
may は might よりフォーマルかもしれないけれど日常会話で使わないということもないかもしれない

かなり前のことになってしまいますが,YouTube でこんな動画を見ました:
英語系 YouTuber として著名な Atsu さんの動画です.英語の助動詞 may と might は,双方ともに「~かもしれない」といった推論を表すのに用いられますが,教科書的には may の方が might より「確実性」が高い,という説明が一般的な説明かと思います.ところが Atsu さんは知人の英語ネイティブスピーカーに「may はフォーマルなので普段会話では使わない」「会話で使うとかなりフォーマルな印象を受ける」と言われたようで,そんな話は聞いたことが無い,別のネイティブスピーカーに確かめてみよう,という趣旨の動画となっています.
本日はこの問題について,言語学的に検証してみようと思います.
ネイティブが言うこと = 正解?
まず重要な点として,ついつい英語のことなのだから英語のネイティブスピーカーに聞けば全て解決する,と思ってしまいがちですが,実際はそうではないということを踏まえておく必要があります.
Atsu さんもそのことが分かっているので,少数のネイティブスピーカーの意見で納得してしまうことなく,様々な見解を聞いているわけです.
上の動画を観てもよく分かるように,英語であれ日本語であれ,ネイティブスピーカーというのは普段は意識せずにその言語を用いていて,いざ違いを説明してみろと言われても,なかなか説明するのは難しかったり,「こういうことだと思う」と説明してみても,実際はそう使っていなかった,つまり,本人がこうだと思っている「意味」や「使い方」と,実際の「使用」にギャップがある,ということもよく起こります.
さらに,そういうギャップが無かったとしても,一言で「〇〇語ネイティブ」と言っても多種多様で,地域や年齢,性別,職業などによってことばの使い方というのは微妙に (時には非常に) 異なってくるものです.「個人差」というものもあります.
そもそもの話,言語には「絶対にこうでなければならない」という「ただ一つの正解」というものは存在しないとも言えます.言語は絶えず変化するものですし,100人いれば100通りの「正解」が存在するとも言えます.言語というものは,「真実はいつも一つ」とは言えないものなのです.
※参考:
データを見る
言語学でも,フィールドワークなどでネイティブスピーカーに「こういう場合はどう言うか」「これとこれの違いは何か」といったその言語に関するさまざまな質問をすることで特徴を明らかにしていく,という手法 (elicitation と呼ばれます) が取られることはよくありますし,理論的な研究でも,ネイティブスピーカーが母語に対して持つ「直観 (intuition)」を利用してその言語の規則性を明らかにしようとするアプローチが用いられることも少なくありません.
ただその限界もまたよく知られており,それを補うために,大量の言語データを数量的に分析する,という方法がとられることも最近では一般的となっています.もちろんその背景には,大規模なデータベース (コーパス) の開発や高性能のPCの普及といった技術的な革新があります.
近年では,実際に誰かが書いたり話したりした言語データを集め,気軽に検索できるようにしたデータベース (コーパス) がいくつもあって,言語学でも,また恐らくは英語の学習者にもよく使われていると思われます.そのようなデータベースの一つに,Corpus of Contemporary American English (通称 COCA) というコーパスがあります.名前の通り現代アメリカ英語のデータを集めたもので,書籍や新聞記事,テレビ番組での発言やウェブ上の英語などを幅広く収録しており,実に10億語ものデータが含まれています.
may と might のジャンル比較 1
このコーパスを用いて,may と might の使用例を検索してみることにします.ただ検索するだけではあまり言えることが無いので,「新聞」「雑誌」「学術的な文書」「テレビ・映画」といった「ジャンル」毎に,may/might がどれくらい使われているのかを見てみることにします.検索結果は以下の通りです:


一つ目の図1 が may の検索結果,図2 が might の検索結果です."FREQ" というのが実際に何例使われていたか,ということ (= 頻度) を示していて,"PER MIL" というのがその頻度を「1000語あたり」に換算したものです.要するに,各ジャンル (例えば「新聞」) から1000語データを抜き出してきたときに,その中に may や might が何回登場するか,ということを表していると考えてください.縦棒のグラフは,この "PER MIL" の数値を棒の高さで表現しています.
ここから何が言えるか,ということですが,ざっくりと以下の3点が指摘できそうです:
全体的に may の方が might よりも頻度が高い (846,809 [may] vs 525,885 [might])
might の方が may よりも TV/M (= テレビ/映画) で使われる割合が高い
might の方が may よりも FIC (= フィクション) で使われる割合が高い
その他にも,上の3点ほど顕著ではないですが,may の方が might よりも ACAD (= アカデミック = 学術的な文書 [論文や学術書など]) で使われる割合が高い,ということも言えそうな気がしますし,逆に SPOK (= 話し言葉 [ただし日常会話などではなくテレビのインタビューなどが多い]) では might の方が may より割合が高いとも言えるかもしれません.
may と might のジャンル比較 2
さらに分かりやすくするために,比較的フォーマルなジャンルである ACAD (学術的な文書),MAG (雑誌),NEWS (新聞) をひとまとめにし,逆に比較的カジュアルなジャンルである SPOK (話し言葉),TV/M (テレビ/映画),BLOG (ブログ) もまとめて,その2グループの頻度を比較してみることにします.これを表にすると以下のようになります:
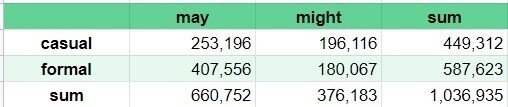
注目すべきは,may の列を見てみるとカジュアル (casual) なジャンルよりフォーマル (formal) なジャンルの方が頻度が高い (253,196 [casual] < 407,556 [formal]) のに対して,might の列をみるとその逆 (196,116 [casual] > 180067 [formal]) になっている,ということです.つまり,明らかに may はフォーマルな状況で使われる割合が高く,might はカジュアルな状況で使われる割合が高い,ということです.
しかし一方で,表を横に見てみると,どちらにしても may の方が頻度が高い,ということも分かります.これはつまり,カジュアルであろうとフォーマルであろうと,may はけっこう使われている,少なくとも might よりはたくさん使われている,ということが言えそうです.
別のコーパスも見てみる
ただ,COCA というコーパス自体が全体的にややフォーマルなデータに偏ったものだという可能性も否めないため,補助的に他のコーパスも見てみることにします.
COCA と同じく現代アメリカ英語を集めたコーパスではあるものの,話し言葉に特化した比較的カジュアルなデータを収録したものに,Santa Barbara Corpus of Spoken American English (通称 SBCSAE) というコーパスがあります.サイズは20万語ほどと COCA よりは随分小さいデータベースですが,大学の授業などのお堅いデータから,大学生の日常会話まで,比較的幅広くアメリカ英語の話し言葉を収録しています.
このコーパスで may/might を検索してみると,may は 87回,might は 121 回登場しているようです.COCAとは異なり,might の方が出現回数 (頻度) が多く,やはりカジュアルなデータを見ると might の方がより多く使われる,という傾向が見て取れるように思えてきます.
とは言え,may の 87回という数値も決して少なくないため,冒頭で紹介した動画で取り上げられていたネイティブスピーカーの言う「may は日常会話では使わない」という発言はやはり支持できないように思えます.
ちなみに may には,「かもしれない」という推量の意味と,「してもよい」という許可の意味があり,「日常会話では使わない」と言われているのはそのうち前者の「推量」の意味であろうと考えられます.従って,この 87回のmay の大部分が実は「してもよい」という許可の意味なのであれば,「推量の意味では日常会話では使わない」ということが示唆されるでしょう.しかし実際データを見てみると,may の用例のほとんどが推量の意味で用いられていて,許可の意味で用いられているのはほんの数例程度であることが確認できました.
なぜ「may は日常会話では使わない」と思われているのか?
ということで,実際の用例を幅広く集めてみると,「may はフォーマルなので普段会話では使わない」というネイティブスピーカーの評価は残念ながら (?) 支持されない,という結論が得られそうです.しかしここで気になるのは,いったいなぜ Atsu さんの周囲の英語ネイティブたちは「may は日常会話では使わない」と「思っている」のか,その感覚はどこから来るのか,ということです.
考えられることは2つあります.
1 つは,今回のように幅広くデータを見て得られる結果はあくまでも「平均値」的なものであり,一部の地域やコミュニティには,その「平均」とは異なる言葉遣いをする人々がいる,という可能性です.Atsu さんの周りのネイティブたちはたまたまそのような地域やコミュニティの人々だった,ということはありえなくはないかと思われます.上の方で述べた「個人差」の問題,と言い換えてもいいかもしれません.
もう 1 つは,データが示すように,絶対的な使用数としては may の方が might より圧倒的に多いにもかかわらず,話し言葉などカジュアルな文脈では may と might の差がさほど顕著ではなくなる,ということが関係している,という可能性です.つまり,感覚として「may の方が普通はたくさん使われる」という実感があるのに,日常会話ではその感覚に見合うほどは may が使われないため,「思ったより使われない」という意外性があり,その意外性が故に実際の使用数よりももっとずっと少なく感じられる,ということがありえる,ということです.普段よくしゃべっている人が若干口数の少ない日があったら, 実際は他の誰よりもしゃべっていたとしても,「この人今日は全然しゃべっていないな」と思う,というような現象と同じと考えればいいかもしれません.要するに,「期待値との差」が物を言う,ということです.
いずれにせよ,一部のネイティブスピーカーの感覚や,逆に一部のデータベースだけを見ていても,言語の実態を正確に把握することは難しい,ということは言えそうですし,ましてやネイティブスピーカーが感じている「言葉遣いに関する感覚」に関しては,もっとずっと複雑な要因が影響している,ということになりそうです.
まだまだ言語学者がやること,やれることは多そうです.
この記事が気に入ったらサポートをしてみませんか?