
日刊 画像生成AI (2022年10月19日)

画像生成AI界は、今認識できないスピードで進化をし続けています。
DALL・E2公開、Midjourney公開、StableDiffusionがオープンソースで公開されて..進化の速度が上がり続けており、日々異常なスピードで変化しています。

そんな中、毎日時間なくて全然情報追えない..!って人のために業界変化、新表現、思考、問題、技術を毎日あらゆるメディアを調べ、まとめています。
過去の投稿はこちら
開発
Adobeがついに動く。
様々なAIが誕生する中Adobeがどうするのか注目されていたと思います。そんなAdobeが画像生成AI開発に踏み込むようです。倫理や法律面などで透明性を持つ画像生成AIツール開発するとのこと。もしかしたらStability AIと契約を結んでいる説もある..?
調べたら動画ありました、AdobeMAXで話されていたようです。どうぞ。
うーんどういう仕組みにするのか全く予測できない。Adobeはただクリエイターの仕事を奪うものは作らないという立場のようです。
"私たちは、クリエイター中心の観点からジェネレーティブテクノロジーにアプローチしています。AIは人間の創造性を高めるべきであり、それに取って代わるものではないと考えています。"
@dwadhwaniは創造性、責任、技術の交差点に対するアドビのビジョンを #AdobeMAX で共有しています。
“We’re approaching generative technology from a creator-centric perspective. We believe AI should enhance human creativity, not replace it.” @dwadhwani shares Adobe’s vision for the intersection of creativity, responsibility and tech at #AdobeMAX. pic.twitter.com/WRX1JvoldD
— Adobe (@Adobe) October 19, 2022
今のところAdobeExpressというのが近日公開予定らしく、その中にgenerative aiでのフォント作成があるみたいなのと..
(これ面白そう)
Can't wait for generative AI + editable text in Adobe tools! 🤖🔥 pic.twitter.com/2kZi4rYM21
— John Nack (@jnack) October 19, 2022
not sure if we’ll call it “infinite text effects” or “Neural Fonts” or “generative-font treatments” or…- but that’s the easy part. here’s a glimpse of Generative-AI to transform any font you’re using…into rose petals, sake bottles, whatever - coming to @AdobeExpress 🔮 pic.twitter.com/6bx8duSKdu
— scott belsky (@scottbelsky) October 19, 2022
時間を変えたり、季節を変えたりできるのも例として出されていたみたいです。これらはAdobe Stock Libraryから学習したAdobe Senseiによってもたらされているらしい。もう決まった時間に撮影とかいうプロセスも無くなったらめっちゃ便利だ。

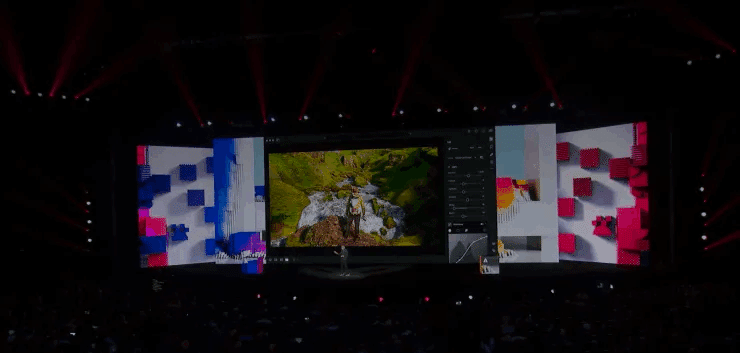


他の紹介されていた例
写真の影の移動
コンピューターで生成された空と照明で時刻を変更する
口頭のプロンプトに基づいて新しいデザインとコンテンツを作成する
春から冬への季節の移ろいを写真で
人が写っている新しい写真を作成する、AI で作成された人
基調講演はここで見れます、どうぞ
UniTune: 単一の画像で画像生成モデルを微調整することによるテキスト主導の画像編集
UniTune は、入力として画像(1枚)と画像編集の説明を受け取り、入力画像に対する高いセマンティックおよび視覚的忠実度を維持しながら編集を実行するもの。img2imgと一緒じゃん!となりそうなところですが、よくみるとimg2imgでは影響が消えてしまいそうなところまで残っているように感じる。高度なimg2imgのような感じでしょうか。モデルとしてはimagenを利用しているが、他のモデルでも動くように期待しているということです。
UniTune: Text-Driven Image Editing by Fine Tuning an Image Generation Model on a Single Image
— AK (@_akhaliq) October 19, 2022
abs: https://t.co/AU8m80CjQD pic.twitter.com/A7UD1fLM9B
RunwayMLからinpainting用StableDiffusionモデルが登場
RunwayMLがStabilityからの資金提供で新しいモデルを公開。AI動画編集ツールを作っているRunwayからinpainting用のSDモデルが登場、果たして何が違うのか..
We’re excited to release public checkpoints for Stable Diffusion Inpainting, which powers our Erase-and-Replace Tool.
— Runway (@runwayml) October 18, 2022
Code at our Stable Diffusion repo: https://t.co/onmchCUxHM
Weights at the @huggingface model hub: https://t.co/LTfi3rHmO0
以下のディスカッション曰く、最大の違いはDDIMサンプラーに追加された十数行のコードらしい。使ってみた方のコメント2人見たのですが、普通のSDよりかなり質が高くinpaintingできるらしい。おそらくAI動画編集ツールのRunwayでは高画質動画の編集をしたりするからそのために高度なinpaintingの開発が必要だったのかもしれない。
Stable Hordeがモデル変更とimg2imgに対応
Stable Diffusion ワーカーのクラウドソーシングによる分散クラスタ、つまり無料で画像生成できて、みんなの力が合わさってできているSD、「Stable Horde」。久しぶりに使ってみたら人が増えてきたのか初期の速さは無くなっている印象でした、というか全然生成できなくなっていた。そのSHがimg2imgとモデル変更にまで対応。

元素法典一点五卷 —— Novel AI 元素魔法全收录
NovelAIの高レベルなプロンプト集、元素法典のver1.5が出たらしいです。
#元素法典 ver1.5が出たようです。ALTに一部呪文引用 #NovelAI #NovelAIDiffusion #stablediffusion
— PROTO@AiArt (@proto_jp) October 19, 2022
①花と火の基本メソッド
②カラー・オブ・ザ・スターズ
③星天使
④占星術
元素法典一点五卷 —— Novel AI 元素魔法全收录 https://t.co/pXmgx9MqBm pic.twitter.com/UCt2j0Va2t
Krea.aiの対話型UIが形になってきている件
生成画像検索サービス、Lexica.artと競合サービスの中でもいいサービス、Krea.aiが対話型UIをずっと開発されていて、形になってきているそうです。
our conversational UI is taking shape. pic.twitter.com/VWKSJDTMxo
— KREA AI (@krea_ai) October 18, 2022
Gradioにストップボタンがつくみたいです。
We just released 𝟹.𝟼 🥳
— Gradio (@Gradio) October 18, 2022
Lots of goodies merged in the last few days, like the ability to STOP running predictions and iterations easily
Read more: https://t.co/U364DDTMDw 🚀 pic.twitter.com/ersq7P8fho
Stability AIが5408個のA100を所有したようです
どんどん所有数が増えてきている。おめでたい。
5,408 A100s 🫠 https://t.co/UOz9VCyUgH
— Emad (@EMostaque) October 19, 2022
Public PromptsにMicroWorlds DreamBoothモデルが登場
有料でpromptを販売するpromptbase.comを許せないサイト製作者の方が高クオリティのプロンプトやdreamboothを無料で公開していく活動、public promptsに今日もモデルが登場。今日はこういうやつ

Midjourney Style Libraryが更新
38人の画家とイラストレーター、14 人の写真家、数人のデザイナーと建築家、5つの新しい芸術的技法、ファッションデザイナー向けセクションを追加したとのこと。合計673個。かなり質の高いスタイルライブラリになってきた。

表現
NovelAIで逆に唱える
ネガティブプロンプトにまとめて突っ込んだらどういうことになるかということだと思います。本当に全く逆になってる。色も逆位相のオレンジだし、ムキムキになってる。
Novel AIで全く同じ呪文を
— のばまん (@nobamangames) October 19, 2022
←正しい順番で唱えた絵←
→逆に唱えた絵→ pic.twitter.com/knhTsKC1ZA
NovelAIでラーメンを食べる女の子を生成するのが流行っているらしい
はやりのAIラーメン女 #NovelAI pic.twitter.com/2aU4ushLYf
— のばまん (@nobamangames) October 19, 2022
NovelAIで樋口円香にラーメン食わせるやつやってみた
— お茶漬け (@umecha1128) October 19, 2022
このキャラ全然知らんけどなかなか豪快な女だな pic.twitter.com/jPcpqcSIy9
#NovelAIdiffusion pic.twitter.com/AFxDqnAsKB
— Ramen Girl Bot (@RamenGirlBot) October 19, 2022
AIアニメーションセレクト
この日は豊作です、上2つのAIアニメーションのクオリティはなかなかないので素晴らしいです。DreamBoothで学習したモデルで作られているのもあります。
This Anime Does Not Exist 🌚
— Dmitrii Tochilkin (@cut_pow) October 18, 2022
And several hours before the intro didn't exist either — praise to AI animation!
Strong generative image model is all you need (and my algorithm for 3D animation). Still testing its capabilities — now less jittering and blur.
Would you watch this? pic.twitter.com/aQIzTDZZpR
The Whistler#stablediffusion #stablewarp #dreambooth #okcomputer #ai pic.twitter.com/4qGQgyZ1eM
— Roope Rainisto (@rainisto) October 19, 2022
Been a while since I’ve done an animation but I felt like it today 😈#stablediffusion #deforumdiffusion #aianimation pic.twitter.com/1vlEbGNtkV
— blakely.gif ✨ (@projectgreybird) October 18, 2022
神の設計図シリーズ
「神の設計図」って指示でAIの作成する画像がゾクゾクする感じなので見てください#midjourney pic.twitter.com/hEy8N48gnF
— ハッピーゼリーポンチ (@hapijelly912) October 19, 2022
「神の設計図」って指示でAIの作成する画像がゾクゾクする感じなので見てください その②#midjourney pic.twitter.com/6HBzlsxwtY
— ハッピーゼリーポンチ (@hapijelly912) October 19, 2022
綺麗な手がSDで出せないからイライラして壊れた手をバケツに入れた画像を生成した

爆発するボムヘイの動画
動画を撮影して、ロトスコープを作成してからSDで実行したらしい。(Deforumのvideo inputでやっていそうです)

研究
Imagic解説記事や、検証
昨日も貼りましたが今日も紹介。AI画像編集ができる強力なImagicについて詳しくbirdMan氏が解説されています。是非
巷でやべーと話題のImagicについて、解説記事を書きました!
— birdMan (@birdMan710Nika) October 19, 2022
ソースコードを読みながら手法を理解できますhttps://t.co/QScd7cT5OX
うちの猫を Imagic Stable Diffusion で寝かせようとしたら(a cat is sleeping)、猫は変わらず、寝室っぽいとこに移動した pic.twitter.com/LlvN7PXUpp
— 布留川英一 / Hidekazu Furukawa (@npaka123) October 19, 2022
かわいい。
NovelAIをSeed値を固定して差分画像を作る方法
NovelAIの基本操作、img2imgのnoteを書かれていたかりみやさんがseed値を固定して差分画像を作る方法を公開されています。分かりやすい。
https://t.co/Rej2zQj55c
— かりみや (@Callimiya) October 19, 2022
NovelAIでSeedを固定して、簡単に差分画像を作る方法のNoteを書きました
無料です#NovelAI #NovelAIAIDiffusion
Hypernetworksのレイヤー構造を変えた際の変化を検証する
書いた!
— なんか (@_determina_) October 19, 2022
[Diffusion Model] Hypernetworksのレイヤー構造を変えた際の変化を検証する|なんか https://t.co/EuO6KBPFBB #zenn
思想・ムーブメント
ポッドキャストで、Emad氏がゲスト出演で語った話
昨日stability AIの発表会と同時に紹介していた動画の翻訳版を海行さんがアップされていましたので紹介。(海行さんがなぜか前のアカウント凍結されてしまったので、今こちらのアカウントで活動されています。)
Emad氏がポッドキャストでゲスト出演して語った話のWhisper文字起こしとそれのDeepL翻訳。特に新しいニュースは無かったけど、なぜStabilityがオープンAI戦略をやってるのかが語られてる 22/10/19 Infinite LoopsでのEmad氏の話 https://t.co/RWIq3cJa2S
— うみゆき@AI研究 (@umiyuki_ai) October 19, 2022
SDは1.5からはエロとかが検閲されたモデルになるらしい。Emad氏は当初「AIがエロ画像作れちゃってもしょーがねーだろインターネット自体がエロだらけなんだからさあ。google検索だってエロ出てくるんだからウチだけ文句言われても困る」みたいな事言ってたけどこの詭弁は社会には通用しなかったらしい
— うみゆき@AI研究 (@umiyuki_ai) October 19, 2022
Stable DiffusionのGitHubのスター数面白い
縦にほぼ垂直に伸びてるの面白すぎる。
GitHubのスター数、 #StableDiffusion はもはや垂直発進 https://t.co/py56b1LiZ0
— Kenji Iguchi 💉⁴ (@needle) October 18, 2022
朝日新聞のAI画像生成についての記事。
852話さん、清水さん、柿沼さんにインタビュー
数十秒でプロ級、AI作成画像 フェイク拡散、静岡豪雨で問題視:朝日新聞デジタル https://t.co/0QdoNkr6Wh
— 佐藤美鈴 MisuzuSato (@misuzusato) October 18, 2022
Midjourney、Stable Diffusion、mimicなどが話題になった画像生成AI。CGクリエーターの852話さん、AI研究者の清水亮さん、柿沼太一弁護士などにお話をうかがい、記事にまとめました
最後に
Twitterに、毎日製作したものや、最新情報、検証を載せたりしています。
よかったら見ていただけたら嬉しいです。
画像生成AIの実験, 最新情報のまとめはこちら
過去の号はこちら
次の号はこちら
サポートいただけると喜びます。本を読むのが好きなので、いただいたものはそこに使わせていただきます