
プロンプトの限界を超えて、画像生成AIで、「自分がデザインした、自分のオリジナルの髪型、服装、水着デザインや、絵画の構図や、ポーズで出力できる方法」(手書きラフ絵からAIが画像を作る「Diffuse The Rest(Stable Diffusion系)」の使い方)

前回の上の記事で、欧米の人達は、「ツインテール」の髪型の事を、「Pigtail」とまとめて呼んでいて、しかも、日本のアニメの髪型だと、
・ツインテール
・ピッグテール(Pigtail)
・おさげ髪
・三つ編み
の全部のどれでも、「Pigtail」と呼んで正しいようです。
という事がわかった。
ただ、今回、もともと自分がやりたかった作業は、「ツインテール」の髪型の微調整だったのですが、何か、イメージが違くて、自分が出力したかったのは、どうも、「ツーサイドアップ(two side up)」寄りではないのか?とかやっていたのですが、今度は、また脱線して、
・日本の床屋とかが言っている「ツインテール」の髪型の種類
に興味が移って、理由は、ベースの髪型のプロンプトを入力する時に、その「日本の床屋とかが言っている「ツインテール」の髪型の種類」の方の名称を入れた方が、出力したいイメージに近づくだろうと思った。
しかし、実際に、「日本の床屋とかが言っている「ツインテール」の髪型の種類」を英語にして、プロンプトで入力してみた所、全滅で、要するに、英語圏の髪型の単語には、そんなものは無いらしい事がわかった。
(プロンプトで入力してみた「日本の床屋とかが言っている「ツインテール」の髪型の種類」)
・エンジェルウイング(angel wings hairstyle)
・バードテイル(Bird Tail hairstyle)
・シュリンプ(Shrimp hairstyle)
・ラビットスタイル(Rabbit Style hairstyle)
(*これらのプロンプトは、髪型で入力しても使えなかった)
(ただし、年月が経って、「髪型の実際の画像」と「タグ」が大量に、データベースに溜まってくれば、当然、普通に出力できるようになるはず)
要するに、「Bing Image Creator」は、「DALL-E 3版」になってから、もうプロンプトエンジニアリングはいらないんじゃないか?と思えるほど、人間の入力した文章や単語を理解してくれるようになったのだが、「各国の独自文化発展の単語」などは、まだ、ごっそりと抜け落ちてしまっていて、出てこないようです。
<Bing Image Creator(今は、名称が、「Designer」に変わっている)で、「bunches Shrimp hairstyle」というプロンプトで出力してみた画像>
とりあえず、「シュリンプ(Shrimp hairstyle)」という、「エビのシッポのようにカールした髪型」に興味がわいたので、その髪型を出力してみようと思ったのだが、こういう髪型は、「bunches(束)」という髪型がベースなのではないか?と思って、
・Bing Image Creator(今は、名称が、「Designer」に変わっている)で、「bunches Shrimp hairstyle」というプロンプトで出力してみた画像
は次のようになって、予想はしていたが、「普通に、全然違う髪型に、エビの画像が加わっていた」

どうしようか?と行き詰まった感が出てきたのだが、考え方を変えて、「Stable Diffusion系」の画像生成AIでやってみる事にした。
「Stable Diffusion系」の画像生成AIの特殊なものに、次のように、
・手書きラフ絵からAIが画像を作る「Diffuse The Rest(Stable Diffusion系)」
というやつがあるからです。
(手書きラフ絵からAIが画像を作る「Diffuse The Rest(Stable Diffusion系)」)
https://huggingface.co/spaces/huggingface-projects/diffuse-the-rest
<「Diffuse The Rest(Stable Diffusion系)」の使い方>
上のホームページに行くと、下のような画面が出て、この画像生成AIの使い方は、
(1) 四角い白い枠内に、自分で、手書きでラフ絵を描く。

(2) その下の白い小さい枠が、「プロンプト」の英語の文字列を書く場所なので、この画像のように、「自分が描いたラフ画が、何を描きたかったのか?」の補佐となる単語を書く。
今回は、自分は、「cute anime girl, Pigtail Shrimp hairstyle」という「プロンプト」の英語を書いた。
(3) 横にある[diffuse the f rest]の青いボタンを押すと、手書きラフ絵からAIが画像を作ってくれる。
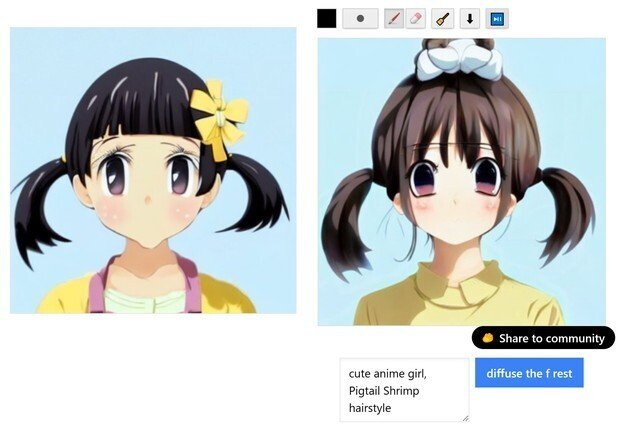
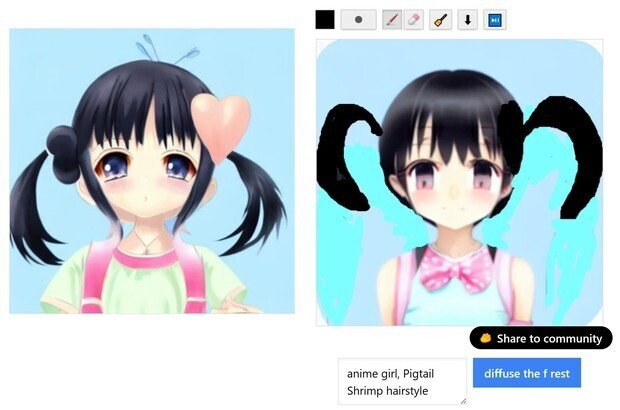
(4) 次に、画面左の画像が、「元画像(最初は、自分が描いたラフ絵)」で、右の画像が、「完成画像」で出てくる。
下の画像は、2回目のラフ絵修正中の画像。
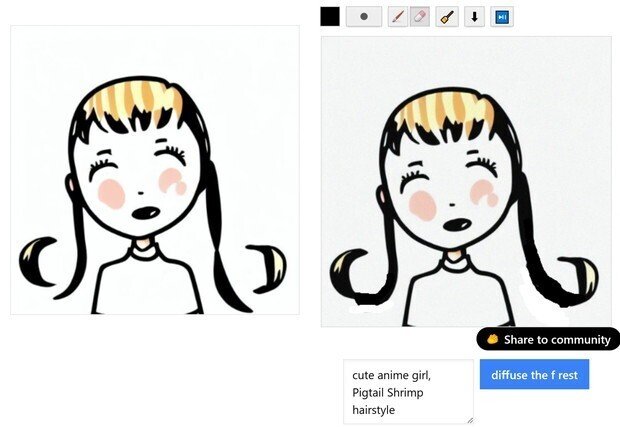
(5) 絵の上にあるツールアイコンで、右側の青い[>||]のような、音楽の次へ送るボタンのようなのがあるので、それを押すと、画像生成AIは、1回の作業で、「2~4個」の画像候補を作ってくれるので、次の画像が見れる。
(6) 気に入った画像が出力できていたら、その画像が画面に出ている状態で、隣のツールアイコンの[↓]を押すと、その画像をダウンロードできるが、「400 x 400」とかなり小さい。
(7) それで、画面右側の今、出力された画像に、「さらに、ラフ画で描き込んだり、いらない箇所を消しゴムで削除」してから、また、必要ならば、違うプロンプトの英語の単語を調整で加えたりして、この作業を何度も繰り返す事で、だんだん綺麗になっていって、自分の目的のイメージに近い画像が出力できる。
という仕組みです。
結構、根気のいる作業だが、「簡易デザインのラフ画の修正を繰り返すだけ」で、どんどん自分の出力したいイメージに近づくので、やっていて面白い。
だが、「ただのStable Diffusionは、そもそも、それほど綺麗な絵は出ない」ので、大体、今回、自分が出力した最終画像位が限界なので、そこでやめます。
(8) 次に、この「自分がラフ画でイメージ通りデザインした画像生成AIが出力した、髪型や、ポーズの構図など」の最終結果の出力画像を、「ポーズなどの指定画像」を使えるタイプの、他のStable Diffusion系などの画像生成AIへ持っていって、「AIモデル」で出力すれば、「今まで、Stable Diffusion系だと、プロンプトエンジニアリングでは絶対に不可能だった、自分のオリジナルの髪型や服装や、水着デザインや、絵画の構図や、ポーズで出力できる」というわけです。
ただ、「AIモデル」を動かすには、かなりのグラフィックボードのメモリ量が必要なので、自分の貧弱なパソコンではできない。
<手書きラフ絵からAIが画像を作る「Diffuse The Rest(Stable Diffusion系)」を自分が使ってみた、やった順番と画像の変化>
(1) 最初の自分が描いたラフ絵

(2) 最初は、ラフ絵からなので、かなり滅茶苦茶の候補しか出てこないが、その中でも、とりあえず「女の子の顔」になっていて、近い髪型の画像を候補に選んで、髪が途中で切れてしまっているので、「またラフ絵で継ぎ足して描き込んで、下の青いボタンを押して、再出力した」
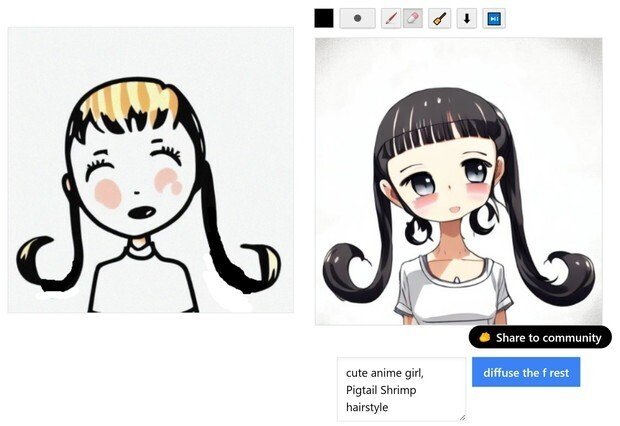
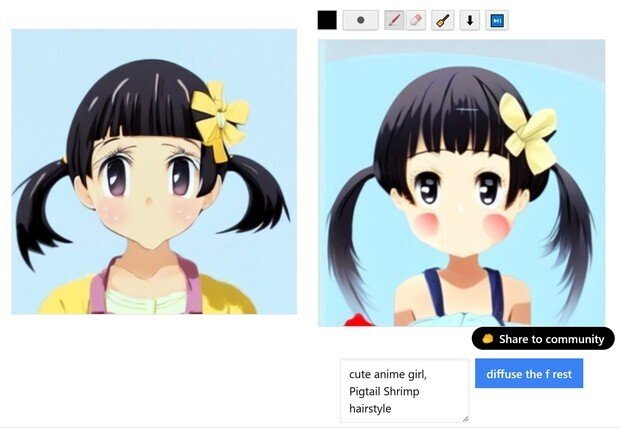
(3) 今度は、わりと普通な女の子の顔が2つできた。
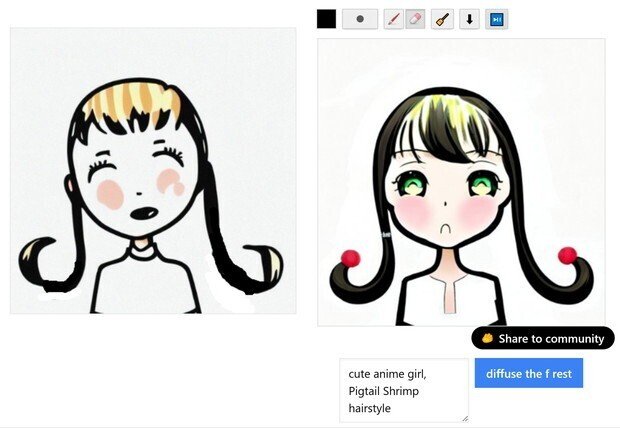
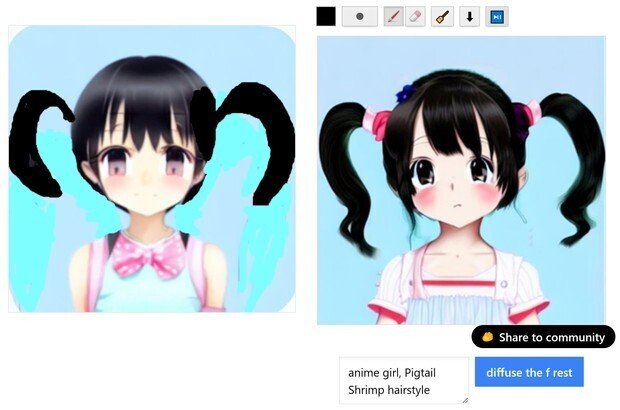
(4) だが、「シュリンプ(Shrimp hairstyle)」という、「エビのシッポのようにカールした髪型」を普通の画像検索で、「こっちの方向のカールで良かったのか?」と検索してみると、実際の髪型は逆のカールっぽい。(どっち向きのカールでもいいような気もするが)
「逆じぇねーか」
という事で、今出力した画像で、良かった方の髪型を消しゴムで消して、必要なラインに描き直した。
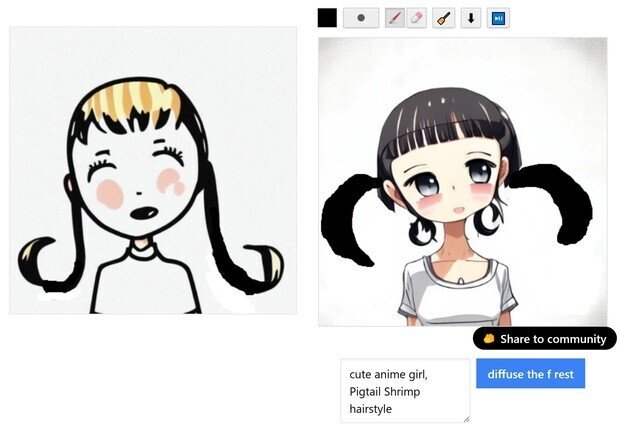
(5) 「おお、普通の、「シュリンプ(Shrimp hairstyle)」という、「エビのシッポのようにカールした髪型」の画像が出た」のだが、実写だった。
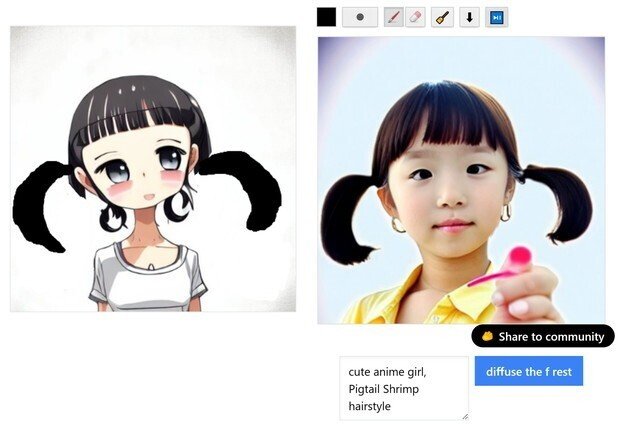
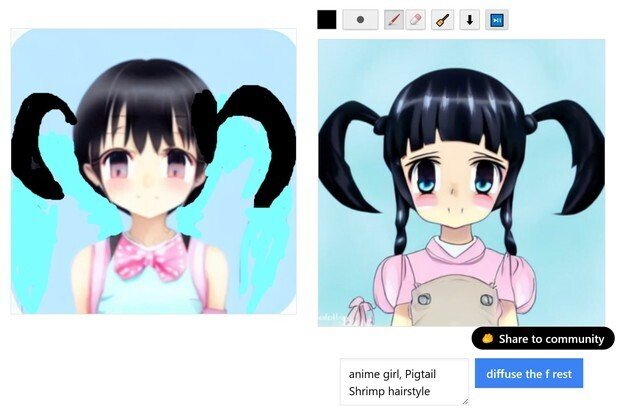
(6) そのまま、何も、ラフ画変更せずに、青いボタンを押して再出力を何度かすると、「どうも、オリジナル元絵を再び選ぶと、1回の出力だけで、JPG圧縮を10回やった位、元絵は劣化する」ようです。
結局、何回か、この作業を繰り返した結果が、次のように変化していった。
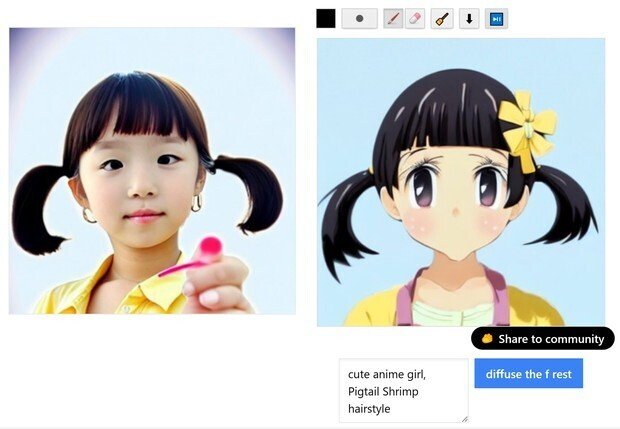
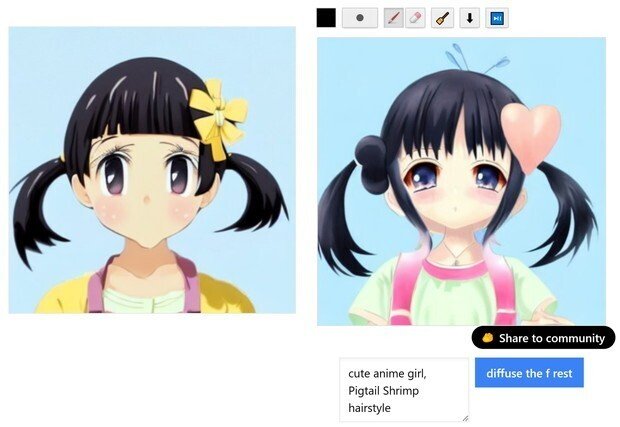
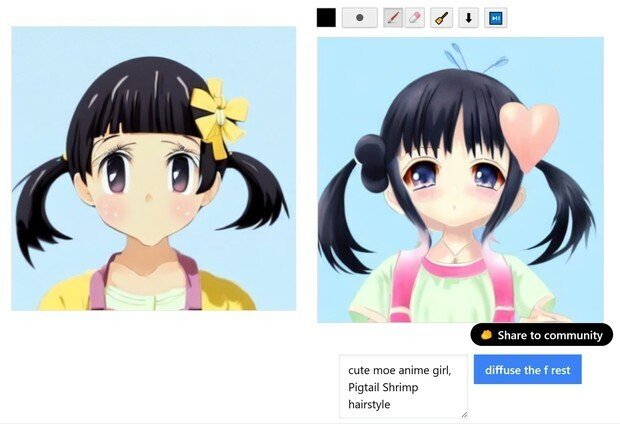
(cute moe anime girl)にしてみた。
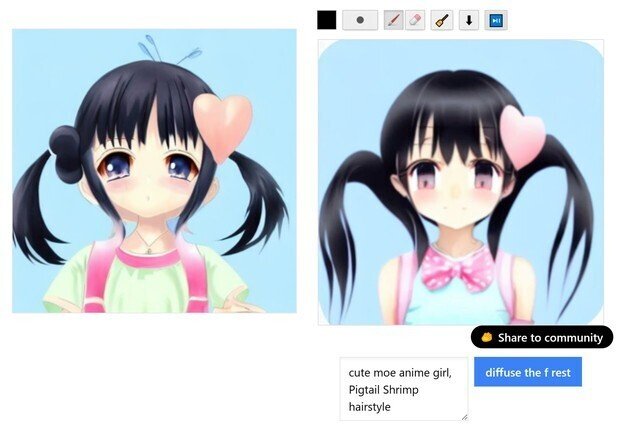
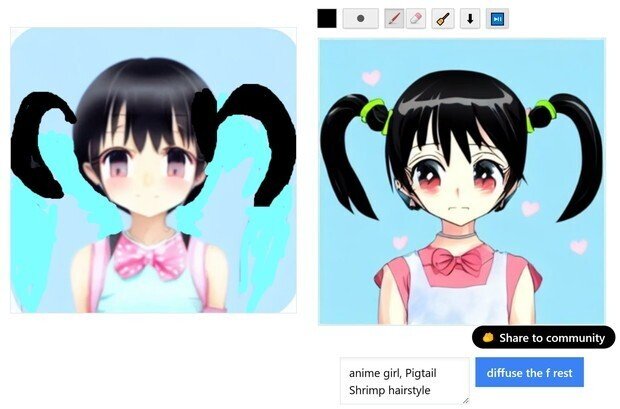
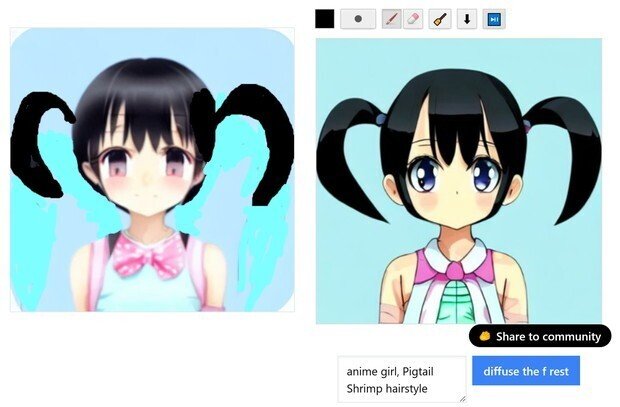
(7) 最後は、普通のStable Diffusionだと、この辺りが限界っぽい綺麗さになったので、プロンプトの英語に、「3DCG」と加えた所、大体、この位のクオリティーが、普通のStable Diffusionだけだと限界なので、これで、完成となった。
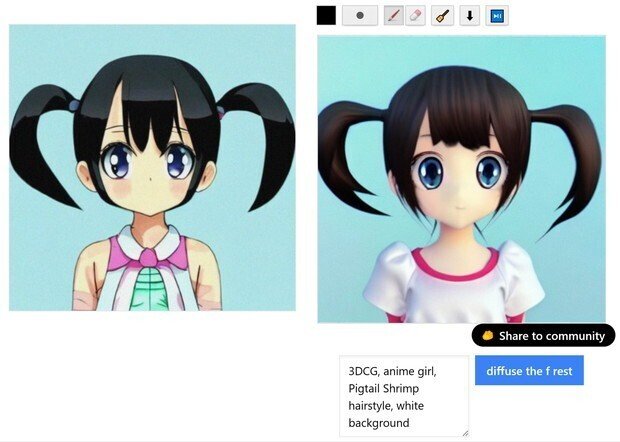
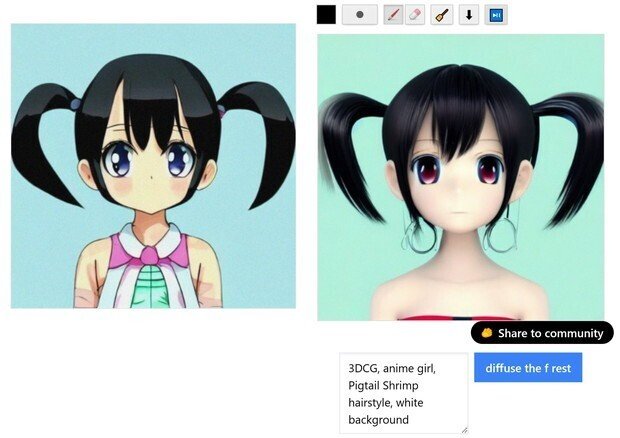
だが、塗り直しが面倒なので、(white background(白背景))のプロンプトの指示を入れたのに言う事を聞かない。
(8) さらに、プロンプトでアレンジしたい場合には、このように、「Science fiction」をさらにプロンプトに加えたら次のようになった。
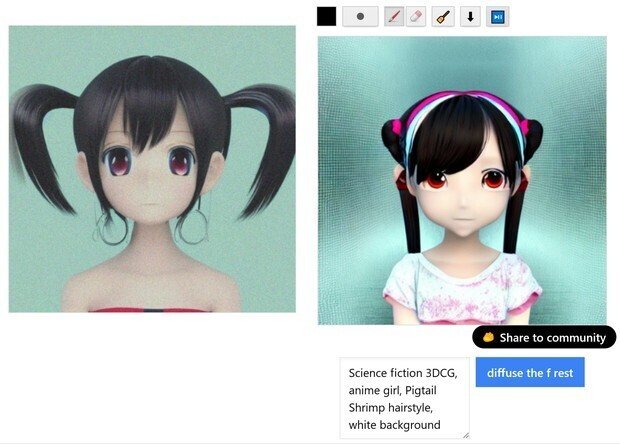
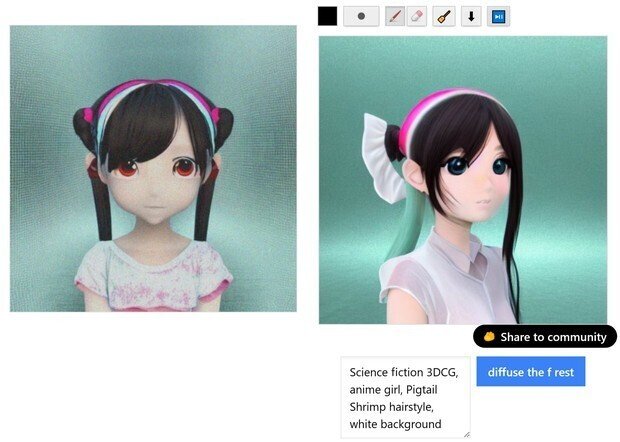
髪型は消えてしまったが、このような作業を繰り返す事で、「プロンプトデザイン」の作業は、また新しい手法で、「自分のイメージしたい通りのデザイン」に近づけていけるようになったようです。
(9) 先程説明した通り、最後は、この「自分がラフ画でイメージ通りデザインした画像生成AIが出力した、髪型や、ポーズの構図など」の最終結果の出力画像を、「ポーズなどの指定画像」を使えるタイプの、他のStable Diffusion系などの画像生成AIへ持っていって、「AIモデル」で出力すれば、「今まで、Stable Diffusion系だと、プロンプトエンジニアリングでは絶対に不可能だった、自分のオリジナルの髪型や服装や、水着デザインや、絵画の構図や、ポーズで出力できる」というわけです。
この手法を使えば、「AIモデル」と「プロンプト」の文字列だけを使っていて、もうデザインに限界がきていて、「同じような画像しか作れなくなった」とスランプにおちいっている人も、「自分がデザインした、自分のオリジナルの髪型や服装や、水着デザインや、絵画の構図や、ポーズで出力できる」というわけです。
この記事が気に入ったらサポートをしてみませんか?