
データ分析の初めの一歩はCSV読み込み

データの受け渡しに多く使われるのがCSVファイルです。データ分析の第一歩はこのCSVファイルを各ツールにインポートするところから始まります。ここではデータ分析で頻繁に使われるR、Pythonとデータの加工に便利なSQLをデスクトップで使えるマクロソフトのAccessとオープンソースのBASEへインポートする方法を解説します。
練習用データを取得する
データを取得します。今後多くの場面で使うだろう、人口のデータを使うことにします。人口のデータは総務省統計局の統計データサイト「e-Stat[1]」から取得することができます。
データの検索窓に「人口推計」と入力し、検索結果から「人口推計」を選びます。今回は「人口推計 / 2019年10月1日現在人口推計[2] 」を使います。

データを取得するために、DBボタンを選択します。

そうすると、以下のような表が現れるはずです。

これは、縦方向(表側)に都道府県、横方向(表側)に年齢区分が示される表となっています。このように縦横の要素の組み合わせに対しての集計値を示した表をクロス集計表と呼びます。クロス集計表は表を人間が解釈するには便利なのですが、データを加工する立場からすると何かと扱いづらいことが多いです。そこで、データのダウンロードでは「列指向形式」を選びます。データの名前である「ヘッダ」は表示とします。ファイル形式は、CSV[3] というテキストデータの形式です。

ファイルをダウンロードしたら(「ダウンロード」というフォルダに入っていることが多い)、クリックをしてファイルを開きます。多くの場合[4] 、エクセルが起動することになるでしょう。するとこのような感じのデータが表示されます。

この中で1行目から27行目はデータの説明部分なので、分析には直接使いません。切り取ってデータ部分のみを保存しましょう。

ファイル名を「JP_POP_DATA.csv」としました。ここでも後ほどいろいろツールで分析しやすいようにCSV形式を選択します。
RとPYTHONからCSVファイルを読み込む
では、まずRにデータを取り込むこととします。データをtest_dataという変数に格納しましょう。CSVファイルの読み込みには、read.table()という関数を使います。
ポイント:ファイルの指定のためにパスを入力します。この時Windowsでよく使われている”\”マークは使えません。”/”を使います。
test_data <-
read.table("(ファイルの格納ディレクトリ)/JP_POP_DATA.csv",
header=TRUE, sep=",", na.strings="", dec=".", strip.white=TRUE)ここでのパラメータは以下のような解釈になります。
・ヘッダー(データ名)があるかないか?今回はあり。 header=TRUE
データの区切りはCSVなのでカンマで区切っている。 sep=","
・データがブランクの場合の表記、何も入れないなら空欄にしておく。 na.strings=""
・データ区切りの後に空白(スペース)が入っていても無視する。 strip.white=TRUE
・より詳しいパラメータの説明は、ヘルプを見るとよいでしょう。
help(read.table)
これを見るとread.tableよりCSVを読むためのコマンドread.csv()というのもあります。どれを使ってもよいのですが、Rコマンダーという簡易GUIを使うとパラメータの設定も選択式になっていて手間が省けます。(Rコマンダーからのデータの読み込みは、別途)
次にPythonでデータを読み込みます。RやPythonでは表形式のデータのことをデータフレームと呼んでいます。Pythonでデータフレームを扱う便利機能が入っているのはPandasというライブラリです。まずこのPandasを呼び出してここではpdというところに格納しておきます。このライブラリの関数を呼び出すには、Pandasライブラリが格納させれているpdの関数read_csv()を使います。関数の呼び出し方がは、pdの中の関数ということで、pdにピリオドをつけて関数名を入力します。
import pandas as pd
test_data = pd.read_csv('(ファイルの格納ディレクトリ)/JP_POP_DATA.csv', encoding='sjis')これで入力が完了です。
テキストデータと一言で言いますが、日本語が入ってくると実は結構厄介です。日本語のコードが何かがわからないとエラーや文字化けの原因となります。今回はウィンドウズを使って例題を作っていますので、日本語コードが”SJIS”となっています。
MICROSOFT ACCESSとLIBREOFFIC BASEにCSVを取り込む
データの抽出・加工に欠かせないSQLについて学ぶために、ここではパソコンで操作可能なMicrosoft Accessと、ウィンドウズだけでなくLinuxなどでも動かせるLibreOfficeのBASEへCSVファイルを取り込む方法について解説します。なお、LibreOfficeとOpenOfficeはほぼ同じような操作で動きますので、ここでの解説が役に立つでしょう。
なお、データベースの世界では、表形式にあたるものは、データテーブル、もしくは短く、テーブルと呼んでいます。
まずアクセス(Access)です。どこかに分析用のアクセスのファイルを新規で作成します。その後、外部データのインポートを行います。CSVファイルは、テキストファイルなので、テキストファイルのインポートを行います。

そうすると、インポート用のウィザードが起動します。
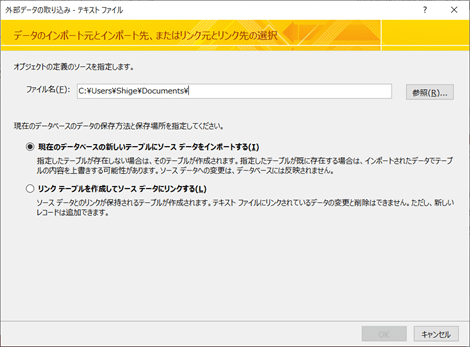
ファイルを指定して次に進みます。

CSVファイルは、カンマ区切りのデータなので、上のチェックボックスを指定。データベースの場合、データの型を決めなければならなので、左下の「設定」をクリックします。

Accessがファイルを見ながら、仮でデータ型を選んでくれています。「フィールド名」がデータの名前になります。「長整数」がいわゆる大きな桁まで扱える整数です。通し番号に使えます。ここでvalueが、実際の人口(千人単位)になります。小数は使われていないので、長整数で構いませんし、倍精度などの数値型を使ってもかまいません。ここでインデックスについて指定するか否かについては、割愛します。
設定を終了し、「次へ」進みます。ここで改めてデータ型について聞いてきますが、設定で指定しているのと同じなので割愛します。

「次へ」を押すと、主キー(プライマリーキーとも呼ばれる)について尋ねられます。これも今は割愛します。「いいえ」で進みます。

「次へ」に進むと、データを保存するデータテーブルの名前を尋ねられます。ここではtest_dataとしています。

これで「完了」を押します。特にエラーがなければ、これで終了となります。最後の画面で、「インポート操作の保存」を聞いてきます。データのインポートは、データがアップデートされるたびに発生する作業で、その手順を保存しておくと後ほど便利です。それらの操作を定型化するためのツールです。便利なツールですが、今は説明は割愛します。

うまくいけば、目論見通りのテーブルができているはずです。

次に、LibreOffice BaseへのCSVファイルのインポートを行います。こちらはBaseだけでなく、途中のプロセスでLibreOfficeの表計算ソフト、Calcの機能を一部使います。
まず、Baseを起動します。Accessと同様に、ウィザードが起動してどこにどんなデータベースのファイルを作るか聞いてきます。
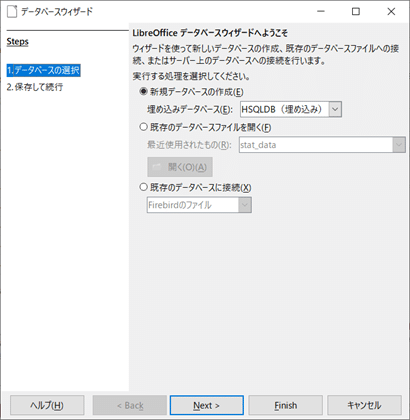
まずは、新規データベースの埋め込み型で構いません。データベースを登録するとかしないとか、あまり関係ないですが、CSV読み込みでデータをつくるので、いいえを選択しておきましょうか。
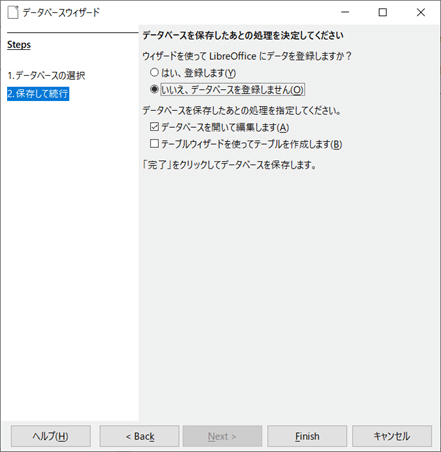
これで空のデータベースファイルができます。

次に、LibreOffice Calcを開けます。そこからファイルを「開く」を選択し、CSVファイルを選択します。すると、ウィザードが起動します。このウィザードはそこそこ賢くて、データの位置を見極め、この場合2行目からがデータだと認識します。データベースにはヘッダも入れたいので、ここは1行目からにします。
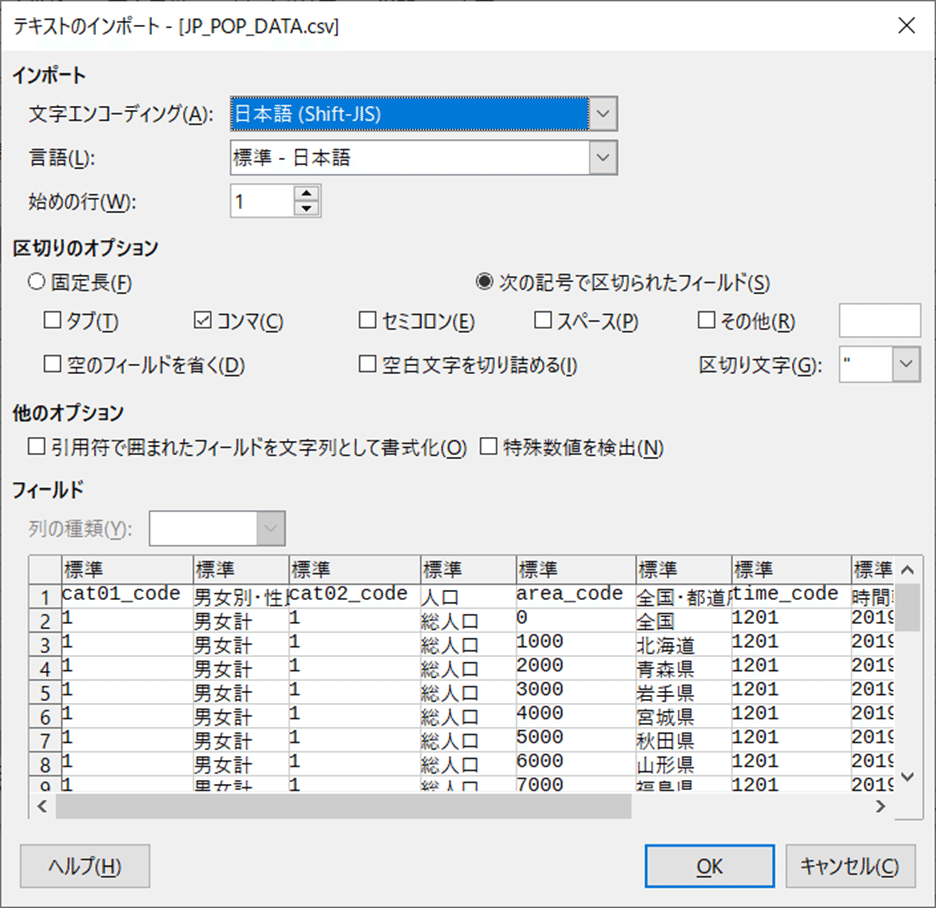
データが読み込めたら、全体をコピーします。やり方はいくつかありますが、Ctrl+AをしてCtrl+Cだとコピーができます。

続いてBaseに戻ります。編集にて、貼り付けを選択します。そうすると、Accessの時のように、ウィザードが起動します。

まずテーブル名を入れます。同じようにtest_dataにしておきましょう。

一行目をカラム名、というところにチェックするのを忘れずに。ここでカラム名と呼んでいるのは、表頭部分のヘッダ、データの名前だと思ってください。データベースで使われる用語になります。ここでもプライマリーキーの話が出ていますが、割愛。(データベース設計では重要な話なのだが・・・)「次へ」向かいます。するとウィザードでは、どのデータをインポートするか聞いてきます。とりあえず全部選択します。

その後、データ型を聞いてきます。最後のvalueは数値なので、必ず数値の型を選択してください。〇〇_codeとなっているところは連番なので、整数を選んでおくとよいでしょう。

「完了」へ進むと、再びプライマリーキーに関するメッセージが出てきます。これくらいプライマリーキーの概念は重要なのですが、今は割愛。「いいえ」で通過します。

これでインポート完了。アイコンとしてtable_dataができています。クリックをすると、データの内容が見られます。


では、次回以降、データの操作についてみていきましょう。
注釈
1] e-Stat 政府統計の総合窓口 https://www.e-stat.go.jp/
[3] comma-separated valuesの略。データをカンマでデータを区切ったテキストで記述したファイルの形式のこと。
[4] Microsoft Officeを使っているコンピュータの場合はほとんどがCSVファイはエクセルと紐づけられています。Linuxを使っている人なら、OpenOfficeやLibreOfficeのCalcが起動するかもしれません。
この記事が気に入ったらサポートをしてみませんか?