
日刊 画像生成AI (2022年10月20日)

画像生成AI界は、今認識できないスピードで進化をし続けています。
DALL・E2公開、Midjourney公開、StableDiffusionがオープンソースで公開されて..進化の速度が上がり続けており、日々異常なスピードで変化しています。

そんな中、毎日時間なくて全然情報追えない..!って人のために業界変化、新表現、思考、問題、技術を毎日あらゆるメディアを調べ、まとめています。
過去の投稿はこちら
開発
Stable Diffusion 1.5vが公開。
AI動画編集ツールを公開しているRunwayMLから、20日の夜Stable Diffusion1.5vが公開。9月25日公開と言われていたり、公開されないんじゃないかと言われたりと言われていた1.5が突如、しかもComvisでなくrunwayの方からアップロードされた。この真相については21日の方に記載します。
We've released public checkpoints for Stable Diffusion v1.5, which powers our Text-to-Image and Image-to-Image Tools.
— Runway (@runwayml) October 20, 2022
Code on GitHub: https://t.co/onmchCUxHM
Weights at the @huggingface model hub:https://t.co/twsOwQkPQP
NovelAIDiffusionを支える魔法
NovelAIが画像生成AIの仕組みについてのブログを公開。画像データをコラージュしているだけという指摘、Danbooruデータを利用している問題など様々なことがあったのでこのようなブログを公開されたものだと思われます。
詳細なデータの部分まで語られています。モデルはオリジナルの Stable Diffusion モデルに基づいていて、LAION データセット (~150TB) からの約 20億の画像でトレーニング。使用したデータセットは、非常に詳細なテキストタグ データを含む約 530 万枚の画像 (約6TB) で構成
Let's talk about the magic behind #NovelAIDiffusion
— NovelAI (@novelaiofficial) October 19, 2022
We’ve been quite busy watching NovelAI spread across social media, and we’re honestly surprised by the interesting theories people have come up with as to how our AI Image Generation tool works. pic.twitter.com/swbaosjhlf
For example... No, we do not feed the enslaved AI in the basement 1bite a day for its hard work!https://t.co/exZ2Hlep3f
— NovelAI (@novelaiofficial) October 19, 2022
The "magic" powering our Diffusion models is challenging to explain, so let’s simplify it for this post.
ここから少し画像生成AIではなくなります。
画像生成以外の話題になったAIもいつも一緒に紹介してます。
RLHFで学習させた大規模言語モデルがついにオープンに..
次の言葉を予測するタイプのLLM(大規模言語モデル)は使い勝手が悪いし、事実と違うことを言うし不快な出力を出すこともあるようです。
その出力に対する人間からのフィードバックを集め、人間のフィードバックをより予測しやすい方向にモデルのパラメータを調整することで、事後的に調整することができるらしい。
それにより、優れた検索、文章作成支援、コード生成、さらにはタスクを自動化する汎用的なアシスタントが可能になるとのことです。通常のLLM(大規模言語モデル)に存在する誤報の拡散や社会的偏見の強化というリスクを大幅に軽減もできるらしい。
これはすでにOpenAI、DeepMindの方にはあるらしいが…、APIとして提供されているだけ。CasperAIにより初めてオープンになる。

ちなみにCarperAIは、Stable Diffusionが画像生成を民主化したように、大規模言語モデルの「LLMs」「命令チューニング」を民主化することを目的らしいので、この実行がメインの組織。
Stability AIの中のEleutherAI研究室の中のCarperAI研修室やそれと一緒に活動予定の様々な組織(ScaleAI, Humanloop, Huggingfaceなど)と連携してそれを作られていくそうです。公開が待ち遠しい。どんなことが起きるんだろ

Today at TransformX, we announced a huge step forward for the open source ML community: we are partnering with @StabilityAI to release the first large language model trained with human feedback. https://t.co/kRR0MUhSQ1 1/4
— Scale AI (@scale_AI) October 20, 2022
Today we’re excited to announce our partnership with @scale_AI, @Humanloop, @multi_agi, and @HuggingFace to create the first open source reinforcement-learning based instruction tuned language model. You can read more about our efforts here: https://t.co/bAuLFy8kHk 1/4
— Carper (@carperai) October 20, 2022
Today we're excited to announce that we're partnering with @CarperAI of Stability on bringing the first RLHF-trained GPT-3 like model to the open source community.
— Humanloop (@humanloop) October 20, 2022
This will be huge. Let us explain pic.twitter.com/CBE47VAPoq
MetaAIがUniversal Speech Translator(UST)を発表。
世界の誰とでも日本語のまま話せる日が来るかもしれない。
しかも家の中から。
This is pretty sick. $META pic.twitter.com/MoGKkvMfMN
— George Hadjia (@GHadjia) October 19, 2022
(1/3) Until now, AI translation has focused mainly on written languages. Universal Speech Translator (UST) is the 1st AI-powered speech-to-speech translation system for a primarily oral language, translating Hokkien, one of many primarily spoken languages. https://t.co/onYKQ8uoKN pic.twitter.com/Iy8MRMOypQ
— Meta AI (@MetaAI) October 19, 2022
Meta AIが、主に口語で話される言語を対象とした初のAIを搭載した音声から音声への翻訳システムUniversal Speech Translator(UST)を開発。今は福建語⇆英語のシステムが開発されている状態。
だがGaget360に記載されたMetaのコメントは次のように書かれている。
"これは、言語間の同時翻訳が可能な未来への一歩です。"
"我々が福建語で開拓した技術は、他の多くの文字を使わない口頭言語にも拡張でき、いずれはリアルタイムで機能するようになるでしょう。"
すごい..実現したらもう外国語を学ぶというのも違う時代になりそうですね、今の字を綺麗に書けるスキルみたいな扱いになりそう。パソコンで打てばいいやんっていう。
ちなみにここで試せます。
Text to Music (MubertAI)のColabノートブックが公開
MubertというAIでタグ指定したら音楽を生成してくれるサービスがあったんですがそのAPIを利用してテキストを入れたらそれをタグに変換することでtext to musicを実現しているcolabノートブックが公開されて話題になりました。1度タグに変換したり、あらゆる曲を学習しているわけではなく、アーティストさんたちに作ってもらったやつをもとに学習しているらしいので、歌声とかは難しいみたいです。でもゲームのBGMとかもうこれでいいのかも。
Mubert-Text-to-Music 🎵🎵🎵
— AK (@_akhaliq) October 19, 2022
Colab notebooks demonstrating prompt-based music generation via Mubert API
GitHub: https://t.co/ExdfvXUCrR pic.twitter.com/2Ycwl7RUvX
We’re glad to present you our new Text-to-Music demo interface. https://t.co/nRkA9fvtGn
— Mubert: music powered by AI (@mubertapp) October 20, 2022
Now as a Google Colab, and soon we’ll add this feature as a simple form on our website. This has already gone viral, so the community has questions about how everything works.
Imagicが使えるGoogleColabノートブックの日本語版が公開。
リーサ・リサージュ・ヤスミンさんが先日話題になったAIですごい画像編集ができてしまうImagicが使える日本語のcolabノートブックを公開されました。使いやすそう。
画像加工のAIツール、Imagic Stable Diffusionを使えるGoogleColabノートブック公開しました!同じキャラの差分パターン作成や、一部だけ絵を加筆・修正したりするのに使えるかもです #StableDiffusionKawaii #WaifuDiffusion https://t.co/n7Ad3gBLNQ pic.twitter.com/uHn3RpXLuv
— リーサ・リサージュ・ヤスミン (@LisaDQX) October 20, 2022
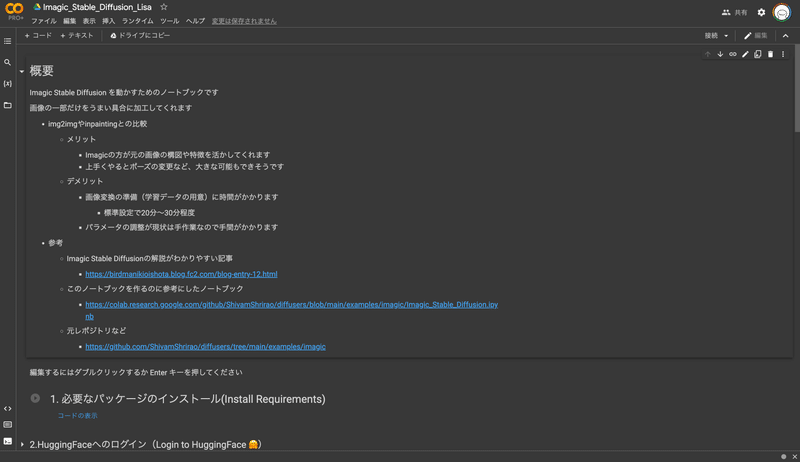
CLIP InterrogatorのHuggingface Demoが公開。
プロンプトが逆算できるCLIP InterrogatorがHuggingfaceでDemoが公開されて使っている方がこの日多かった印象です。colabがなくても気軽に試せるのでぜひ。
StableDiffusion-infinityのメジャーアップデート + RunwayのSD inpaintingモデルについて
DALLE2と同じOutpainting用UIがSDで使えるStableDiffusion-infintyが以前公開されていましたが、先日公開されたrunwayのSD inpainting専用モデルを使うとかなりクオリティが上がるらしい。 これはDALL-E2を超えてそう。DALLE2のoutpaintingはどうしてもなんか変な筆っぽい質感が入ってしまうけどこれはそれがないように見えます。
The Stable Diffusion inpainting model works quite well for outpainting. A major update of stablediffusion-infinity will be released soon. pic.twitter.com/hiwWsIyJfA
— Lnyan (@lkwq007) October 20, 2022


runwayのinpainting専用モデルはこちらに。
一緒に話しますが、runwayのinpaintingモデルめっちゃすごいっぽい、imagic的なクオリティがありそう。以下の画像はinpaintingモデルが使われたもの。(clipseg(テキストからマスクを生成する)で髪を指定してSDinpaintingモデルを利用しているようです。)
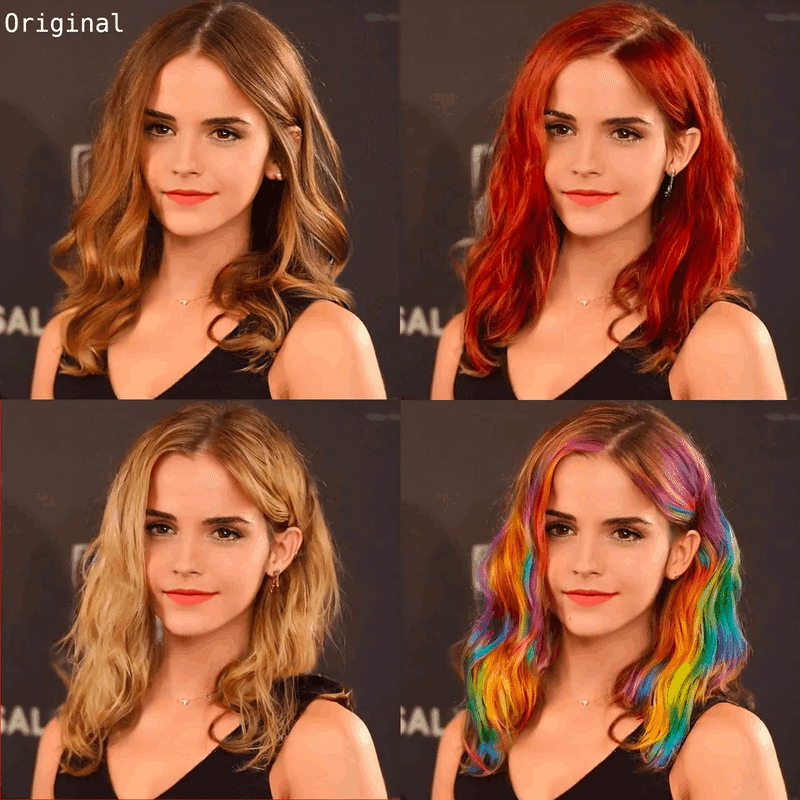
試したい方はここで簡単に試せるようです。どうぞ。
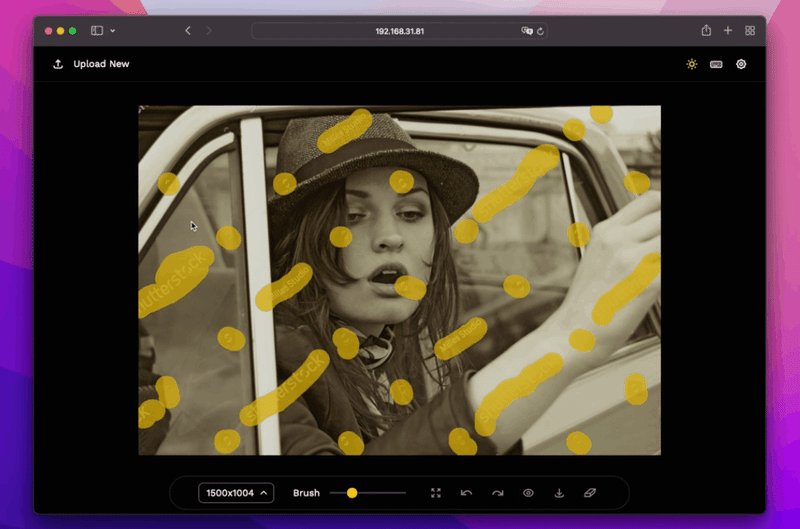
Lama CleanerがrunwayのSD inpaintingモデルを搭載
SOTA AI モデルを利用した無料のオープンソース修復ツール、Lama Cleaner も先日公開されたrunwayのSD inpaintingモデルを搭載したとのこと。サンプル動画のこの例ちょっと一部の人にとっては恐ろしいですね
NovelAI用タグジェネレーターにランダム機能が追加
NovelAI用のタグジェネレーターにランダム機能を追加しました🎉https://t.co/KUDqSE78cm#NovelAI pic.twitter.com/PQmujt07PQ
— 逆瀬川 (@gyakuse) October 19, 2022
Public Promptsに Pixel Landscape V1が追加
有料でprompt販売を行うpromptbase.comを許せない方が多いようで、その中の1人の方がpublic promptsというサイトを立ち上げ、無料でバンバンモデルやプロンプトを公開し続けています。基本全部この辺りの文化は高速で無料に向かっていますね、
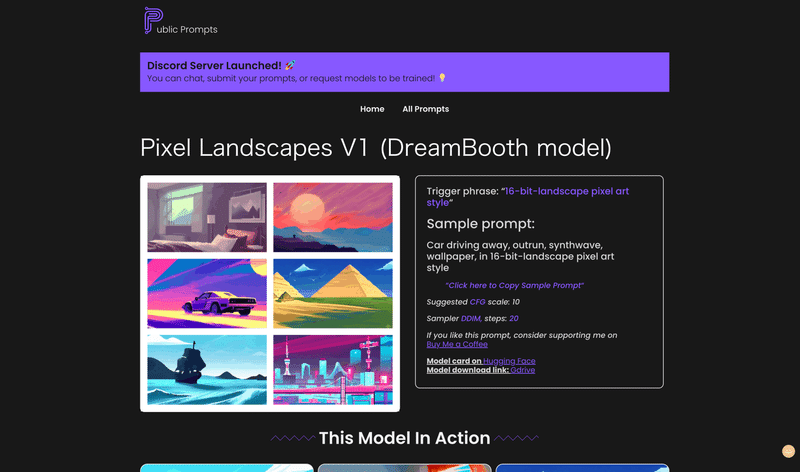
OnnxDiffusersUI
WindowsのAMD GPU で SD を実行するための独自の UIが開発、公開されたようです。この環境の方にとってはめっちゃ嬉しい..? ただそんな早く動作するわけではないとのこと。
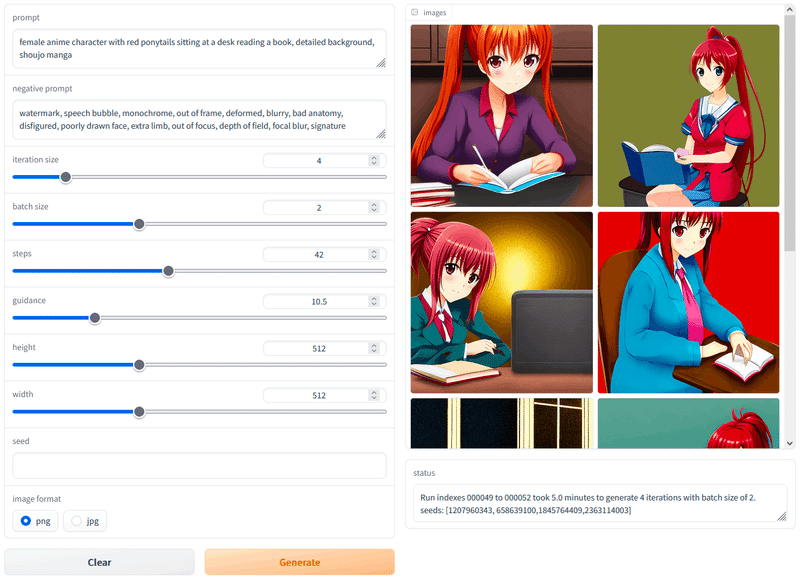
ポートレート画像用にMidjourneyのポートレート画像で学習したDreamBoothモデルが公開

これ個人的にやろうとしていたので気になる。ちょっと後で触ってみます。
以下のページでモデルはダウンロードできます。
NovelAI流出モデルの現状
もう投稿は消えてしまっていましたがNovelAI流出モデルがずっと一部の人たちには使われている状態のようです。一応現状共有です。
違法なのでやめましょう。
→Stable Diffusion webUI(1111版)がマッハで更新していく
— かぴぱん (@Kapipan_jp) October 20, 2022
→新しい学習モデルを読み込む機能が爆誕
→NovelAIを再現可能に
→NovelAIを家庭用pcで動くようにしたやつ「Naifu」が4chanに降臨
→Naifuインストーラーが出る←今ココ
cudaをインストールする必要があったのが
exeだけになったからすこし楽 https://t.co/2hO2vjZd9k
表現
NovelAI、WaifuDiffusionの表現研究続々
sabakichiさんのシンプルなイラスト生成めちゃめちゃすごい、この質感もできるんですね..すごい。かりみやさんの大量猫プロンプトもすごい。
発見すぎる。イラストでの出力系はちょっと多すぎるので全ては拾えていないと思います、いいの作られてたらすみません。
デフォルメ化の研究、抽象度をいい感じに調整できるようになってきて「雲と女の子」をテーマにここまでゆるいイラストを描いてもらえるようになりました#NovelAI #NovelAIDiffusion pic.twitter.com/u39gwEpJ0B
— sabakichi|Domain ✍︎ (@knshtyk) October 20, 2022
Prompt: {{{{{{{{{{multiple many surrounded 10000000000000000 cats}}}}}}}}}} {{{{{{{{{{😺😺😺😺😺😺😺😺😺😺😺😺😺😺😺}}}}}}}}}}
— かりみや (@Callimiya) October 20, 2022
超有料級prompt共有します#NovelAI pic.twitter.com/CWfb9SS16p
#WaifuDiffusion #AIart #AIイラスト
— ハニニフ (@haninifu) October 19, 2022
negative promptにgrayscaleを入れたらAIイラストにありがちなぼんやりした感じがなくなって一気に鮮やかになった pic.twitter.com/HSnYLija5k
AIで4人以上かつ原作のあるキャラクターの外見を保てるのか検証
— 852話 (@8co28) October 20, 2022
東方から
霊夢 魔理沙 フラン レミリア
直出し無編集 pic.twitter.com/br9Ud0DQxk
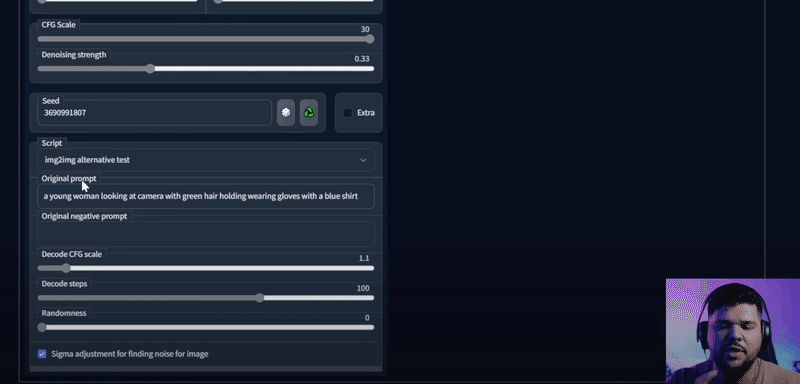
動画への一貫したimg2imgの適用
一貫したimg2imgでクオリティの高いものがどんどんアップされてきていますがそれのHow to動画がアップされていたので紹介。以下はそのhowto動画をもとに作られたもの。textual inversionで顔を学習して一貫性をこれは保っているみたい。

以下は元のhow to 動画。
通常のimg2imgより良いimg2img結果が得られる(元の画像を維持した結果になるらしい)img2img alternative testというscriptでクオリティを高くしているようです。(ただまだ、画像をぶっ壊すことが多いらしいとの記載も別で見ました。)(ちょっと理解しきれておらずです。やりたい方は動画へ)
あぶぶさんのホラー画像生成
面白いし、フォトバッシュワークフローがめっちゃ上手すぎてすごい
#stableDifusion pic.twitter.com/D3PTvTvBR8
— あぶぶ@健全 (@abubu_newnanka) October 20, 2022
#stablediffusion クトゥルフ pic.twitter.com/1WJ8MPmP6Z
— あぶぶ@健全 (@abubu_newnanka) October 20, 2022
"pretty ladies doing magic in the woods"

Stable Diffusionの欲しい画像を作るワークフロー
久しぶりにこれ系のワークフロー動画がアップされていました。一発生成じゃなく、ワークフローを使っている人はもうAI絵師と名乗っても何も言われなさそう。プロンプトだけで一発生成だと絵師っていうか、ディレクター?
AIディレクターみたいな名前が良さそう。
Sci-Fantasy Art Timelapse using #stablediffusion #img2img, #photoshop, and #automatic1111's @Gradio UI.
— Patrick Galbraith (@P_Galbraith) October 20, 2022
Extended video: https://t.co/pC9IpHTbgg pic.twitter.com/sx86l0viw5
DALL-E2で作られた奇妙なGoogleEarth写真
GoogleEarth写真生成するの楽しそう。
この日この投稿が人気で面白かったので紹介。


研究
Imagic、Text-to-Music検証
話題のText-to-Music 試してみたけど普通に良さげなやつ出てきてつよい pic.twitter.com/GpNPfQdczn
— 🥴S.Percentage🐾 (@Pctg_x8) October 20, 2022
Mubertによる「Text-to-Music」のアーリーアクセスが来ました。DEMOは尺とプロンプトの入力のみの簡単なもの
— 852話 (@8co28) October 19, 2022
現状音楽ジャンルや楽器のタグ付けが出来ないので制御がかなり難しいというか出来ない
この曲も別にFuture Bassではないと思うんだけど気に入ったので#mubert pic.twitter.com/PkOiBOs0XC
#Imagic さん #WaifuDiffusion でもイケた
— forasteran (@forasteran) October 19, 2022
某女の上司パイセンw
あのひとです
あご乗せポーズを学習後…
1枚目:a pink hair girl
2枚目:a red hair girl, golden eyes, braided ponytail
3枚目:🍔系w
4枚目:🍔👙w
i2iより強烈に構図を踏襲しつつ変えれる
特性をまだ理解しきれてないw pic.twitter.com/cPx5o0O2Uv
5120x1440画像の書き出しワークフロー

SDでまず12stepくらいの低さで2048x576でいっぱい書き出して、いいやつのシード値を固定して、60stepで生成。それをアップスケールするとのこと。(書いたけど普通だった。)
Waifu Diffusionの追加学習(DreamBoothじゃない)をColabT4で行う
Waifu diffusionの追加学習をColabのT4で行う。(使用VRAM13.6GB)※dreamboothじゃないよ|gcem156 #note https://t.co/MFqjMtmNlh
— いぬごや (@thx0pw) October 20, 2022
思想・ムーブメント
AI生成作品の取り扱いに関するサービスの方針について
従来の投稿作品とAI生成作品のすみわけが可能になるように以下の機能が追加された。海外のイラストコンペやストックサイトと同様、すみわけという選択を取られました。「創作過程におけるAI技術の利用がより普及していくと捉えており、AIが関与した成果物の完全な排斥は考えておりません。」とのこと。
■機能改修
・投稿編集時にAI生成作品と設定できる機能の提供
・AI生成作品を検索時などにフィルタリングする機能の提供
・従来の作品とは分けた、AI生成作品のみのランキングの提供
AI生成作品の取り扱いに関するサービスの方針についてのお知らせを公開いたしました。詳細はこちらをご確認ください。https://t.co/HvYPp4q0Nd
— pixiv (@pixiv) October 20, 2022
AIの反逆によって異常ラーメン食べ女・AI樋口円香が生まれ、人間がそのファンアートを描くというカオスな流れが誕生しつつある
AIが生成しためっちゃいい笑顔でラーメンをわしづかみに食う樋口円香が「AI樋口円香」として再定義され、人間絵師が描いたAI樋口円香のファンアートまで出てきてるの、文脈とスピード感が面白すぎる
— amow (@amowwee) October 19, 2022
今お絵描きAIで話題のテーマ
— バーチャルバイコーンふとし (@oitadyna) October 19, 2022
・ケーキ化
・ラーメンを食べられない樋口円香
・泳げないセフィロス
・号泣しながらピザを焼くマックイーン
次は何が来るのか全然読めん。
治安が最悪だった頃のニコニコ動画みたい。
StabilityAIの資金調達に伴うアナウンスプレゼン翻訳

Stabilityによる資金調達に伴うアナウンスプレゼンについて。新しいニュースはDreamStudioPro、アニメーションAPI、オープンソースSDKの発表かな 22/10/19 Stabilityのアナウンスプレゼン https://t.co/yYP1bTn5Rx
— うみゆき@AI研究 (@umiyuki_ai) October 20, 2022
この日の気になるツイート
I've been doing a deep dive into prompt engineering for large language models. Here are 12 of the most interesting papers, resources, and write-ups I've found:
— Mihail Eric (@mihail_eric) October 19, 2022
think with a very long time horizon, act with great short-term urgency and effectiveness, success guaranteed
— Sam Altman (@sama) October 19, 2022
think with a very short time horizon, act with "it will sort itself out eventually somehow" vibes, get JPEGs on blockchain
— Sam Altman (@sama) October 19, 2022
勉強
fast.aiの「ディープラーニングの基礎からStableDiffusionへ」の講義の最初の5.5時間分が無料で公開。
ちょっと自分のまだ知識量ではむずいかなと思って入っていなかったのですが最初の5.5時間分が無料で公開になったようです。見てみる。
I got a special surprise for you all...
— Jeremy Howard (@jeremyphoward) October 20, 2022
We just released the first 5.5 hours of our new course "From Deep Learning Foundations to Stable Diffusion", for free!https://t.co/LiUu9HSflG
最後に
Twitterに、毎日製作したものや、最新情報、検証を載せたりしています。
よかったら見ていただけたら嬉しいです。
画像生成AIの実験, 最新情報のまとめはこちら
過去の号はこちら
次の号はこちら
サポートいただけると喜びます。本を読むのが好きなので、いただいたものはそこに使わせていただきます