordファイルをインポートします.

無事にインポートすることができました(実際のインタビュー内容は塗りつぶしています).話者もしっかりと識別されています(spk_1.spk_0).

以上,AWSで文字起こししたデータをQDAソフトのMAXPDAにインポートする方法について説明しました.
おわり
この記事が気に入ったらサポートをしてみませんか?