
[プログラム・コード公開] コピペだけで実用的かつ実践的な線形判別分析(Linear Discriminant Analysis, LDA) (R言語)

仕事や研究において、クラス分類を行うために線形判別分析(Linear Discriminant Analysis, LDA) をする方もいらっしゃいます。LDAの実用的かつ実践的な方法はこちらに書きました。
しかし、LDAのやり方はわかっても、実際にLDAができるようになるわけではありません。ネットや本でLDAのプログラミングを説明しているものはありますが、データの読み込み方とか結果の出し方とか、他にも調べてやらなくちゃいけないこと、多いんですよね・・・。手間と時間がかかります。
そこでコピペするだけでLDAを実行可能なプログラムを作りました。下に示す形式のデータ(data.csv, data_prediction1.csv, data_prediction2.csv)さえ準備すれば、R言語でLDAができます。
●必要なもの
・モデル構築用データのcsvファイル [data.csv]
下図のように、一番上が変数の名前、一番左がサンプルの名前です。一番左の変数が目的変数Yであり各サンプルのカテゴリを1もしくは-1で表します。Yの右が説明変数Xです。サンプルの名前と変数の名前はすべて異なるものにしてください。

・予測用データ1のcsvファイル [data_prediction1.csv]
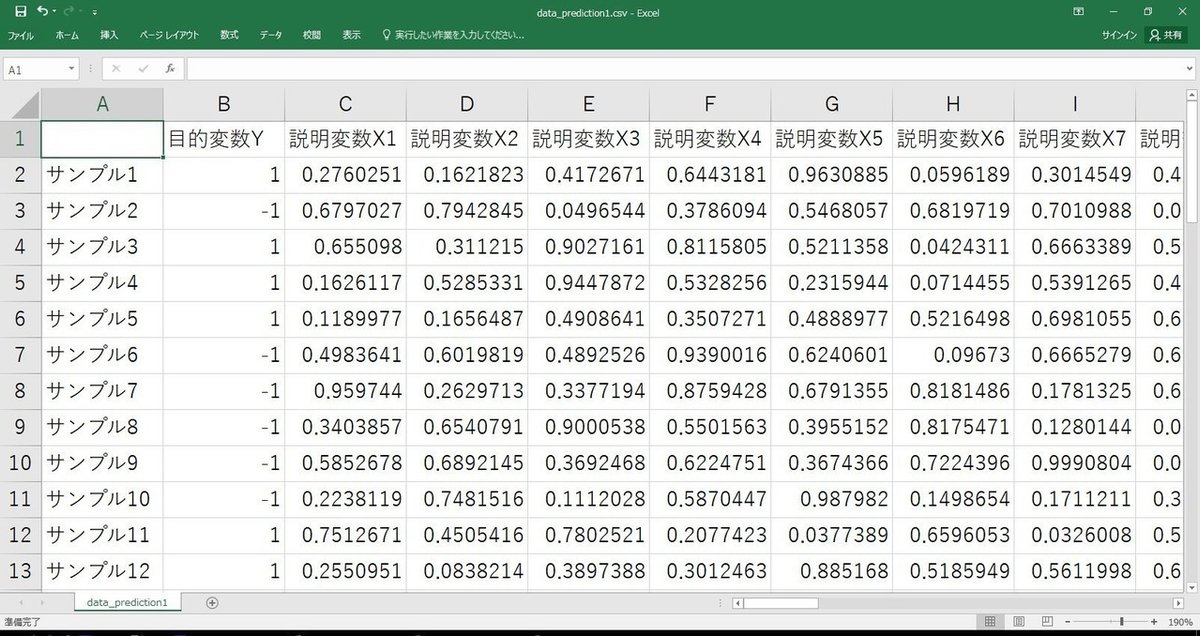
予測用データ1は目的変数Yの値が分かっている予測用データです。data.csvと説明変数の種類および個数を揃える必要があります。data.csvと同様に各サンプルのカテゴリを1もしくは-1で表します。準備できない場合はdata.csvと同じもので名前をdata_prediction1.csvとしてください。下図のように、一番上が変数の名前、一番左がサンプルの名前です。一番左の変数が目的変数Yでありその右が説明変数Xです。サンプルの名前はすべて異なるものにしてください。
・予測用データ2のcsvファイル [data_prediction1.csv]
予測用データ2は目的変数Yの値が分かっていない予測用データです。data.csvと説明変数の種類および個数を揃える必要があります。準備できない場合はdata.csvの説明変数だけ取り出したもので名前をdata_prediction2.csvとしてください。下図のように、一番上が変数の名前、一番左がサンプルの名前です。サンプルの名前はすべて異なるものにしてください。

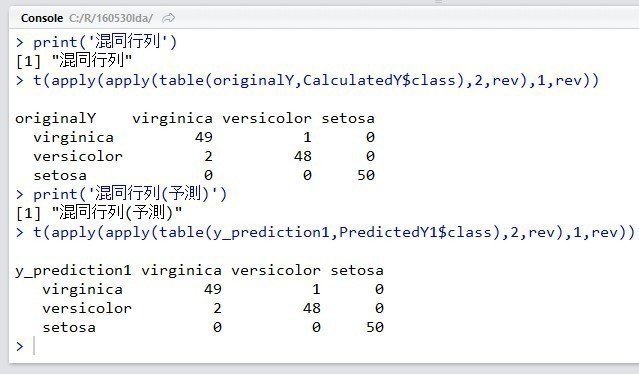
実行結果を下に示します。data_prediction2.csvの目的変数の予測値がPredictedY2.csvというファイルに保存されます。

R言語で必要なものは
RStudio [こちらではVersion 0.99.879です]
です。
もちろんLDAからスタートしてさらにプログラミングを進めたいと考えている方にもぜひ利用していただければと思います。
R言語のプログラムは有料コンテンツとします。ただペットボトル一本分で、こちらに記載したLDAをそのまますぐに実行できます。こちらからプログラムのzipファイル自体はダウンロードできます。購入していただくと解凍のためのパスワードがありますのでそちらをご利用くださ い。
ここから先は
¥ 1,480
この記事が気に入ったらチップで応援してみませんか?