脳をくすぐるアート

(本記事は、電子情報通信学会 通信ソサイエティマガジンB-plusに掲載予定のエッセーをベースにして動画等を埋め込んだ形に再編集したものです。編集部の許可を得て公開します)
はじめに
動物学者でありシュルレアリスムの画家としても知られるデズモンド・モリスは、アートを「脳を楽しませるため、日常的なものから非日常的なものを作り出すこと」と定義した(1)。人文学的にもっと洗練された定義はあるだろうが、脳がアートに介在しているのは確かだろう。アート体験の基盤は、知覚・記憶・感情などに関わる脳の機能である。文化的・歴史的な解釈も重要だが、それらも脳にコードされる情報と考えることもできる。脳が美や醜にどのように反応するかを脳イメージング等を用いて解明する「神経美学」という研究分野も生まれている(2)。
アートの制作にも脳は不可欠であろう。手や指の運動は脳によって制御されているし、制作中の作品を評価しながら試行錯誤する過程でも脳は欠かせない。AIによる画像生成や文章生成の技術が近年急速に進歩し、人間のみがアートの創造性をもつのかについて活発に議論されている(3)。しかし、AIを脳の代替物、あるいは、脳を補完するものと位置づけている限りにおいて、アートにとっての「脳的なもの」の重要性は容易に失われそうにない。
アートに脳が介在していると言っても、脳が何をやっているのかを直接見ることは難しい。数百億の神経細胞(ニューロン)のネットワークからなる脳は、感覚入力と運動出力を担う限られた部位を通じて身体と接続しているに過ぎない。身体は外界と脳との間にある情報の「ボトルネック」であるとも言える。では、身体を介さず「ボトルの中」の脳とやり取りしながらアートを生み出すことはできるだろうか。これにより、身体的制約から人間の創造性を開放できるだろうか。あるいは、現在のアートとは別の何かになっていくのだろうか。
本稿では、私の研究室で行ってきた「脳内イメージ」を解読する方法を解説しながら、この研究成果をきっかけとして始まったアーティストとの交流を紹介したい。われわれの研究の目的は、脳が外界や心の状態をどのように表現しているかを理解することである。そのために、脳計測データから人が見ている画像やイメージを再構成する方法を研究してきた。技術的な性能不足や被験者の内部状態のゆらぎなどによって、予想外の出力が得られることがある。これが、見る人に奇妙な感覚をもたらしたのであろう。多くのアーティストやミュージシャンとの交流が生まれ、脳から生成した画像や動画がアート作品の素材として使われることとなった。
脳から生成されるイメージは、通常の意味で「きれい」「美しい」と感じるものではない。現代アート作品の多くも同様だろう。しかし、何か奇妙な感覚・面白さを感じさせてくれる。その状態を表すために、ここでは「脳をくすぐる」という表現を使ってみたい。
「くすぐったい」という感覚の一般的な特徴として、
特定の皮膚の部位や刺激パターンに敏感である(「ツボ」がある)
皮膚に虫が這うような「普通ではない」状態の検知に関わる
自分で自分をくすぐるのが難しいことが示唆するように、期待や予測が重要な要因である
嫌がりながらも笑ってしまうような、複雑な情動とリンクしている
などが挙げられる。アート体験と触覚的なくすぐったさが同じ生理学的メカニズムで生じていると主張するつもりはない。しかし、上記のくすぐったさの特徴は、現代アートに関わる中で体感したアートの楽しさと共通する部分が大きいと感じる。
神経美学では、美を感じるときに活性化する脳部位を調べる研究がある。しかし私は、「美の脳中枢」を活性化させるというより、もっと分散的でダイナミックな脳のプロセスがアートの楽しみとリンクしているのではないかと考えている。「脳をくすぐる」のさらに具体的なイメージを、脳やAIと対応させながら提示していきたい。
ブレイン・デコーディング
私のグループではヒトの脳活動パターンから知覚や心的イメージの情報を解読する方法を開発してきた。一連の研究を始めたのは、カリフォルニア工科大学でPh.D.取得後、ATRで職を得るまでの間、アメリカ東海岸を転々としていた時だった。2003-2004年に滞在したプリンストン大学で、学生時代からの友人のFrank Tongから機能的磁気共鳴画像(fMRI)によるヒトの脳活動計測を学んでいるときに、機械学習を用いた脳活動パターンの解析によって心の状態の解読するという着想を得た。通常の脳イメージングでは、感覚刺激や課題の違いによって信号強度に差が出る脳部位を同定するという手法が採られる。一つの脳画像には数十万もの画素あるので、ナイーブに統計検定するとノイズだけのデータでも数千個の画素で「統計的に有意な差」が出てしまう。補正する方法はあるものの、実際、偽陽性が疑われる信頼性の低い研究が多い。私が強く違和感を感じたのが、「刺激(S)→反応(R)」という因果図式を無理やり脳画像解析に当てはめたような方法論である。脳活動はたんなる「反応」ではない。脳活動は、筋肉を動かす「原因」にもなるし、外からの入力がなくても自発的に生じる。本来脳画像では一度にたくさんの画素値が得られるし、脳はネットワークとして機能しているのだから、「パターン」を使ったもっと自由なモデリングができるはずである。
そのときにヒントとなったのが、たまたま廊下を挟んで斜め向かいのオフィスにいたJames Haxbyの研究だった(ちなみに、隣がDaniel Kahnemanのオフィスだった。当時、現在アラヤの社長の金井良太さんを相棒として連れ回していて、同じオフィスを使わせてもらっていた)。Haxbyが2001年の論文で示した、多数の画素のパターンに含まれる情報というアイデアに触発され、機械学習によるパターン認識によってfMRI画像を分類するプログラムを開発した。これを用いて、図形の線の向きのような微細な脳構造に表現されていると考えられる視覚情報を、人が肉眼で見てもわからない複雑な脳活動のパターンから解読できることを発見し、2005年に発表した(4)。
この論文では、主観的経験内容を脳から解読すること(「ニューラル・マインド・リーディング」)ができることも示した。刺激画像を見せたときの脳活動パターンで訓練した機械学習モデル(デコーダ)を使って、心の中で想起している内容を予測できる。これは、画像を実際に見ているときと心のなかで想起しているときで、その内容が同じであれば同じような脳活動パターンが生じていることを意味する。これにより、客観的に確認できる条件で訓練したデコーダを使って、主観的な状態を脳から読み出せるのである。
これらの方法は現在「ブレイン・デコーディング」という名で呼ばれ、視覚に限らず、さまざまな心的情報を解読する方法として用いられている。脳データ解析に機械学習を使う研究は広く普及し、今ホットな神経科学とAIの融合研究(“Brain✕AI”や“NeuroAI”と呼ばれる)にもつながる。デコードした情報を用いて、機械やコンピュータを制御するブレイン−マシン・インターフェース(Brain-Machine Interface, BMI)を構成することもできる。大阪大学脳神経外科のグループと長年BMIの研究を進めているが、それについては別の機会に紹介したい。
付言しておくと、神経科学のデータ解析で機械学習が適切に使われているとは言い難い。機械学習モデルを評価をする際は、テストデータの情報をモデルの訓練時に使わない(データの「二度漬け」をしない)ことが原則である。二度漬けすれば「高い精度」が出て当たり前で、計測データをノイズに置き換えてもポジティブな結果が出てしまう。残念ながら、機械学習を使った神経科学の論文で、二度漬けをしていないことのほうが稀である。他にも結果を盛った報告が横行しており、研究分野の健全化が求められる。
視覚像再構成と「織合い」
当初のデコーディングでは、脳活動パターンを事前に選んだカテゴリーに分類するという方法をとった。そのため、訓練データの取得に用いたカテゴリーの情報しか読み出せない。脳から任意の視覚像を解読しようとすると、仮に10 ✕ 10ピクセルの2値(白黒)画像だとしても、2の100乗通りのピクセルの組み合わせ(可能な画像)があり、その全てについてあらかじめ訓練データを取得するのは現実的には不可能である。そこで、局所的な画像基底のコントラストを脳から解読した後、組み合わせて一つの画像を生成するという方法をとった。その結果、約400枚のランダム画像に対する脳活動データを用いてデコーダを訓練するだけで、どんな画像でも一定の精度で再構成できることがわかった(5)。ただし、このときは、10 ✕ 10ピクセルの2値画像を対象にしており、昔の粗い電光掲示板のような解像度だった。

2008年にこの研究を発表した数日後、インターネットの『虚構新聞』は、「脳内彼女も再現」という虚構記事をアニメ画像とともに掲載していた(図2)。これは、もちろん「ネタ」であるが、後述するように、最近のわれわれの研究は「脳内彼女」の再現に近づきつつある。
一方で、訓練時と同じ刺激をテスト時に使ったり、あらかじめ用意された候補から選択したりすることで「リアルな画像(映像)を脳から再現した」と称する後続研究が後を絶たなかった。低解像度であっても可能な画像(画素の組み合わせ)の数は天文学的である。訓練データや特定の候補から選択するのと、新たな画像の生成によって視覚像を再構成するのとでは問題が大きく異なる。これは最近のAIによる画像生成でも議論になる論点である。
この視覚像再構成が意外なところからアートにつながる。下に、グリッドペインティングで今注目の若手アーティスト川人 綾さんの作品と2008年の論文のFigure 2を並べた。絵柄、特に下部の白黒パターンが似ているのにお気づきだろうか。川人 綾さんのこの作品は、われわれの研究の影響を受けている。なぜそんなことが言えるかというと、川人 綾さんは、ATR脳情報通信総合研究所の川人光男所長、つまり、私の上司の次女で、この作品の制作時からやり取りをしていたからだ。


この作品は、川人 綾さんが東京藝術大学の大学院生の頃、フランスの SF 作家 Samantha Bailly の『Facettes』という小説をモチーフに制作した作品で、2017年にコルベール委員会と東京藝術大学が企画した「2074、夢の世界」プロジェクトでグランプリに選ばれている。『Facettes』は脳科学者が感情を映し出す技術を用いて、テクノロジーと伝統を融合したドレスを作る話である。このストーリーからインスピレーションを得て、ブレイン・デコーディングと日本の伝統的な染色が共存する作品ができたのだ。グリッドという単純な形態を何層にも重ねて描く方法は、わずかな「手作業のズレ」と「物質性によるズレ」を生じさせる。川人 綾さんの一連のグリッドペインティングは、人間の制御できる領域を超えたものを体感させることを試みている。
脳からの再構成画像に見られる「ズレ」は、アルゴリズムによる予測が不正確であることや脳活動のノイズやゆらぎが生み出したものであり、アルゴリズムの目標にとっては望ましいものではない。しかし、そこにアートとしての面白さを見出したのであろう。
現代神経科学の議論と若干強引に結びつけるとすると、脳の予測符号化とその誤差が生み出す感覚が、アートとしての面白さを生んでいるのかもしれない。脳が外界を認識するとき、感覚入力からの信号を受動的に処理しているのではない。予測符号化とは、脳はトップダウンで予測(仮説)を生成し、感覚入力との誤差を用いて仮説をアップデートしているという考え方である。19世紀の物理学者・生理学者のヘルマン・フォン・ヘルムホルツの「無意識的推論」を起源とするとされてきたが、最近では、10−11世紀のイスラムの自然学者イブン・ハイサム(アルハゼン)の影響をヘルムホルツが直接的に受けていたと言われている。川人光男所長も予測符号化に関連する先駆的な研究を行っていた。最近では、イギリスの神経科学者カール・フリストンが予測符号化を包摂する自由エネルギー原理を提唱し、脳と生命のあらゆる現象を説明できる原理であるかのように主張している。
自由エネルギー原理の当否はさておき、予測符号化の基本的なアイデアを再構成画像を見ている状況に当てはめると次のようになるだろう。再構成画像は、脳がトップダウンで期待するわかりやすい形とはずれていて、その誤差が脳の低次野から高次野に伝わり仮説がアップデートされる。しかし、記憶にあるモチーフとは合わないため、なかなか脳のダイナミクスが収束しない。このようにして脳が「くすぐられている」のかもしれない。
2018年に京都大学医学研究科の松田文彦教授のお誘いで、京都大学とシャネル株式会社主催の「科学と音楽の出会い」というイベントで講演する機会を得た。会場は、西園寺公望の私邸として建てられた清風荘で、当時の山極壽一総長、湊 長博現総長、金出武雄先生、シャネルのリシャール・コラス社長らと室内楽の演奏を聴き、アートとサイエンスについて語る楽しい時間を過ごした。このイベントの最中に判明したのだが、コラス社長は川人 綾さんのこの作品を気に入って購入されていたのだった。私はこのことを事前に知らなかったし、コラス社長も、川人 綾さんと私のつながりをご存じではなかった。アートに関わることで、このように世界が広がることをよく経験する。
脳と深層ニューラルネットワーク
視覚像再構成の研究では、画像を局所的な領域のコントラストの組み合わせとして扱い、それぞれを脳から予測して統合するという方法で一つの画像を生成した。画像はピクセル値の組み合わせで一つに決まるが、画像を表現する方法は他にいくつもある。たとえば、フーリエ変換を用いると、さまざまな角度と空間周波数をもつ縞模様の組み合わせとして画像を表現でき、逆フーリエ変換により元の画像に戻すことができる。脳では、網膜のピクセル的局所表現から、徐々に複雑で大域的な特徴による表現に変換され、最終的には物体カテゴリーなどの意味的な情報が抽出されると考えられている。視覚像再構成で用いた脳の情報は、最低次レベルの特徴表現にすぎない。脳の視覚野全体の情報表現を利用することで、リアルな質感をもつ知覚像を再現したいと考え、私の研究室では2010年頃からコンピュータビジョン分野で開発された画像特徴量と脳との関係を調べていた。そんなとき登場したのが深層ニューラルネットワーク(Deep Neural Network, DNN)である。
DNNは従来のニューラルネットワークの階層を増やしたものである。ニューラルネットワークは、生物のニューロンの構造と機能を単純化したユニットから構成される学習システムで、古くから研究されてきた。しかし近年、計算機の性能の向上や大規模データの利用などの条件が整い、「深い」階層をもつネットワークの学習が実効的に可能であることが、劇的な性能の向上とともに示された。これが現在のAIブームにつながる。
視覚に関しては、福島邦彦先生の「ネオコグニトロン(Neocognitron)」から発展した畳み込みニューラルネットワーク(Convolutional Neural Network, CNN)によって、画像を入力としたときの物体認識精度が飛躍的に向上した(6, 7)。CNNでは、脳の視覚野のニューロンと同様に、局所領域を階層的に処理する構造が与えられるが、特徴を表現する重みパラメータは、大規模画像データセット(画像と正解の物体名)を用いた最適化によって決定される。このように訓練されたCNNの低次層のユニットには画像の単純な特徴が、高次層のユニットには物体カテゴリーに対応する意味的な情報が表現される。

われわれが欲しかったのは、その間の中間層のユニットの表現であった。中間層のユニットは、低次層のユニットのように数学的にわかりやすい関数で記述するのは難しく、一方で高次層のユニットのように言語ラベルを対応させることも難しい、「名もなきユニット」である。しかし、この中間層こそが、質感に満ちた知覚経験を表現するのに重要だと考えた。
そこで、自然画像をDNN(CNN)に入力したときの各階層・各ユニットの信号値を、同じ画像を見たときの脳活動から予測するデコーダを訓練したところ、一定の精度で予測できることがわかった。また、DNNの低次層は視覚野の低次層からよく予測でき、高次層は高次層からよく予測できる。つまり、DNNの階層的な情報表現と脳の階層的な情報表現に対応関係があることがわかった(8)。
この脳とDNNの対応関係は、同時期に複数のグループにより異なるアプローチで示され、これら一連の研究によって、汎用的な計算モデルとして使われるようになっていたDNNが、再び脳と関連付けられるようになった(9)。
しかし、コンピュータビジョンの分野で次々開発される新しい高性能DNNが、脳に似たものになっているかというと、そういうわけではない。DNNと脳の間の階層的な情報表現の類似性を定量化したわれわれの最近の研究によると、物体認識課題(画像中の物体を分類する課題)で高いパフォーマンスを示す最近のDNNほど、脳との類似性は低いことがわかった(10)。2010年代前半に開発された初期のDNNで、シンプルなアーキテクチャをもつものほど脳に似ている。最近の DNNは、ヒトや動物とは違った方略(たとえば、全体的な形状の認識ではなく、テクスチャの抽出に特化するなど)で、高いパフォーマンスを達成しているのかもしれない。
深層イメージ再構成
脳とDNNの相同性を利用して、視覚像再構成に再チャレンジした。上記の方法で、画像を見ているときの脳活動を同じ内容に対応するDNN信号値に変換(デコード)できる。そして、そのDNN信号値から、対応する入力画像を逆推定することで、見ている画像を再現できると考えた。2008年に発表した論文との違いは、DNN中間層の「名もなきユニット」に表現される情報を活用できることである。別の言い方をすると、2008年の手法では、DNNの低次層に相当する情報表現(局所的コントラスト)しか活用できていなかったのである。
DNN信号値を画像に逆変換する方法はいくつか考えられる。最初に試したのは、脳からデコードしたDNN信号値に近づくように入力画像の画素値を少しずつ更新していく方法である。
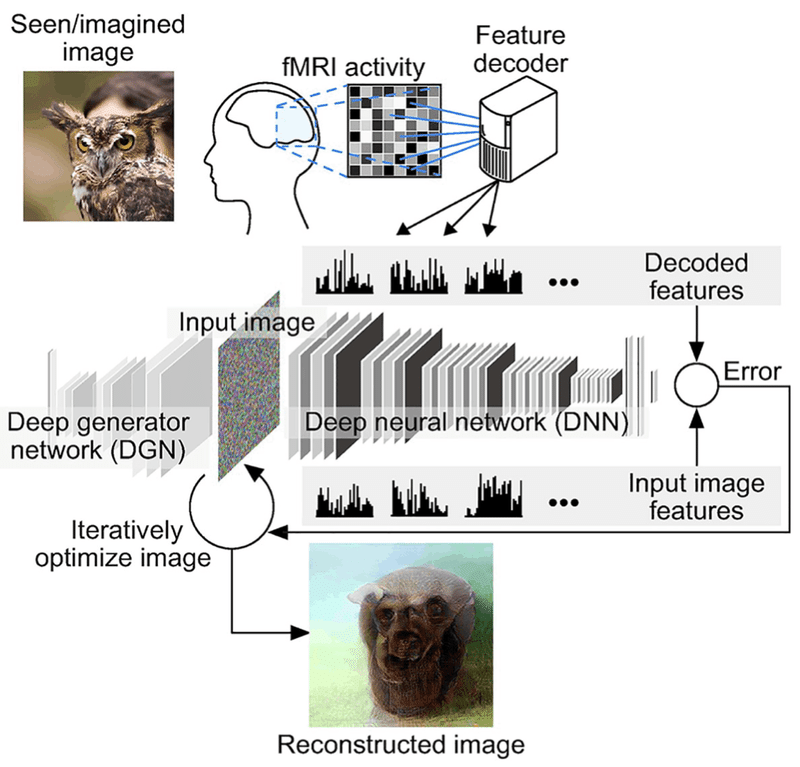
われわれがこの「深層イメージ再構成」に取り組んでいた2015年に、Googleのエンジニアが DNNの信号値を操作して同様の手法で悪夢なような画像を生成する技術“Google Deep Dream”を公開した(11)。また前後して、敵対的生成ネットワーク(Generative Adversarial Network , GAN)など、画像を生成するAIのブレークスルーが相次いだ(12)。われわれもこれらの手法を取り入れながら手法を改良し、写真を見ているときのfMRI脳活動から知覚像を再現することに成功した。
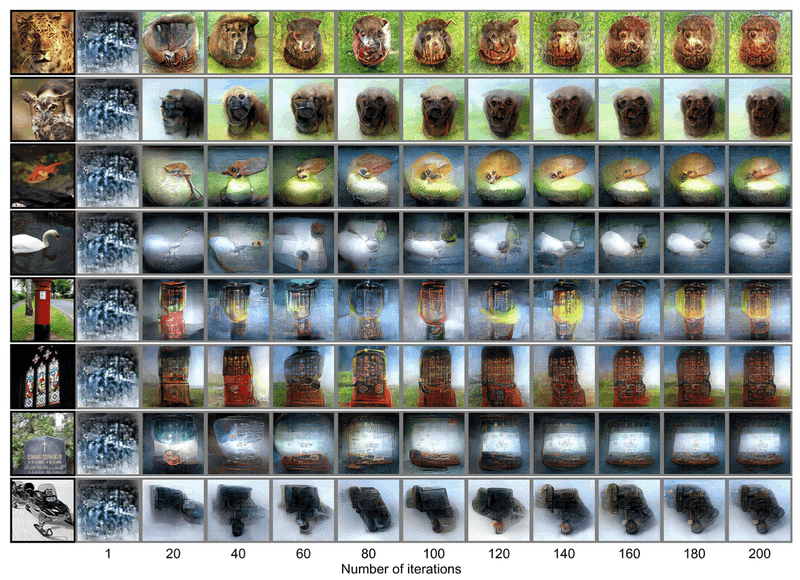
ピクセルレベルでは正確でないが、そのものらしさや質感とらえた画像が生成される。また、被験者が画像を想起しているときの脳活動からでも(つまり、実際に画像を見ていないときでも)、単純な図形であれば一定の精度でイメージを再現することができた。想起イメージの再構成は、それまでさまざまな方法でチャレンジしてきたが実現できていなかったが、DNN情報表現を用いることで初めて可能になった(13)。
川人 綾さんがモチーフに使ったSF作品のように、フィクションには古くから心の中のイメージを脳から画像化する技術が登場する。『マトリックス』や『アバター』といった人の脳に「ジャック・イン」する設定の作品では、脳内イメージの解読くらいはできて当然の世界が描かれている。村上春樹の1985年の小説『世界の終わりとハードボイルド・ワンダーランド』では、「意識の核の映像化」を実現したという老博士が登場する。その記述が深層イメージ再構成を予言していたかのようにも読める。
被験者に何かの物体を見せ、その視覚によって生じる脳の電気的反応を分析し、それを数字に置きかえ、それからまたドットに置きかえます。最初はごく単純な図形しか浮かび上がってこないが、何度も補整し、細部を付け加えていくうちに、それは被験者が見た通りの映像をコンピューター・スクリーンに描き出す。(14)
私は高校生のときに読んだはずだが、このような記述があったのは覚えていなかった。今読み返してみると、他にも現代の技術や社会を予言しているように読める箇所があり、作家の想像力や構想力に驚かされる。
脳と対応するDNN信号が得られるように入力画像の画素値を最適化するプロセスは、動物の脳に挿入した電極を使ってニューロンがどのような刺激に強く応答するかを調べる神経生理学者の作業と似ている。われわれの場合は、実際の脳の代わりに脳と対応するDNNを用い、コンピュータでその試行錯誤を自動化しているといえる。
同様の方法で刺激画像を自動的に最適化しながら、サルのニューロンがどのような画像特徴に強く応答するかを調べた研究もある(15)。高次視覚野には顔や物体の画像に応答するニューロンがあることが知られている。従来の分類では顔に応答するとされるニューロンの活動(スパイク数)を計測しながら、その活動値が大きくなるように画像を最適化していく。すると、スパイク数は顔に対する応答の倍以上となるが、一見して顔とわかりにくい奇妙な画像が生成される。これがそのニューロンにとっての「スーパー刺激」である。サルが被験者なので、その時どのような体験が生じたかを聞くことはできない。だがひょっとしたら、脳をくすぐられたアート体験のようなものが生じているかもしれない。
神経美学の創始者の一人で、もともと視覚神経生理学者であったセミール・ゼキは、抽象絵画の制作と神経生理学の営みの類似性を議論している(16)。たとえば、モンドリアンの抽象絵画は、それ自体が世界の状態を表現しているわけではない。複雑な世界のフォルムを構成する本質的な要素を見出そうとした結果生まれたのが、単純な線や色の配置によるモンドリアンの絵画だと考えられる。ゼキは、神経生理学者もニューロンの応答特性を調べることで、視覚世界を構成する普遍的な要素表現を見つけることを目指してきたとし、「視覚皮質の生理学とアーティストの創造との類似性がまったく偶然のものであるとは考えにくい」と述べている。
ノーベル賞受賞者で『カンデル神経科学』(神経科学の分厚い教科書)でも有名なエリック・カンデルは、アートと脳を論じた著書『なぜ脳はアートがわかるのか』で、抽象化する現代アートは要素的特徴に応答する脳メカニズムへの「還元主義」だと主張する (17)。この論にしたがえば、現代抽象絵画は、写実的な作品では体験できない新たな感覚を生み出すために、世界を要素に分解し、組み換えることで、「脳をくすぐる」ことを志向しているといえるだろう。
心理学者・神経科学者のV.S.ラマチャンドランは『脳のなかの天使』で「美の9法則」をまとめている(18)。その一つ「ピークシフトの法則」は、戯画や肖像画に見られるような誇張された表現が脳(ニューロン)を過剰に活性化させることで、美や魅力が生み出されているとする仮説である。「ピークシフト」とは自然界には普通存在しない刺激にピーク応答が見られることを指す。上記の「スーパー刺激」は、AIでピークシフトを自動的に生成したものといえる。脳が過剰に反応する「ツボ」を見出して重点的に刺激することもアートの重要な側面かもしれない。
ピエール・ユイグ「UUmwelt」
話を深層イメージ再構成にもどすと、この研究成果は2017年に「脳活動からの深層画像再構成」と題するプレプリントとして発表した(ジャーナル論文としては2019年に出版)。同時に、画像を最適化させながらイメージを生成するプロセスを記録した動画をYouTubeとtwitterにアップした(19)。
すると、一晩で数万回の動画の視聴があり、twitterのフォロワーが1000人以上増えた。海外の新聞やニュースサイトで多数取り上げられイギリスのタブロイド紙『The Sun』の記事にもなった。論文を最初に投稿しリジェクトされた科学誌『サイエンス』でも、ニュース記事として取り上げられた(編集チームが異なるのでそういうことは起こりうる)。多くのアーティストやミュージシャンからもコンタクトがあった。個人的にはAphex Twinの関係者からの問い合わせが嬉しかった。
なぜこれが受けたのか。アルゴリズムの目標は見ている画像を脳データから正確に再現することである。しかし、実際には技術的な制約もあり正確な再現とはならず、脳から読み出しやすかった視覚特徴が強調されることになる。結果として、鑑賞者の「ツボ」を刺激するような画像になっていたことが考えられる。もう一つ考えられる理由は、結果の見せ方に関係する。研究成果にとっては本質的ではないのだが、画像が最適化されるプロセスを映像化したことによって、視覚的な面白さが増強されたようだ。映像が変化することで、「理解した」と思った内容からのズレが常に生じる。
ホップフィールド・ネットワークと呼ばれる相互結合型ニューラルネットワークでは、状態がダイナミック変化しながら事前に学習したパターン(アトラクタ)に収束していく。実際の脳でもこのようなダイナミクスが生じているとすると、再構成動画は、アトラクタに収束しそうになったら入力が変化して別のアトラクタに向かような脳のダイナミクスを引き起こしているのかもしれない。
AI研究者のユルゲン・シュミットフーバーは、世界の状態にパターンや規則性を見いだすこと、すなわち、「情報圧縮」が脳内に内的報酬をもたらし、その結果、創造性や好奇心が駆動されるという説を唱えている(20)。この仕組みにより、情報圧縮の結果余った脳のリソースを利用して新たなパターンを探索するサイクルが生まれる。前述の予測符号化の文脈では、予測の不確実性が高いとき(規則性を見いだせていないとき)に予測に合致する結果が現れる場合や、逆に、予測の不確実性が低いとき(規則性をすでに見つけているとき)に驚きの結果が現れる場合に、快情動が誘発されるという知見がある(21)。音楽の場合、曲の展開が完全に予測通りでも予測不可能でも楽しくない。展開が徐々に予測できるようになることや、パターンを把握したあとにくる意外な展開が快をもたらす。脳の有限のリソースを節約しながら、新たなパターンや規則性の発見に向かわせるこれらの仕組みのせいで、思わず再構成映像を見続けてしまうのかもしれない。
さてそんな中、ギャラリストの那須太郎さんを介して、美術家のピエール・ユイグさんと知り合った。難解な現代アートの世界代表のような人物である。会う前は話が噛み合うか不安だったが、実際に会って話してみると、論文の技術的な理解も的確で、科学者的なマインドをもっている人であることがわかった。サイエンス、アート、哲学と話は弾み、数カ月後ロンドン・サーペンタイン・ギャラリーで開催される個展に協力することとなった。われわれが行ったのは、ユイグさんが送ってきた画像を使って脳計測を行い、再構成映像を作成することである。
その映像がどのように作品に使われたかを知らされないまま、2018年10月から始まった個展「UUmwelt」の内覧会に参加するためロンドンに向かった。現代アートに不案内なこともあり、当時ロンドン大学ユニバーシティカレッジのセミール・ゼキ先生のもとで神経美学の研究していた石津智大さんに声をかけ一緒に参加してもらった。その前日には、ゼキ先生の研究室を訪問しお話をする機会も得た。暖かく迎えてくださり、貴重な話をうかがうことができたが、私がやっていることを理解してもらえたかは自信がない。
サーペンタイン・ギャラリーの内覧会では、5つの大きなLEDディスプレーが配置され、そこに再構成映像が表示されていた。


正直なところ、最初見たとき「えっ、そのままじゃない?」と思った。映像は素材として利用されるだけで、形を変えて作品の一部となっているものと考えていたからだ。だが、作品にはひねりがあった。ギャラリーの室内に数千匹のハエが放たれていたのだ。「AIが解読したヒトの心の映像をハエが見ている」というコンセプチュアル・アートだったのである。
https://www.serpentinegalleries.org/whats-on/pierre-huyghe-uumwelt/
このコンセプトを理解してもらうには、タイトルの「UUmwelt」を説明する必要がある。これはドイツ語のUmweltにUを加えて、Un-Umwelt、すなわち、Umweltの否定を表すようにしたユイグさんの造語である。Umweltは環境を意味するドイツ語だが、生物学者のヤーコプ・フォン・ユクスキュルが提唱した概念(日本語では「環世界」)としてよく知られている。環世界とは、動物はそれぞれの種に特有な知覚世界を持っているという考え方である。ユクスキュルの著書『生物から見た世界 』の冒頭で示されるダニの例のように、視覚や聴覚が存在せず温度感覚と限られた嗅覚で構成された世界に住む生物もいる。おそらくハエもヒトとは全く異なる環世界に住んでいる。UUmweltはその世界の壁を取り除くことを表現している。
「ヒトとハエが心を通わせる」ということかというと、そういう意図でもないようだ。ユイグさんの作品の背景には、思弁的実在論やオブジェクト指向存在論と呼ばれる哲学がある。そこでは、実在や世界を人間の精神との関係を通して考える「相関主義」が批判される。Umwelt(環世界)の考え方も相関主義的だといえるだろう。「物自体にはアクセスできない」や「脳内に世界のモデルがある」といった、脳や心の問題に興味のある人にはわりと常識的な考え方を否定する「逆張り」の思想である。内覧会で行われたキュレーターのハンス・ウルリッヒ・オブリストさんとの対談で、ユイグさんは「人にものを展示するのではなく、逆に、ものに人を展示したい」と話していた。したがって、正確には(作家の意図としては)この作品は、「『AIが解読したヒトの心の映像をハエが見ている』のを来場者が見る」というものではない。来場者もその一部になって見られている。あるいは、見る・見られるという関係自体を否定して、人工物と生物と人がお互いに無関心にただ存在している状態を表現している。
最近私は、脳に表現される外界(脳内世界モデル)を「ニューロバース(neuroverse)」と名付け、ニューロバースの外在化・共有としてブレイン・デコーディングやブレイン・マシン・インターフェース(BMI)を再定義することを提案している。
私自身は、「見えている世界は脳が作り出したもの」という相関主義的発想にとくに疑問を持つことなく脳と心について研究してきた。ニューロバースという考え方もその延長線上にある。しかし、ニューロバースを外在化してしまえば、心の外も内もなくなる。ユイグさんはそのことに気づかせてくれた。
とはいえ、この作家の意図をUUmweltの展示を見ただけで理解するのは現実的には無理だろう。私の場合、作品の裏方を務め、作家本人から話を聞くことができたから上記のような「深い」解釈を知ることができたが、アートの専門家であってもこのような解釈にたどり着くことは難しいようだ。『ガーディアン』や『ニューヨーク・タイムズ』に掲載された美術批評家レビューは、読ませる内容ではあるものの、作家の意図を正確に読み解いているとは思えなかった。だが、現代アートの最先端はそういうものなのだろう。「不可解なものに脳をくすぐられ、情報を圧縮する解釈を与え、その結果、快情動が喚起される」プロセスが、キュレーターや批評家を巻き込みながらコンセプトレベルで展開されている、というふうに私は理解した。
UUmweltの内覧会後のパーティーは、アーティストやコレクターが集まる、今まで体験したことのない空間だった。宇宙旅行に連れて行くアーティストを探している某起業家の関係者もいた。石津さんと一緒に、ギャラリストの那須さんから「アートの価値」についてのレクチャーを受けた。マリーナ・アブラモヴィッチのパフォーマンスの権利売買や、自身のパフォーマンス作品を写真や映像などで一切記録しないティノ・セーガルの話など興味は尽きなかった。2019年に開催された『岡山芸術2019』では、那須さんが総合ディレクター、ユイグさんがアーティスティック・ディレクターを務め、そこでもUUmweltが展示された。

おわりに
本稿では、脳内イメージ解読を通じたアーティストとの交流を紹介しながら、脳とアートの関係を考察した。ツボとなる要素、非日常性、予測、情動との関わりなど、くすぐったい感覚との類似性から「脳をくすぐる」というキーワードを用いた。しかし、これらの特徴がアートを定義するものでもないし、脳だけでアートが完結するものでもない。とくにアートの価値を議論するときに社会的な次元を無視するわけにはいかないだろう。しかし、未来のアートの形を考えるとき、AIと神経科学が融合して「脳をくすぐる」新しい方法を生み出すことが一つの鍵になるのではないかと考えている。
脳内イメージ解読の研究は今も進展している。最近では、再構成画像の注意による操作(22)や錯視を見たときの主観イメージの可視化を実現した。
Visual images can be reconstructed from fMRI brain signals. Are they just about stimuli or about subjective percept? In this new preprint, work led by Horikawa-san, we show that given overlapping images as a stimulus (left), attention (to 'red') alters the reconstruction (right) https://t.co/QqKzw01hEq pic.twitter.com/V5wb41kuXd
— Yuki Kamitani (@ykamit) December 29, 2020
これまでの方法では、機械学習の訓練データ取得のため長時間の脳計測が各個人で必要となる。個人間で頭の形や大きさが異なり、詳細な脳表現も個人差があるので、ある個人で訓練したモデルを別の個人にそのまま適用することはできない。しかし、同じ内容を表現する脳活動を個人間で変換する「脳コード変換器」の研究も進めており、最近、これを介することで他者のデコーダを使って一定の精度で再構成が可能であることがわかった(23)。
New preprint from the lab (w/ Ho, Horikawa, Majima).
— Yuki Kamitani (@ykamit) January 3, 2022
Our previous visual image reconstruction from brain activity was based on models trained/tested on the same person. What if another person's trained model is used? https://t.co/4DNgiH5dKA pic.twitter.com/idpDspjFq2
今後さらに改良することで、アーティスト自身の脳活動を利用するなど、作品制作の自由度が大きくなることを期待している。
本稿では川人綾さんとピエール・ユイグさんの作品を取り上げたが、他のアーティストともコラボを行ってきた。イギリスのロックバンドSquidのアルバムのアートワークやミュージックビデオに素材を提供した。

サクライケンタさんがプロデュースを手掛けたMaison book girl『夢』のミュージックビデオにもわれわれが提供した「脳内イメージ」が使われている。
本稿では触れなかったが、私の研究室では睡眠中の脳活動から夢の内容を解読する研究も進めている。夢とアートとの接点を模索している。
ライゾマティクスの真鍋大度さんとは、実験的な作品づくりを続けている。こちらついては、また別の機会に紹介したい。
謝辞
脳内イメージ解読の研究と作品制作に参加した神谷研究室のメンバーと共同研究者に感謝します。本稿の執筆にあたり、国立研究開発法人新エネルギー・産業技術総合開発機構(NEDO, JPNP20006)のサポートを受けました。
参考文献・リンク
(1) デズモンド・モリス, 人類と芸術の300万年 デズモンド・モリス アートするサル. 柊風舎, 2015.
(2) 石津智大, 神経美学: 美と芸術の脳科学. 共立出版, 2019.
(3) 徳井直生, 創るためのAI 機械と創造性のはてしない物語. ビー・エヌ・エヌ, 2021.
(4) Y. Kamitani and F. Tong, “Decoding the visual and subjective contents of the human brain,” Nature Neuroscience, vol.8, no. 5, pp.679–685, May 2005.
(5) Y. Miyawaki, H. Uchida, O. Yamashita, M. Sato, Y. Morito, H. C. Tanabe, N. Sadato, and Y. Kamitani, “Visual image reconstruction from human brain activity using a combination of multiscale local image decoders,” Neuron, vol.60, no. 5, pp.915–929, Dec. 2008.
(6) K. Fukushima, “Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position,” Biological. Cybernetics, vol.36, no. 4, pp.193–202, Apr. 1980.
(7) A. Krizhevsky, I. Sutskever, and G. E. Hinton, “ImageNet classification with deep convolutional neural networks,” Communications of the ACM, vol.60, no. 6, pp.84–90, May 2017.
(8) T. Horikawa and Y. Kamitani, “Generic decoding of seen and imagined objects using hierarchical visual features,” Nature Communications, vol.8, 15037, May 2017.
(9) D. L. K. Yamins and J. J. DiCarlo, “Using goal-driven deep learning models to understand sensory cortex,” Nature Neuroscience, vol.19, no. 3, pp.356–365, Mar. 2016.
(10) S. Nonaka, K. Majima, S. C. Aoki, and Y. Kamitani, “Brain hierarchy score: Which deep neural networks are hierarchically brain-like?,” iScience, vol.24, no. 9, 103013, Sep. 2021.
(11) A. Mordvintsev, “DeepDream - a code example for visualizing Neural Networks,” https://ai.googleblog.com/2015/07/deepdream-code-example-for-visualizing.html, 2015.
(12) I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative Adversarial Nets,” Advances in Neural Information Processing Systems, vol.27, 2014.
(13) G. Shen, T. Horikawa, K. Majima, and Y. Kamitani, “Deep image reconstruction from human brain activity,” PLOS Computational Biology, vol.15, no. 1, e1006633, Jan. 2019.
(14) 村上春樹, 世界の終りとハードボイルド・ワンダーランド. 新潮社, 1985.
(15) C. R. Ponce, W. Xiao, P. F. Schade, T. S. Hartmann, G. Kreiman, and M. S. Livingstone, “Evolving images for visual neurons using a deep generative network reveals coding principles and neuronal preferences,” Cell, vol.177, no. 4, pp.999-1009.e10, May 2019.
(16) セミール・ゼキ, 脳は美をいかに感じるか: ピカソやモネが見た世界. 日経BPマーケティング, 2009.
(17) エリック・R・カンデル, なぜ脳はアートがわかるのか ―現代美術史から学ぶ脳科学入門―. 青土社, 2019.
(18) V・S・ラマチャンドラン, 脳のなかの天使. 角川書店, 2013.
(19) KamitaniLab, “Deep image reconstruction: Natural images,” Youtube, https://youtu.be/jsp1KaM-avU, 2017.
(20) J. Schmidhuber, “Formal theory of creativity, fun, and intrinsic motivation (1990–2010),” IEEE Transactions on Autonomous Mental Development, vol.2, no. 3, pp.230–247, Sep. 2010.
(21) P. Vuust, O. A. Heggli, K. J. Friston, and M. L. Kringelbach, “Music in the brain,” Nature Reviews Neuroscience, vol.23, no. 5, pp.287–305, May 2022.
(22) T. Horikawa and Y. Kamitani, “Attention modulates neural representation to render reconstructions according to subjective appearance,” Communications Biology, vol.5, no. 1, 34, Jan. 2022.
(23) J. K. Ho, T. Horikawa, K. Majima, and Y. Kamitani, “Inter-individual deep image reconstruction,” bioRxiv, 56, 2022.