
馬と鹿を見分ける画像認識AI

与えられた画像が「馬」か「鹿」かを見分けることができるAIを作りました。
命名、「馬鹿判定器」。
「ばかはんていき」ではなく「うましかはんていき」と読みます。
以下がデモサイトです:
馬か鹿の画像を選択して判定ボタンを押すと、AIがその画像を分析し、被写体が馬なのか鹿なのかを判定します。
ただし、今回は馬か鹿の全身または顔が写っている写真のみを対象としているので、尻尾しか写っていないものや食肉の状態になってしまっているものは正確に判定できません。
✽ ✽ ✽
本記事は、以前はてなブログに掲載したものを当時の情報(2019年9月13日時点)のまま移植したものなので、一部の情報が古くなっているかもしれません。ご了承ください。
https://yoshy-toshy.hateblo.jp/entry/2019/09/13/104230
本記事では、馬鹿判定器の作成方法を説明します。
実はこれを作る前に「金正恩第一書記」と「黒電話」とを見分けることができるAIを作ったのですが、まれに金同志を黒電話と誤認識するケースがあり、さすがにそれを一般公開すると無慈悲な鉄槌によって粛清されるおそれがあるので、代わりに「馬」と「鹿」を対象にして作り変えました。
なお、この判定器を改造し、判定対象とする画像の種類を「iPhone vs. Android」や「キャベツ vs. レタス」や「風神 vs. 雷神」のように変えれば、自分だけのAIモデルを作ることができます。
言語・フレームワークとして、PythonとTensorflowを使っています。 AIモデル構築ロジックなどは、かなりの部分を章末に掲げている記事を参考にして作成しました。
✽ ✽ ✽
つくりかた
以下の手順で作っていきます。
①ローカルで動かしてみる
②AI訓練用の画像を収集する
③ハイパーパラメータを設定する
④学習させる
⑤動作確認する
①ローカルで動かしてみる
馬鹿判定器を改造して独自のAIを作成する前に、とりあえず自分のPCでデフォルトの馬鹿判定器が動作するようにします。
馬鹿判定器のソースコードは以下にあります。
動作確認したバージョンは以下のとおりです。
python 3.6.8
flask 1.0.3
opencv-python 3.4.5.20
requests 2.22.0
tensorflow 1.13.1
※2019年9月12日現在、tensorflowはpython 3.7以上で動作しないらしいので、3.6を使用します。
まず、Githubから以下のリポジトリをクローンします。
$ git clone https://github.com/yoshy-toshy/horse-deer.git クローンが完了したら、horse-deerフォルダの中に移動し、web.pyを実行してローカルサーバを起動します。
$ cd horse-deer
$ python web.py不足しているパッケージがあって動かない場合は、以下のようなコマンドでインストールしてください。
$ pip install パッケージ名正常に起動すると、おそらく5000番ポートが開くので、以下のURLにアクセスします。
適当な画像を投稿して、結果画面が表示されたら成功です。
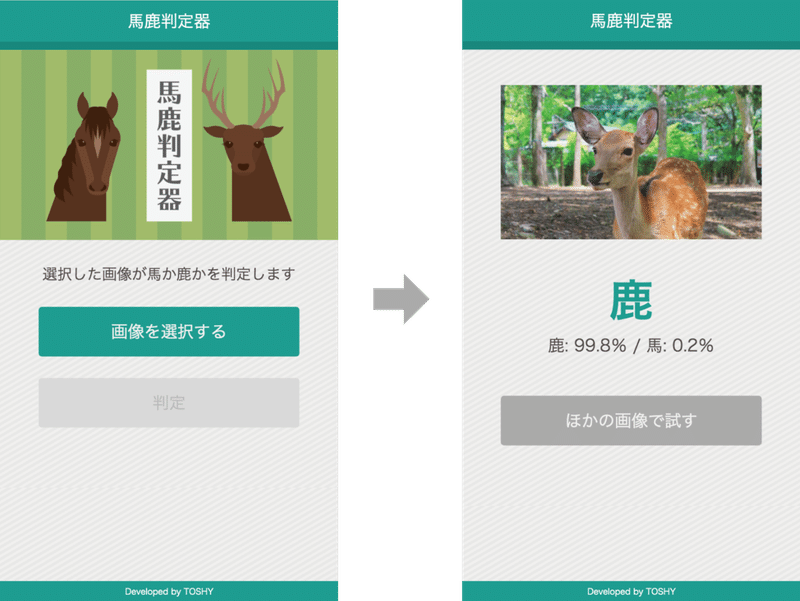
なお、馬の画像を投稿したのに鹿と表示されたり、鹿を投稿したのに馬と表示されたりしても、ロジック上は失敗ではありません。誤認識が起こるのは単にAIの精度の問題なので、きちんと上図のように判定結果が表示されれば一応原理どおりに動いていることになります。
②AI訓練用の画像を収集する
いよいよ任意の2種類の画像を弁別できるように、AIを訓練する方法を紹介します。
一旦、馬鹿判定器を作ったときのとおりに説明するので「馬」と「鹿」を対象に話を進めますが、たとえば「iPhone」と「Android」を弁別できるようにしたい場合は、それぞれ「馬」→「iPhone」、「鹿」→「Android」と読み替えてください。
まず、深層学習に用いるデータの種類には「訓練データ」「検証データ」「テストデータ」の3種類があります。
このうち、訓練データと検証データはAIモデルの作成や選定のために使用します。テストデータは作成したAIをテストするために使用します。
そもそも深層学習AIは、ラベル付けされた訓練データを教材として自ら思考回路をチューニングすることによって認識能力を洗練させていきます。訓練データはたくさんあればあるほど、さまざまなパターンに対応できるようにチューニングされます。
今回は馬と鹿の画像を大量に自動収集するために、以下のプログラムを利用しました。
仮に訓練データ250枚、検証データ50枚をAIモデル作成に使用したいとすると、少なくとも300枚は画像収集が必要です。このほか、テストデータを10枚確保しておきたいのと、使い物にならない画像が大量に混ざってくることを想定して、上の記事で紹介されているコマンドを借り、各500枚収集します。
$ python bs.py -t 馬 -n 500
$ python bs.py -t 鹿 -n 500集まった画像のうち、使い物になりそうなものを馬と鹿とで300枚ずつ選定し、以下のように4つのフォルダに配分して入れます。
フォルダ名 : ./data/train/0/
枚数:250
用途:分類番号0番(馬)の訓練データ
フォルダ名 : ./data/train/1/
枚数:250
用途:分類番号1番(鹿)の訓練データ
フォルダ名 : ./data/validate/0/
枚数:50
用途:分類番号0番(馬)の検証データ
フォルダ名 : ./data/validate/1/
枚数:50
用途:分類番号1番(鹿)の検証データ
テストデータについては、AIモデルが出来上がった後に動作検証も兼ねて手動で使用するので、適当なフォルダに入れておきます。
収集と分類が完了したら、以下のコマンドを実行します。このコマンドはフォルダ内のファイルを走査し、AIが学習に使うべきデータを列挙・分類したファイル ./data/train/data.txt と ./data/validate/data.txt を書き換えるものです。
$ python update_data.py③ハイパーパラメータを設定する
ハイパーパラメータとは、AIの訓練のために、あらかじめ人間側が設定してあげる定数のことです。
深層学習では、与えられた訓練データに基づいてプログラムが自ら結果導出ロジックをチューニングし、その範囲内でなるべく正解率が高くなるように試行錯誤を繰り返します。 このときに、1回に訓練データを何件ずつ選ぶのかや、それを何周行うのかといったトレーニングメニューのようなものを人間側で定数として指定することができます。このような定数のことをハイパーパラメータといい、ハイパーパラメータに何の値を設定するかによって、学習効率や学習結果が大きく変わります。
※ここでは説明のために「人間側が設定してあげる定数」と書きましたが、正確には「誰が設定するか」はハイパーパラメータの定義に含まれません。ハイパーパラメータをAIが自らチューニングする技術もあるようです。
各ハイパーパラメータの概念や調整方法については、「深層学習 ハイパーパラメータ」や「tensorflow ハイパーパラメータ」などでネット検索すれば、詳しい記事がいろいろ出てくるので、それを参考にしていきます。
馬鹿判定器では、main.pyの上部にまとめてハイパーパラメータを宣言しています。実際に馬鹿判定器用に使用した各種パラメータは以下のとおりです。
IMAGE_SIZE(学習に用いる画像の大きさ):28
PATTERN_SIZE(特徴点のパターンの大きさ):5
MAX_STEPS(学習回数):100
BATCH_SIZE(1回あたりに使用する画像の枚数。ただし、訓練データの枚数はBATCH_SIZEの倍数である必要がある):50
LEARNING_RATE(学習率。局所解に陥るのを防ぐための振れ幅):1e-4
NODES(各層におけるノード数): 3, 32, 64
KEEP_PROB(ドロップアウト層で何%ノードを残すか):0.4
一旦このまま学習させてみて、精度が悪かったらあとで適宜調整して再学習すれば大丈夫です。(ただし、BATCH_SIZEについては、準備した訓練データ数を等分できるような値にしてください。つまり、BATCH_SIZEは訓練データ数の「公約数」である必要があります。)
また、main.py のLABELSは、分類番号と判定対象物の名称の対応を定義しているので、「馬」と「鹿」の部分は必要に応じて書き換えておきます。
# Mapping between class number and label.
LABELS = collections.OrderedDict()
LABELS[0]="馬"
LABELS[1]="鹿"
④学習させる
これから学習を開始し、新しいAIモデルを作成します。すでに存在しているデフォルトの馬鹿判定器のAIモデルは不要なので、以下のコマンドによって削除します。
$ rm ./model/*modelフォルダを空にしたら、以下のコマンドを実行して学習を開始します。
$ python main.py下図のように学習が開始し、MAX_STEPS回だけステップが繰り返されます。学習が終わると、検証データを判定にかけたときの精度が出力されます。
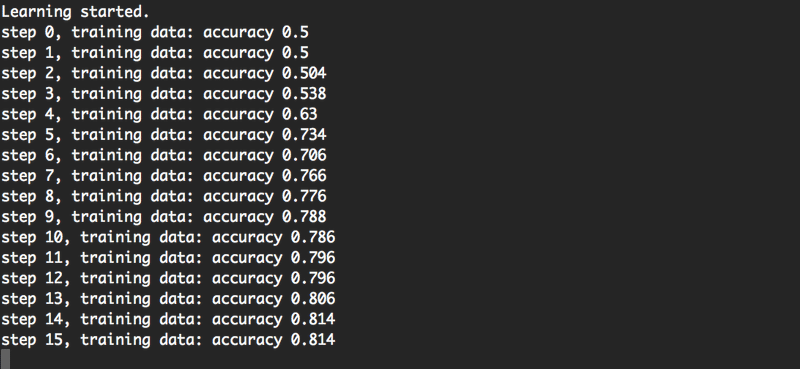
すべて完了すると、modelフォルダにAIモデルが生成されます。
なお、馬鹿判定器のAIモデルの精度は以下のとおりでした。この場合、学習に使用した画像ではほぼ99%判定に成功するのに対し、学習に使用しなかった画像は82%程度の正解率ということになります。
訓練データ(学習に用いた画像)での判定成功率:0.996
検証データ(学習に用いなかった画像)での判定成功率:0.820
⑤動作検証する
web.pyを実行してローカルサーバを起動します。
$ python web.py馬鹿判定器と同じように、一定の判定結果が表示されるようになっていれば完成です。
補足
Herokuにデプロイしたい人のためのメモを残しておきます。
このシステムは一部opencv-pythonを使っているのですが、Heroku上でopencv-pythonを動作させるためには、あらかじめ、Herokuの Settings > Buildpacks に以下のURLを登録しておく必要があるらしいです。
https://github.com/heroku/heroku-buildpack-aptこれを設定しておかないと、App crashedとだけ書かれた意味不明なエラーが発生します。
あとは通常どおり、アプリを新規作成してGithubと連携設定をすればすぐにデプロイできます。
参考記事
AIモデル構築ロジックについては、以下の方々のソースコードなどを下敷きに作成しました。
この記事が気に入ったらサポートをしてみませんか?