
日刊 画像生成AI (2022年10月6日)

画像生成AI界は、今認識できないスピードで進化をし続けています。
DALL・E2公開、Midjourney公開、StableDiffusionがオープンソースで公開されて..進化の速度が上がり続けており、日々異常なスピードで変化しています。

そんな中、毎日時間なくて全然情報追えない..!って人のために業界変化、新表現、思考、問題、技術を毎日あらゆるメディアを調べ、まとめています。
昨日までの投稿はこちら
開発
Imagen video
(画像生成AIではないですが近いので紹介。) Google ResearchがテキストからHD動画(1280x768 24fps)を生成する「Imagen Video」を発表。懸念が軽減されるまではモデルやソースは公開しないとのこと。

Excited to announce Imagen Video, our new text-conditioned video diffusion model that generates 1280x768 24fps HD videos! #ImagenVideohttps://t.co/JWj3L7MpBU
— Jonathan Ho (@hojonathanho) October 5, 2022
Work w/ @wchan212 @Chitwan_Saharia @jaywhang_ @RuiqiGao @agritsenko @dpkingma @poolio @mo_norouzi @fleet_dj @TimSalimans pic.twitter.com/eN81LqZW7I
Text2Filter
AIで写真に色をつけたり、テキスト入力すればそれっぽいフィルターをかけたりもしてくれるpalette.fmが公開されました。

試しに僕がSDで生成した画像を入れてみました。

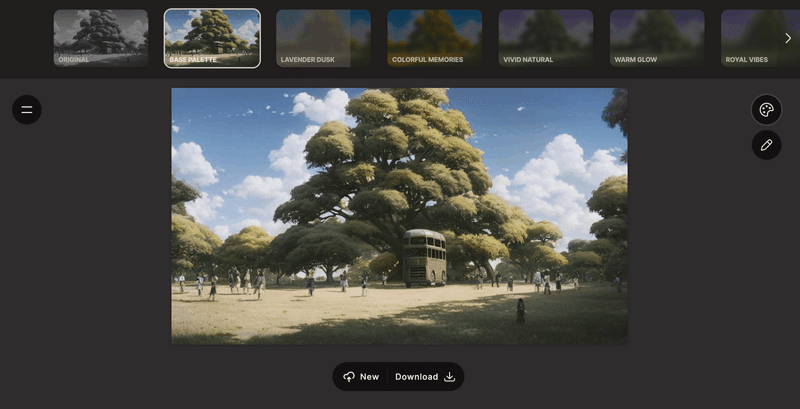

WebUI by AUTOMATIC1111でAND記法が使えるようになりました。
少し前に公開された、Composable-DiffusionのAND記法(ANDと、AND NOT)が使えるようになったそうです。Composable-Diffusionは複数の拡散モデルを組み合わせて合成的な画像生成を行うアプローチ。
Composable-Diffusion, a way to use multiple prompts at once
separate prompts using uppercase AND
also supports weights for prompts: a cat :1.2 AND a dog AND a penguin :2.2
例えばこうなるようです。ANDになるとちゃんと混ざる。
Lol, I guess this is along the lines of what I was expecting.
— TomLikesRobots (@TomLikesRobots) October 13, 2022
Composable diffusion with two prompts being blended using #automatic1111
1. A beautiful woman and a cat
2. A beautiful woman AND a cat#aiart #stablediffusion pic.twitter.com/LUAfpxEBCN
具体的には論文の例を見るのが分かりやすそう。GLIDEでは反映されていないところがちゃんと描画されています。

Waifu Diffusion 1.3完成版
(数日後リリースノートが公開されています。)
ずっとしばらく学習終わるごとにエポックが公開され続けていたのですが、完成したようです。公式公開は10.8。海行さんの投稿で知りましたが、14.6GBのfull-opt版は追加学習させるのに役立つようです。

カスタムハンドモデルが開発中。
約半分の確率で完璧な手が描ける「カスタムハンドモデル」が開発中。
DreamBoothで手を学習したとのこと。より多くの手を学習させて近日公開予定。(調べましたがまだリリースなしです。)

Runwayが事前ライブデモ募集中。
以前話題になったテキストから動画編集をする魔法のAI編集ツール、Runwayが事前リリースをされるようです。こちらから応募できます。一応申請しておきましたがまだ連絡は来ておらずです。早く試したい。
I'm doing live demos to collect early feedback before we begin the release.
— Cristóbal Valenzuela (@c_valenzuelab) October 6, 2022
Starting next week. If you are interested, sign up here: https://t.co/44himOs51y https://t.co/AWA4iJl6RS
8GB未満のVRAMでDreamBooth, 6GB未満のTextual Inversionが可能に。
最強版 Stable Diffusion for Photoshop
World's first Outpainting for Photoshop! #photoshop #stablediffusion Thanks @parlance_zz and @hafriedlander for great work. More info about new plugin and server version with many cool new features tomorrow. pic.twitter.com/zmh1hrgoP7
— Nicolay Mausz (@NicolayMausz) October 5, 2022
世界初、Photoshopで #stablediffusion のOutpaintingを利用できるプラグインが公開。制作した組織はKrita用Stable Diffusionプラグインも作られている方々。有料だけど機能豊富でなかなか強いです。(10月14日にもう一つのPhotoshop対応SD by Christian Cantrellもローカル対応しました。なので、こちらは有料なのでこっちよりもChristian Cantrellの方がいいですね。)
機能
・独自サーバー/ローカル/DreamStudioAPI対応
・img2img, inpainting, outpainting
・修飾子ライブラリ
・タイル、顔補正、マルチサーバー管理
…
DreamFusionをStable Diffusionで実装
先週公開されて話題になったテキストから3Dを生成するDreamFusionをStableDiffusionで実装した方がいらっしゃいました。さすが!
A implementation of text-to-3D dreamfusion, powered by stable diffusion
— AK (@_akhaliq) October 6, 2022
github: https://t.co/1GGjtphz8K pic.twitter.com/FaxIBL5WxE
試しました。
colabだとTraining_iters15000は4,5時間くらいかかった気がします。
(Twitter埋め込みが2個目の動画見れないのでTwitterで以下の投稿開いてみてみてください。)
テキストから3Dモデル生成のテスト
— やまかず (@Yamkaz) October 9, 2022
「Earth」と入力。#StableDreamFusion
1. Training_iters = 5000
2. Training_iters = 15000
結構クオリティが変わる、どこまでいけるのか気になるからやってみようかな pic.twitter.com/56BlO0zieU
Motion Diffusion Modelのコードが公開。
テキストから人間の動きを生成するDiffusionモデルが公開されました。
📢📢 Our first code delivery is out! You can now download our checkpoints and generate motions with #MDM!https://t.co/13kw2qthzo https://t.co/zmq2Na1thY pic.twitter.com/BbYGmAhudJ
— Guy Tevet (@GuyTvt) October 6, 2022
指示されたテキストに合わせたモーションを生成するAI 「MDM: Human Motion Diffusion Model」のコードが公開されました。https://t.co/PU44HsqOer
— 江良野 (@errno_mmd) October 6, 2022
早速WSL上で試しましたがVRAM 4GBのGPUでも十分動きました。 pic.twitter.com/6IojcEDWfY
squarize-images-updated
トレーニングデータの準備の際、不完全なトリミングやアスペクト比になってしまう問題がありますが、こちらのコードは自動でインペイントし、トレーニング用正方形画像にしてくれます。


Stable Diffusion UI (cmdr2) Beta v2.20がリリース
ワンクリックでwindows, linuxにインストールが可能で、簡単で上級者にも対応しているStable Diffusion UI (cmdr2)が2.20をリリース。
新機能: タスク キュー、ネガティブ プロンプト、カスタム モデル、使用リソースの削減。

このタスクキュー機能、めちゃめちゃ便利ですね。

表現
CoffeeVectors氏の新しい検証
daz3dで作ったモデルにUE5でreal-time hair, clothをつけて(UE畑にいるわけではないので命名とプロセスが間違ってるかもです。)UE5で歩行アニメーションつけて、最後Deforumで作っているとのこと。
Created with #deforum #stablediffusion from a walking animation I made in #UnrealEngine5 with #realtime clothing and hair on a #daz model. Combined the passes in Premiere. Breakdown thread 1/8 @UnrealEngine @daz3d #aiart @deforum_art #MachineLearning #aiartcommunity #aiartprocess pic.twitter.com/oeudGr0Cmq
— CoffeeVectors (@CoffeeVectors) October 6, 2022
ゼルダの実写ポスター (midjourney)



Origami Flower
折り紙の花が開いていく映像。おそらくimg2img、面白かったので紹介。


"Cyber-Shifting"
早いAIアニメーションがなんかよかったので紹介。
Cyber-Shifting pic.twitter.com/cJ0zUj0VyG
— Jeremy Torman - #airobotics live minting now (@TormanJeremy) October 5, 2022
研究
NAI Character Setup Tags
NovelAI用のCharactor Creator スプレッドシートというのが公開されていたのでメモ。既存のdanbooruのタググループとはちょっと違うっぽいです。
https://danbooru.donmai.us/wiki_pages/tag_groups

A collection of Stable Diffusion images
https://generrated.com/ はDALL・Eで膨大なプロンプト検証がまとまっているサイトですがこのプロンプトを元にSDで実験をされた方がいるようです。
200 以上のプロンプトスタイル、4000を超える画像が保存されています。

Waifu Diffusionの呪文で利用できるタグ一覧
NovelAIで生成→talking-head-anime-3でVtuber化
じゃあNovelAIで出力した1枚絵から簡単にVTuber的なことできるんじゃない?って思ってtalking-head-anime-3で試してみたら、それっぽいのができたので結構びっくりした。
— ねぎぽよし (@CST_negi) October 6, 2022
イラストを作るのも、1枚絵から適切なリギングをするのもどっちも機械学習だし、すごい時代になったなと思った。 pic.twitter.com/fFDdh8SAue
NovelAIでラフ絵出力→それを元に絵を生成。
逆にAIにラフ絵を描いてもらった
— えんだろぐ (@enda_log) October 6, 2022
これで「ラフ描きました」って言われても正味AIかわかる気がしない
特徴入れてAIにラフ出力してもらって、イメージを伝える分には使えそうかも?#NovelAI #NovelAIDiffusion pic.twitter.com/huwj1ttAAv
1枚目:AI生成してもらったラフ
— えんだろぐ (@enda_log) October 6, 2022
2枚目~4枚目:1枚目をもとにAIが生成したイラスト#NovelAI #NovelAIDiffusion pic.twitter.com/xiZJUfrdLD
NovelAIでキャラデザ生成
#novelAI#NovelAIDiffusion
— 𝓡𝓲𝓸 (@naka_158) October 6, 2022
AIでキャラデザを行うテスト
promptに「three views from front, back and side」「costume setup materials」を入れるといい感じのキャラデザ資料が生成されます
服のデザインが浮かばない時など参考にできるかもしれないですね pic.twitter.com/KWbY4EMxKM
Stable Diffusionをローカル環境のラズパイで動かす方法(苦行)
思想・ムーブメント
AIに本当に脅かされているもうひとつの集団
Deforumアニメーションが得意なWeavingWithAI氏の投稿でいいものがあったのでピックアップ。個人的にこれはずっと思っていること。撮影の圧倒的コストカットと表現多様性と生成スピードがリアルと全然違うので一部の撮影に関してはごっそり無くなりそうという気がしています。
アンチAIアートの人たちのほとんどは、今のところ(デジタル)ペインターのようですね。でも、AIに本当に脅かされているもうひとつの集団は、ある種の写真家なんです。それと、モデルも。コンピュータで完璧な画像を作ることができるのに、なぜ両方を雇うのか?
Most of the anti AI art crowd seem to be (digital) painters so far, right? But another group that's really threatened by AI is a certain kind of photographer. And also models. When it's possible to create perfect images on the computer then why hire both?
— WeavingWithAI (@GanWeaving) October 6, 2022
AI絵師騒動
NovelAIが公開されてからAI絵師と名乗る方が増え、それについて様々な議論が起こっています。
AI絵師。時代が追いついてしまった。 pic.twitter.com/10UCRnOaUC
— 霜月卯月 (@_N_Shimotsuki) October 6, 2022
AI絵師が今後発達してポピュラーになってくると
— ぬこー様ちゃん@絵日記毎日18時更新 (@nukosama) October 6, 2022
簡単なイラストだったらもうわざわざ人間にオーダーする必要がないので人間の仕事がどんどん減るって言ってる人いるけど、
もう日本に関してはいらすとやがあるからAIにすら頼る必要すらないんだよね。
人間が描いたイラストをAI絵師が勝手に学習データに利用するのを防ぐ方法はある。
— Akihito(・o・) (@Akihitweet) October 6, 2022
人間には分からない程度のノイズを加えてAIを誤認識させることはできるので、
Pixivなどはイラストに被せる
「アンチラーニングフィルター」みたいなのを実装したら良さそう。 pic.twitter.com/Bdl6sjQjPI
(↑ これは意味はないみたいです)
AI絵師を堂々と名乗る人はマシな人達だから責めない方がいい。承認欲求を満たす為にAIイラストな事を伏せて投稿してるような人が1番ヤバい。偶然でも金銭が絡む案件が舞い込んだ時に碌に描けもしないのに安請け合いして関わった人全員不幸になる未来しか見えん #novelAI
— だまてん (@pinfu__nomi) October 5, 2022
AI絵師が描けなさそうなものを人は描くようになるのだろうか pic.twitter.com/HnDbppaezB
— 全自動 新刊委託してます (@Zen_twit2) October 5, 2022
4コマ「人間の特権」 pic.twitter.com/vcEoUIjs8R
— 芋一郎 (@cheesesama24) October 5, 2022
↑ 確かにこういう進化の方向性ありそう。
AIと漫画の将来について描きました
— ぬこー様ちゃん@絵日記毎日18時更新 (@nukosama) October 6, 2022
〜AI絵師も少し添えて〜 pic.twitter.com/JrIij9AwjL
〝イラスト毎に目の色が違う・差分はないのに基本CG枚数はやたら多い・サンプルだけでも一枚一枚のイラストの雰囲気が違いすぎる・サークル運営開始がここ数日以内〟
— 蟹紅茶 (@kanikoucha) October 6, 2022
イラストAI発表からたった数日でそんな感じのCG集がDLsiteに乱立してるので、もうマジで終わりだよ。 pic.twitter.com/SygeHhIkx7
AI画像CG集のDLsite等での販売は予想できたことだけど完全に失念していたのだ。というよりは「編集もせず台詞もついてない生成物をただ詰め合わせて売る」を最初から考えてなかった。流石にエロCG集としてクオリティが低すぎるだろと思うが、見た目が良いので何十人かは買う。
— あぶぶ@健全 (@abubu_newnanka) October 6, 2022
…のでむしろ購入者リテラシーの領域ではないか。要するに今まではサムネが良い感じならクオリティも良い感じで大体満足だったけど、今後は「サムネが良い感じだったのでポチってみたら、画風が微妙にバラバラな正面ポーズ詰め合わせだった」となる可能性を購入者は警戒しなければならない。
— あぶぶ@健全 (@abubu_newnanka) October 6, 2022
Waifu Diffusionの中の人、Haru氏かっこいい。
WaifuDiffusionの中の人が、「俺はNovelAIと関係ない。ただNovelAIの設計わりとイケてるんでパクるぜ。でも俺は金のためじゃねぇ、趣味でやってんだ、ただよいAIモデルを作ってオプソにしたいだけなんだ!(雑訳)」みたいに言ってて熱量がすごいな。
— 深津 貴之 / THE GUILD / note.com (@fladdict) October 5, 2022
勉強
Stable Diffusionの研究の原点
Stable DiffusionモデルにつながったRunwayとCompVis の研究活動について
DreamFusion解説動画
先日話題になった、Diffusion modelでテキストから3D生成を行う論文: DreamFusionの解説動画をアップしました!
— hiromichi kamata (@ChagallBlau) October 6, 2022
多分どこよりも速い日本語の解説だと思います#dreamfusion
【AI論文解説】世界初!Diffusion modelを使ってテキストから3D生成: DreamFusionを解説 https://t.co/BLksB9K7kr @YouTube
最後に
Twitterに、毎日製作したものや、最新情報、検証を載せたりしています。
よかったら見ていただけたら嬉しいです。
画像生成AIの実験, 最新情報のまとめはこちら
前回の号はこちら
次の号はこちら
サポートいただけると喜びます。本を読むのが好きなので、いただいたものはそこに使わせていただきます