
竹花貴騎が主導する社会人の学校ユアユニ 【UR-Uオンラインスクール】 今日の学びWEEK12【集客SEO徹底理解】

さて、今日もアウトプットしていきます!
今日はSEO関連の話です。
主にGoogle SEOについてです。
そもそもの”WEB”の理解から学んでいきます。
・ SEOは無料で作れる資産
・ SEOは無料で雇える営業
・ SEOはファッションである
とありました。
これの意味が読み終える頃には理解できるはず、、!です。
WEBってなんですか?

ここで皆さんに質問です。
意外といろんなマーケターの方とかでも、
知らない人が多かったりします。
大体の人は答えられません。
・WEBって何ですか。
・WEBって誰のものですか。
なので名前の由来や、その歴史的なところから
実際にWEBを熟知して、そのウェブ上である googleのブラウザ
というところから紹介していきます。
一度この情報を全部インプットしないと深い理解につながらないためです。
WEBというのは、世界中の情報をつなげること、リンクすること。
で、その世界中の情報がリンクされた、つながった状態のことです。
色々な情報が繋がっている様が、蜘蛛の巣のように見えることから
WEB=蜘蛛の巣。という感じです。
WEBって誰が作ったの?

次にWEBって誰によって作られたのか?
まず初めにGoogleというのはウェブではないです。
WEBというのは、「ティム・バーナーズ=リー博士」によって
作られたものなんです。
この博士がものすごく天才的な方でして。
上記画像にある「WWW」をみなさん観たことあるかと思います。
「world wide web」という略語で、世界中の情報がつながっているクモの巣のようにつながっているイメージから「www」というものを開発しました。
余談にはなりますが、この「www」は
もともと「the information maine」という名前にしようとか
そういう話もあったみたいです。
これ情報鉱山という意味なんですが、
それぞれの頭文字を取るとT,I,Mなのでティムになってしまい
それはやらしいからと言って結局「www」になったみたいなんです。
なんとも謙虚な方ですね笑
そしてなぜ博士がこのWEBを開発したのかというと。
そもそもスイスの巨大な研究機関があり、
「CERN/セルン」と呼ばれている研究機関です。
もちろん今でも存在しています。
この研究機関で、いろんな研究者たちが研究をしているんですが、
とても巨大な研究機関の為、たくさんの従業員がいます。
それぞれの研究者が論文を出したり、研究文書を出したりなど
情報が散漫してました。
で、その情報が散漫してるのを研究機関側からまとめてくれないか?
というタスクを博士に投げたところから始まっています。
いろんな研究機関で散乱している情報を
1つにまとめる任務を請け負ったわけです。
資料室があった
そして昔は研究機関の中に、資料室っていうものがありました。
研究室の中にあったわけです。
なので、その資料室を管理している人に聞くことで、
お目当ての資料に辿り着いていたということです。
そうすることで文章とか研究の内容っていうのを取得していたんです。
で、これをもう少しわかりやすく整理してくださいね。
っていうのがこの博士が実際に請け負った任務なんです。
では、どういうふうに整理したのか?
ここが後ほどWEBというものに対して内容が繋がって行くとこです。
HTMLを使用
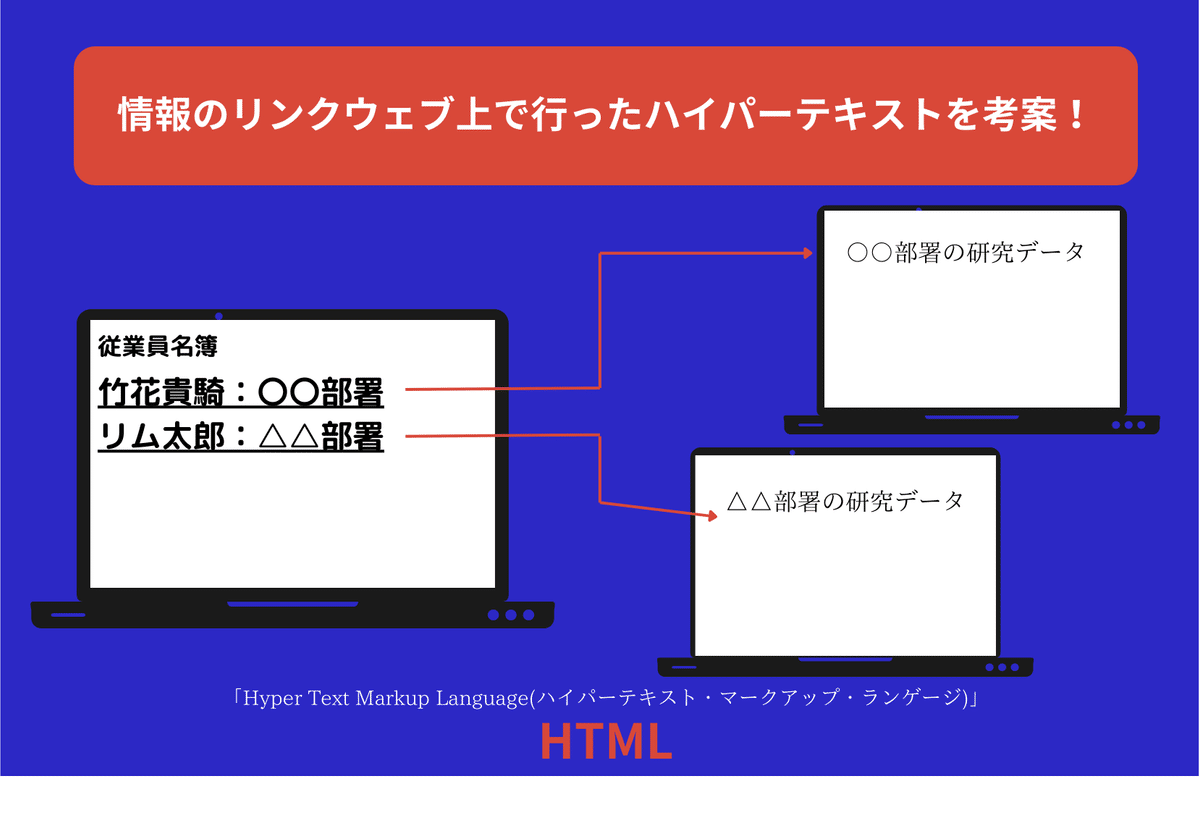
”情報のリンク”というのをWEB上で行ったハイパーテキスト
っていうのを考案したんです。
昔のWEBサイトとかっていうのは、ただ文字を書いて
それを画面に映しているだけ。みたいなものが昔のパソコンでした。
例えばwikipediaとか見ていただくと分かるんですが、
文字の上にハイパーリンクになります。(青くなっている箇所です)
文字を押すと違うページに遷移します。
今じゃ当たり前のように使用されています。
このハイパーリンクを作ったのがこのティムさんがです。
「この情報」と「ここにある情報」と「ここにある情報」をリンク。
みたいな使い方です。
これがウェブの始まりなんです。
では、ウィキペディアのようなこの画面をどういうふうに作りますか?
という時に「hypertext markup language」という言語で作成しました。
これが俗にいう「HTML」と呼ばれているものなんです。
なのでいろんなサイトがhtmlで作られたりJavaで作られたりとかしています。
人類初のWEBサイト
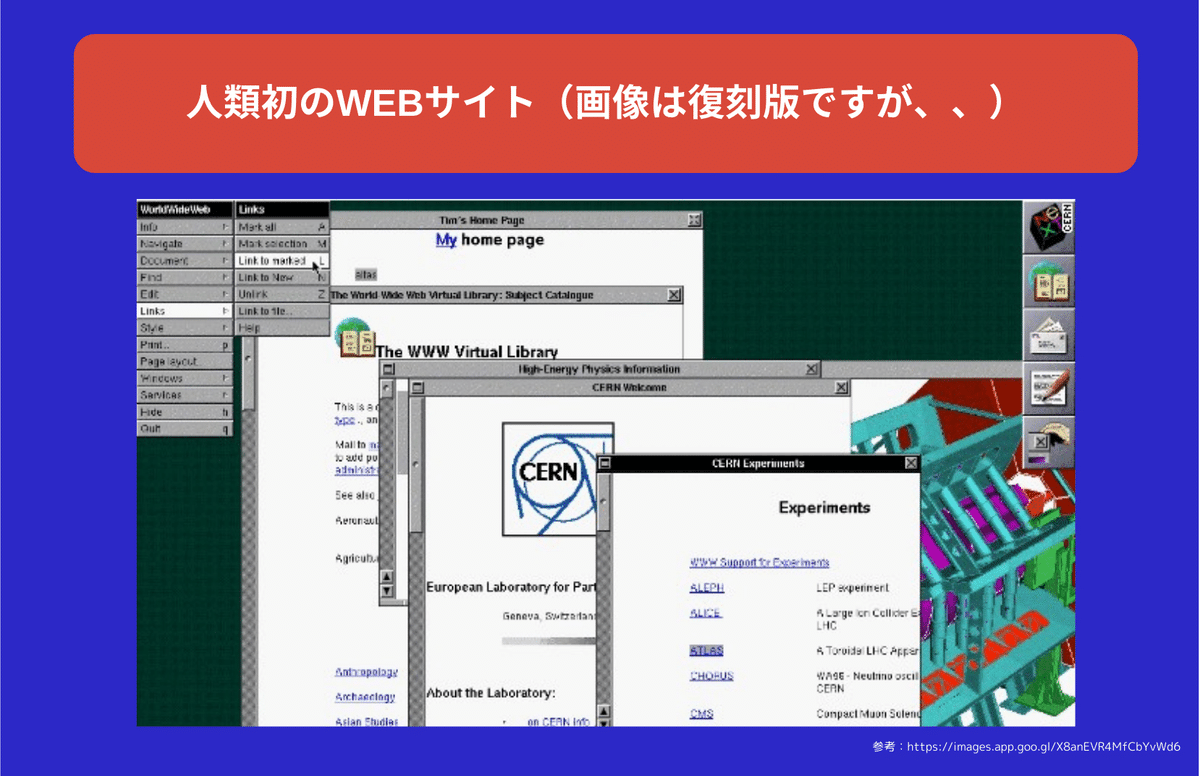
そしてこれが人類初のウェブサイトといわれる world wide webです。
このテキストにこんな感じでリンクが張られるようになりました。
青字部分を押すと実際に指定のページに飛びますとか、
情報と情報が初めてリンクされた人類初のウェブサイトです。
これによって世界の情報は全部繋がったわけです。
昔は資料室に積まれていた情報がハイパーリンクによって
「この資料」には「この資料」が関連づいてるよ。というように
情報がリンクされたわけです。
これがウェブサイト時代を圧倒的に変えた一歩目なんです。
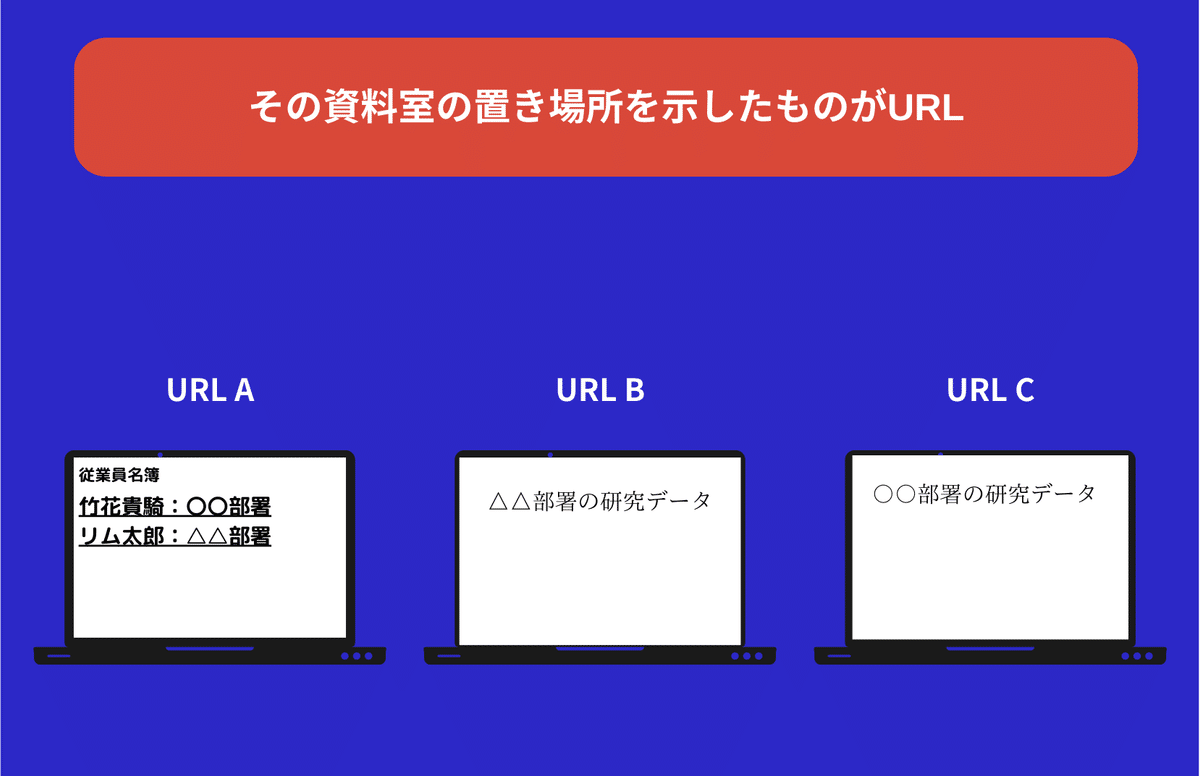
その上で資料室で、この情報ってそこの段の3段目にあるよ。とか
指定して探してたんですけども、リアルな世界の資料室でも
その置き場所っていうのがあるわけですよ。
その置き場所がWEB上にも存在していて「URL」と呼ばれるものなんです。
場所を表すURL
次なんですが、例えば皆さんレストランにいくとした時に、
ビールください。
ってサーバーに言うとします。
サーバーというのは、ウェイトレスの事を英語でサーバーというのですが、全く同じイメージです。
サーバーの方にビールが欲しい。というと、
このサーバーがビールを運んできてくれると思うんですが、
何かをほしいと要求して何かを提供する。
というのが連携がWEB上で同じように作られています。
これがHTTPといって「hypertext transfer protocol」と呼ばれるものです。
これは「注文と提供」なんです。
日本語で頼んでも、サーバー側も日本語を理解するから
注文した時にビール欲しいと伝えてビールが来るんです。
もし皆さんレストランで、アメリカのレストランにいくとします。
その時に日本語でビールが欲しいと伝えても何も理解してくれないですよね?
なので共通言語が必要なんです。
この共通的な言語がこの「HTTP」と呼ばれる
URLの先の一番最初についています。
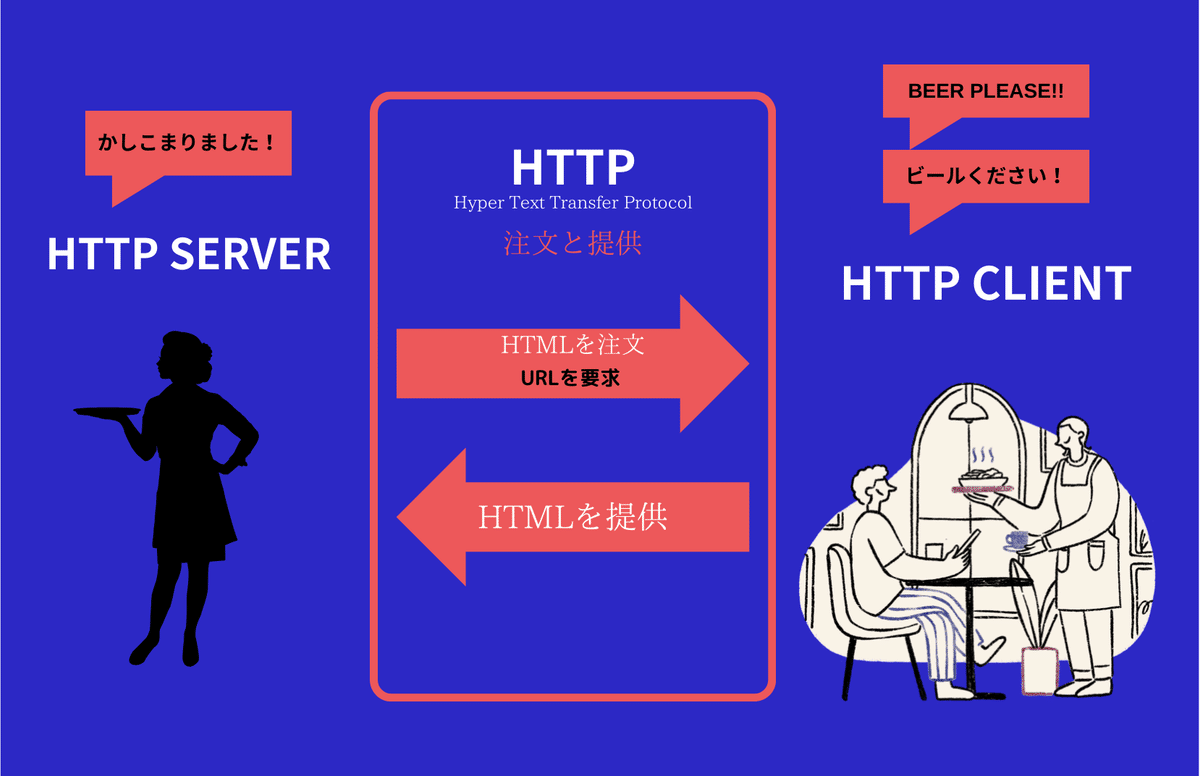
「HTTP」という決まりの中で要求して提供される。
この仕組みになってるわけです。
ここでビールがほしいと言いました。
ただビールが欲しいです。と言ってもビールって
実は何千種類、何万種類も世界にはあるわけです。
サーバーが一個一個出されても、
これと、これと、これと、これね!って言っても
おそらく混乱すると思います。
そして混乱すると情報が多いので理解できない状態になります。
なので情報を整理して表示するデザインを持つサービス。
それがWEBブラウザって呼ばれるものなんです。
なのでGoogleというのは正しくはWEBではないということです。
WEBブラウザなんです。
例えば「firefox」とか「yahoo」、「google」などブラウザによって
情報整理サーバーがくれた情報をどう表示するか?というのは違います。
ではこのWEBブラウザというのは、
基本的にどういう風にして情報をデザインしていくのか?というと
3つに分けられていきます。
・クローリング
・インデックス
・ランキング
というものです。
ただ今回少し長くなりそうなので次回の記事に分けようと思います!笑
次回は「クローリング・インデックス・ランキング」について
の解説から始めていこうと思います。
今日はこの辺で!
====================
他人と差をつけるならまず見るべきはこれ:
毎日1分インスタで知識配信:
https://www.instagram.com/takaki_takehana/
ユアユニオンラインスクール無料入学:
https://www.ur-uni.com/?original_id=100011503
X(旧Twitter):こちら
====================
この記事が参加している募集
この記事が気に入ったらサポートをしてみませんか?