
Adobe Firefly を使いこなしたくて仕方ないデザイナーのお話

こんにちは、今年になってAIデビューしたジャガーです。
最近、画像生成系のAIを色々触ってみたりしてたのですが、めちゃくちゃおもしろいですよねえ。
だって自分で描かないのに絵ができるんですもの。
絵を描くって結構大変なんですよ。
学生時代にいっぱい勉強して、いっぱい描いて、いっぱい失敗して、なんとかいっぱしの絵を描けるようになるまで数年かかりました。
そんなぼくよりも数段うまい絵を数秒で描けちゃうんですから。
すごい時代がきましたよねえ。
AIを使いこなすデザイナーになりたい
のです。
画像生成系のAIが現れてから、日進月歩・秒進分歩で進化を続けておりますが、弊社のデザインチームでも日々の業務に活用すべく色々触ってみている次第でして。
現在は、主に「midjourney」を使用しており、AIの導入によりカンプやイメージボードの制作時間をかなり短縮することができていたりします。
すごいよ、AI。
そんな中、先週あたりに問い合わせていた「Adobe Firefly」から、やっと招待メールが届きました。
画像生成だけでいうと、わりと後発ですよね。そんな中、満を辞して発表したわけですから、何かしら強みがあるのではないかなと期待して待っておりました。
さて、Adobe Fireflyで何ができるのか。デザイナーにとって心強い存在になってくれるのか。を、ぼくなりに見ていきたいと思います!
Adobe Fireflyでできること
現状のベータ版ではText to image(テキストから画像へ)とText effects(テキスト効果)の2種類のみが使用できるようです。
が、順次色々と機能が追加されていくようですね。
今後の展開が動画にまとまってました。
ぼくなりに、実際のデザイン業務に活かせそうかどうかも含め見ていきたいと思います!(解釈間違ってたらごめんなさい)
機能1:Text to image(0:05〜0:10)

これは最早おなじみですね。
や、ちょっと前までテキストから画像が生成されることにすんごい驚いてたのに、おなじみになっちゃってることに世の中の流れの早さを感じます。
midjourneyなどと比べて、こちらの精度はどんなものなんでしょうか。ベータ版でも使用できる機能なので、後ほど触ってみようと思います。
機能2:Extend image(0:11〜0:13)

背景を自動で拡張してくれるっぽいんですが、これ、何気にめちゃくちゃ便利かも!
画像の横幅が足りないー!なんてことはよくあることで、シンプルな画像ならコピースタンプツールとかでちまちま足したりしますが、複雑&大幅に足りない場合はいくら良い画像でも諦めたりしちゃってました。
そんな悩みが解決されたら泣いちゃいます。
機能3:Inpainting(0:14〜0:23)

これもめちゃくちゃ便利!
いいモデルが見つかったのに服がイメージと全然違う。。なんてこともよくあることで。
服だけ別の画像からもってきて、光源やら明るさやらコントラストやら色調やらをモデルの画像に合わせて、なじませて、、みたいなことをやっていた過去とはおさらば!ってことでいいんですよね??Adobe 先生!
機能4:Smart Portrait(0:24〜0:30)

これは今でもPhotoshopの「ゆがみツール」である程度できることだと思いつつ、項目を見てみると「目線」とか「ライティング」とかもありそうですね。光源とか変えれるなら激アツなんですが、どうやって変えるのかな?
機能5:Depth to image(0:31〜0:35)

これは、画像の深度に合わせて、壁面やオブジェクトのテクスチャとかを変更できるってことなんですかね?
であればこれも激アツです!
パースやアングルはベストなんだけど、壁面はウッドじゃなくてコンクリがイメージに近いんだよなあ ってこともしばしばあって、その都度テクスチャを探してはパース変えて合成して。って作業をもうしなくていいんですよね!?Adobe 先生!
機能6:3D to image(0:36〜0:43)

ぱっと見た感じ、Adobe Substance的なものかな?と思ったのですが、3Dモデルをベースに、プロンプトで画像が生成できるっぽい。
これまた激アツ!
動画にもある感じの「城みたいなケーキ」とかが作りたいときって結構あるんですよね。いやほんとに。
しかも、好きなアングルを指定して生成できる感じっぽい。
3Dソフトいじれない僕としては、どれくらい3Dモデルが入ってるのかが気になります。
機能7:Text to template(0:44〜0:52)
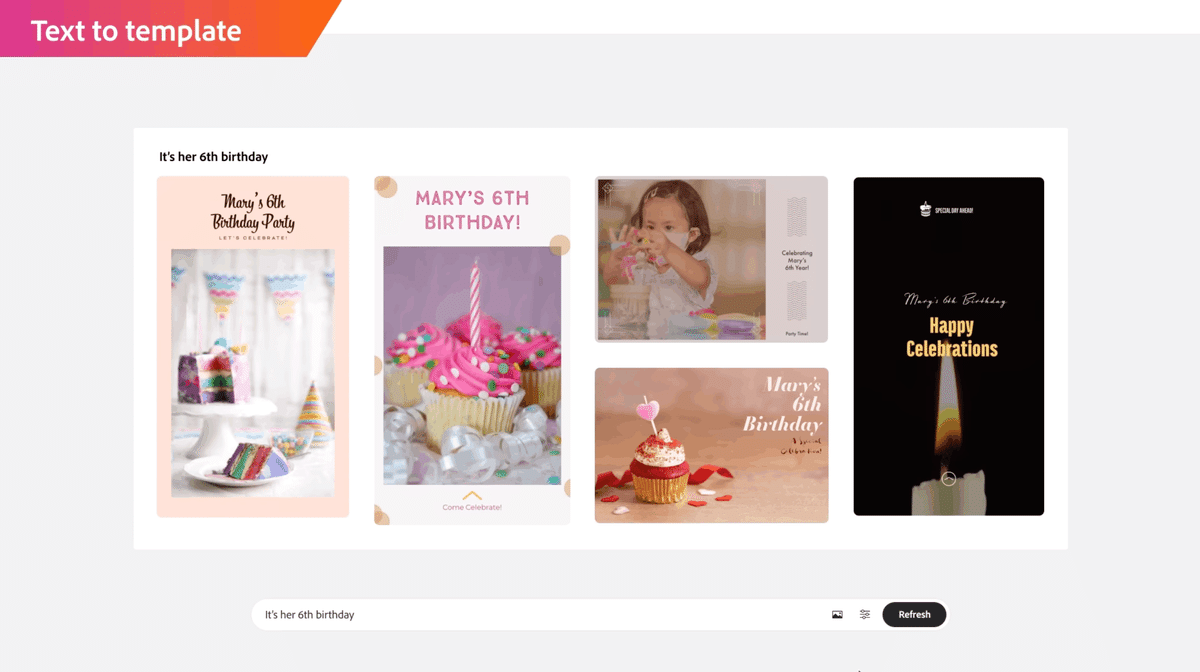
テキストからデザインテンプレートを作成してくれるようですね。
うーん。これはちょっとイマイチかも??
こういうデモ映像って、実際よりも良く見えるに作ったりするケースが多いと思うんですが、それでこのクオリティなのであれば、少なくとも実制作で使うことはなさそうです。
(しかし、クオリティが上がれば、これはいろんなデザイナーの驚異となる気もします)
機能8:Conversational editing(0:53〜0:58)

一瞬、Text to imageとの違いがわからなかったのですが、一枚の画像をベースに色々足していける感じですかね?
Text to imageでベースの絵を生成して、細かい処理を少しずつ足し算していく みたいな使い方になるんでしょうか。
これはこれで便利かもですねえ。
機能9:Text to Vector(0:59〜1:10)

あー、これもちょっといいかも。
画像のオートトレース → ベクター化 がなかなかうまく機能しないので、はじめからベクターになってくれてたらありがたいシーンも結構ありそうです。まあ、生成される絵のクオリティ次第ではあるのでどこまで期待していいのかはわかりませんが。
機能10:Combine photos(1:11〜1:18)

複数枚の画像を同時にアップすると、マッシュアップしてくれる機能のようですね。下部にあるフォームに「Describe the image you want to create」とあるので、ある程度アウトプットの指定ができるのでしょうか。
であれば、場合によっては「Text to image」よりも使い勝手がよいシーンもでてくるかもですねー!
機能11:Color-conditioned image generation(1:19〜1:27)

参考にしたい画像を左側に放り込んで、下のフォームにプロンプトを入力すれば、参考画像の「色」を抽出して、生成するイメージに反映してくれるっぽい。参考画像がアウトプットとかけ離れたものでも、あくまで色参考として扱ってくれるのか。
生成した画像の色味が、プロンプトだけではなかなかうまくいかない時も結構あるので、そういう時はかなり役にたちそうー
機能12:Upscaling

もうこれはスーパー便利!!
素敵な画像なのにサイズ足りない!って何度泣いたことか。。
画像拡大のツールを使ってみたり、PhotoshopCC2018から追加された「ディティールを保持 2.0」を使ってみたりしていましたが、いまいちその効果を感じたことがなく。
ほんとうに、ほんとうにこんなに滑らかに画像をアップスケールできるなら最高ですよ。動画を見る限り「×6」まであるし。
Text to imageで生成した画像を、Upscalingで6倍にしてそのまま印刷へ みたいな未来も待っていたりするのでしょうか。
総評
ひとまず動画で紹介されていた機能をざっと見てきましたが、テンション上がっちゃいました。
一つひとつがとても便利な機能だと思うんですが、使い方や使い所を理解したうえで複合的に使うことで、業務効率をぐっと上げることができそうな予感がしています。
そして、この「複合的」というのがAdobeの強みな気がします。
画像生成を含め、デザインプロセスを効率的に進めるための機能として昇華されているのが素敵。
Text to imageにしても、学習ソースが「Adobe Stock」なので、商用利用可能になる(ベータ版はだめですが)というのも激アツポイントですね。
これは、うまく使いこなせないと生産効率という点で大きく遅れをとりそうですし、それが最終アウトプットのクオリティにも直結しそうな予感がしています。こわい。頑張らねば。
本当にこのクオリティで実装されていることを切に願っておりますよ、Adobe先生!!
Adobe Firefly(ベータ版)を使ってみる
と、色々書いてはみましたが、まずは使ってみるのが早いですよね。
ということで、Adobe Firefly(ベータ版)で使用できる「Text to image」を使ってみます!
【Text to image】
検証したいのは「どれくらいイメージに近い絵を生成できるのか」です。まあ、他の生成系AIでもイメージに近い絵はなかなか出てこないんですが、とりあえず目標は高くということで。
今回は、弊社の自社プロジェクトである「MoAR - Museum of AR」が、まだ世の中に出ていないと仮定して、その中で登場する「emoc」というぽっちゃりしたピンクのキャラクターをイメージ通りに生成できるのか を試してみたいなと思います。
この子ですね。emocちゃん。
弊社のビルの上で愛らしく踊る(AR)キャラクター。
キャラクターデザインは、弊社所属シニアデザイナーの「伊藤太一」です。その見た目とは裏腹にとてもかわいいイラストを描く敏腕デザイナーです。
この子がまだ伊藤太一の頭の中にしかない世界線のお話です。
さて、emocちゃんは無事産まれるのでしょうか。
STEP1 : とりあえずそのまま入力
使い方は、他の画像生成系AIと同じですね。UIはわかりやすい!
早速入力フォームにプロンプトを入れていこうと思いましたが、はっきりと「英語のみ」と書かれていますね。
ちなみにぼくは英語力皆無なので「DeePL」を介して英訳するのがマストです。言葉のニュアンスが合ってるのかどうか判断できないのでそろそろちゃんと英語を勉強しないとなと焦ってます。
さて、ではまずはそのまま「ビルの上で踊るぽっちゃりしたピンクのキャラクター」を英訳してフォームに突っ込んでみます。

こっわ!!
まあ、そうなりますよね。。笑
やってみただけ。やってみただけ。
ちなみに、右カラムにある「コンテンツタイプ」や「スタイル」を選択すると、同じプロンプトのままイメージを変えることもできました。
この辺り、直感的で非常にポイント高いです。

STEP2 : 特徴点を追加してみる
シンプルなプロンプトだとあまり良い結果にならなかったので、さっきよりもキャラクターの特徴となるキーワードを追加してみます。

おお、さっきよりイメージに近づいた気がする!
まだ全然遠いけど、左下がまだ近い?
こんなとき、該当するサムネイルにhoverすると「似たようなものを表示」というボタンが出てくるので、ポチってみます。

ど、どこがやねん!!
1ツ目になってるし、肌青くなってるし。
よく考えたら「似たようなもの」とかいう言葉もこわいよ。
STEP3 : あきらめたい
でも、あきらめずにもっと色々試してみます。

左下がちょっとずつ近づいてきた気がするけど、こわい。。
「Cute」って入力してるのになあ。
「monster」が悪さしてるのかなあ。
キュートなモンスターなんて存在しないってことなんでしょうか。
ひとまず「monster」を外してみました。

だめでした。意外と「monster」がいい仕事してたっぽい。
みたいな感じで、かわいさとモンスターの狭間を何度も行き来しながら、なんとかemocちゃんに近づけれるようにトライを続けました。
そして、最終的に一番近づいたのがこちら。

こわい。
着脱可能っぽい顔。
その顔の裏に回り込むサスペンダー。
黄疸のはしった目。
emocに似たようなものが産まれてしまいました。
この世界線では、こいつが弊社のビルの上で踊り狂っていたのかと思うと震える。(でも実はちょっと欲しい)
まとめ
今後、Fireflyでのアウトプットが商用利用可になった時には、生成したものをそのままポーン!と使ってみんなニッコリ。みたいな将来を期待してのトライでしたが、やはり明確なイメージをそのまま一発で出すのはとても難しそうですね。
まだしばらくは、ムードボードやカンプ用として使用することになりそうな気がしました。
アウトプットクオリティも「midjourney」の方がまだ高いように感じます。
学習ソースが「Adobe Stock」だけというのも関係しているのでしょうか。
とはいえ、まだ公開して間もないですし、ベータ版ですしね。
直感的なUIも素敵でしたし、なにより複合的な使い方ができそうなのがポイント高いので、いちデザイナーとして「Adobe Firefly」の今後にとても期待しています!
とりあえずぼくは英語の勉強するので、Adobe Fireflyには「かわいさとモンスターの狭間」を学習してほしいなあ〜
ジャガーでした。
この記事が気に入ったらサポートをしてみませんか?