
セグメンテーションを用いた被写体切り抜きとパーツ分け

こんにちはこんばんは、teftef です。今回は,セマンティックセグメンテーションを使って画像内の被写体抽出をただ試すだけという記事です。いくつかの論文と手法をベースにしていますが、詳しいことは書かない予定です。Google Cloab も配布しているのでぜひ最後まで見ていただけると幸いです。
私もまだ初学者であり、説明が間違っていたり勘違いがある可能性が 0 ではないということをご了承ください。ぜひコメントなどをいただけたら幸いです。また、この記事を作成するにあたり、GPT-4 による校正、修正が含まれています。
※この記事は有料となっていますが、最後まで内容が読めます。
被写体抽出
被写体抽出は画像や動画から被写体をし区別し、それを他の要素から分離するタスクであり、Live2D のパーツ分けや AR・XR 、Web カメラの背景ぼかしなどに使用されています。しかし、このタスクは難易度が高く、特に Live2D のパーツ分けには、一つの画像を細かいパーツに正確に分ける必要があり、多くの時間と労力を必要とします。それゆえに Live2D モデルを制作する際に数十万単位の費用が掛かってしまいます。また、ミーティングなどでリアルタイムで背景をぼかしたいときに被写体抽出を行いそれ以外の部分にブラーをかけることで実現しています。このタスクでは機械学習を用いており、そのリアルタイム性では高く評価されるも、正確性については大きく劣っているという問題点があります。
今回は、様々な用途で需要がある被写体抽出タスクをより簡単に短時間で行うことを最終目標とし、その過程でセグメンテーションを用いることに焦点を当て、どのようなものが有用であるかをいくつかまとめていきます。
セグメンテーション
セグメンテーションは画像から対象の領域を区分するタスクであり、その中でも
b) : セマンティックセグメンテーション
c) : インスタンスセグメンテーション
d) : パノプティックセグメンテーション
の3つに大別できます。今回、被写体抽出に用いる手法として (c) , (d) を採用します。

近年の機械学習の進歩により、セグメンテーションによる広範な画像解析の能力向上と、被写体抽出による特定のオブジェクトへの焦点を活用することができ、より複雑で高度なタスクを効果的に処理できるようになりました。機械学習を用いてセグメンテーション手法を用いて画像内の特定の領域のみを抽出することを試みます。
Segment Anything
1年ほど前に発表された Meta の Segment Anything Model (SAM) は、ラベル付けされたデータ(教師ありデータ)とラベル付けされていないデータの両方を用いて半教師あり学習を行っています。初期段階である程度学習されたモデルを用いて、ラベル付けされていないデータに対して予測を行い (人間が修正することもある)、それらを新たな学習データとして利用しています。このようにすることでラベル付けのコストを低くし、また新たな概念に関しても学習することができるようになっています。

さらに Prompt としてキーポイントやバウンディングボックス、マスク、テキストを入力として、そのPrompt にが指し示す領域を推定してくれます。
今回の被写体切り抜きと相性がいいように見えますが、テキストは未公開であり、キーポイントやバウンディングボックス、マスクは少し設定が面倒なので、単純にセグメンテーションされた領域が最も大きい部分を被写体として抽出します。(性能を確かめたかっただけなので、使えるようであれば後で追加すればいい)
結果



評価
こんな感じで悪くはない結果ですが、少し粗が目立ちます。ついでにパーツ分けの性能を見てみると左目がうまく分けられてなったり、手と腕が分離されてなかったりするので、少し難しそうです。
コード
SoM-GPT4V
Segment Anything だけで被写体抽出を行うことができそうですが、被写体が 2 つ以上あった時にどちらを抽出するのかを選択したり、たくさん物体が移った画像の中で特定のオブジェクトだけを抽出できるようにしたいです。そこで GPT4 を途中に挟むことによって、使用者の指示に沿ったセグメンテーションを行うことができます。
しかし画像を GPT4 に入力しただけでは、うまくセグメンテーションマスクを作成することができないという問題があるため、GPT-4 に対してビジュアル情報を追加してあげます。( Set-of-Mark(SoM))

Set-of-Mark(SoM)では SEEM、Semantic-SAM、SAM などのセグメンテーションのフレームワークを用いて、画像の領域を区分すると同時にそれぞれの領域に通し番号を割り振ります。画像と通し番号の情報を GPT-4 との対話に挟むことによって、使用者が指定したオブジェクトをより正確に抽出することができます。(通し番号付きの画像をそのまま GPT-4 に渡すわけではないので注意。通し番号はあくまでも画像を分析する際の参照ポイントです )
結果
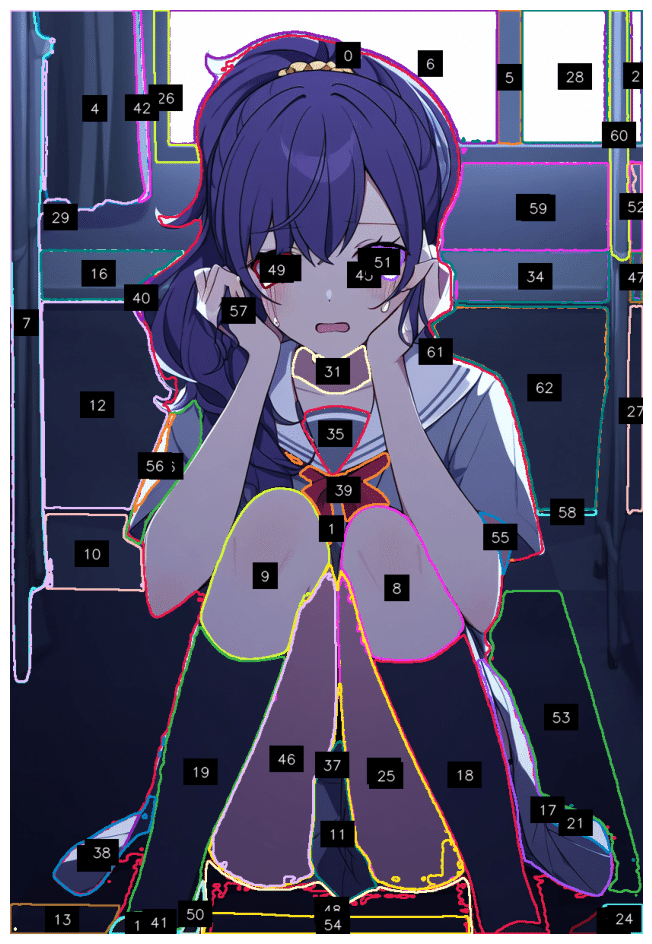
60 個ほどの領域に分割されましたが、これだと多すぎるので、必要なもの (ある程度の大きさの領域、可変) のみを抽出します。

続いてこれらの情報を GPT-4 に入力します。
ここで Prompt として、
"Find subject of photografy. notalk;justgo"
と入力しています。

このように複数の領域のマスクが出力されるので、
その中から欲しいものを選ぶんで、被写体を抽出してあげます (この作業を挟むのが厄介)

追加実験

このような複数の被写体が移った画像に対して、「左の被写体抽出」「右の被写体を抽出」と指示を与えたときの違いを見てみましょう。

この時点で、左の緑色の被写体に対してセグメンテーションできていない…

ここで Prompt として、
"Find subject in the right side of the photo. notalk;justgo"
"Find subject in the left side of the photo. notalk;justgo"
とそれぞれ入力しています。
追加実験の結果
右側はうまく抽出されました。しかも、マスクの候補は 1 つだけだったので、選ぶ必要がありませんでした。

左側はそもそもマスクが出てきませんでした…
評価
画像に対して、「どこの領域の何を抽出するか」の指示を出せる点で、 Segment Anything に比べて利便性は格段に上がりました、また、被写体が複数いる状態でも、何を抽出したいかを自然言語で伝えられるという点で、アプリケーション向きでしょう。
しかし、やはり学習されたデータセットがアニメ画像ではないので、セグメンテーションが完ぺきではないということがあります。 SAM のファインチューニング次第で大きく変わるのではないかと思います。
コード
Powerful Multi-Task Transformer for Dense Scene Understanding
では、画像の部位ごとのパーツ分け (特に体のパーツ) を目標に、探してみました。この手法は Depth マップ , 法線マップ、エッジ、セグメンテーション、Saliency の抽出をマルチタスクで行う手法です。マルチタスク学習手法は多くの CV 分野(顔認証、医療画像処理, VLMs etc…)で見かけるようになっていて、各タスクの汎化性能が大きく上がるといった利点があります。しかし、ネットワークが大きくなったり、必要なデータを用意するのが大変だったりとデメリットもあります。
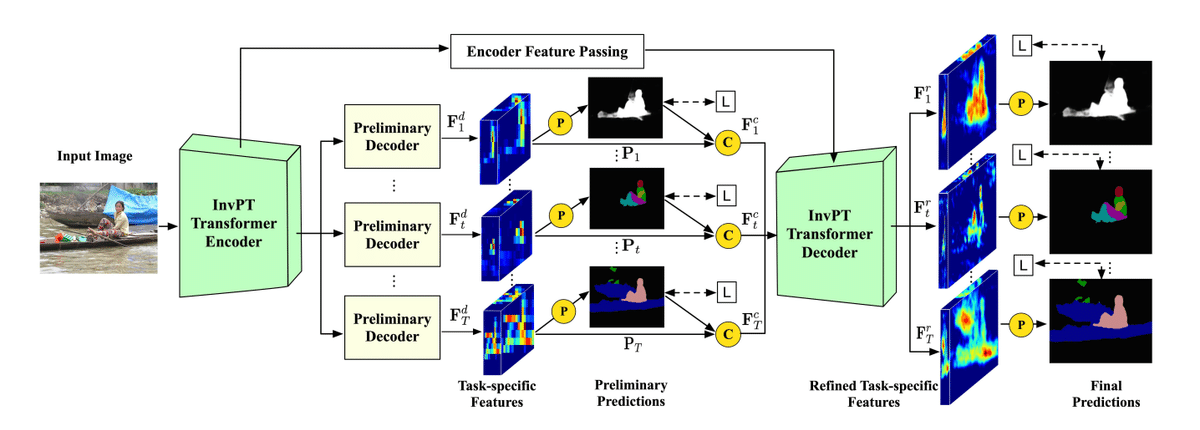
ここでは Inverted Pyramid Multi-task Transformer (InvPT) と呼ばれるマルチタスク学習のためのフレームワークを用いています。このフレームワークは、入力画像から視覚的特徴やパターンを学習するための Transformer エンコーダーと、各タスクごとに特化された特徴と予測を生成するための Transformer デコーダーから構成されています。最終的な出力は、空間的および全タスクの相互作用をグローバルにモデリングすることで、高解像度の特徴タスクごとに生成できます。
結果

評価
学習に使った画像データセットが、アニメ画像ではないので、アニメ画像に対するセグメンテーション結果はあんまりよくないです。でも Human part Segmentation では顔、胴体、腕、上腕の区別がしっかりできていて、顔に髪の毛がかかっている部分を頑張って抜こうとしてるのが伝わる。被写体の Edge 抽出 は別にわざわざ機械学習を使わずに OpenCV 使えばいい気がする。Saliency は初めて見たので、良し悪しの判断がつかないので、割愛。
総評としてはいまいちだが、データセットをしっかり整えてファインチューニングするだけで、複数のタスクを同時にできるので、期待できます。
コード
CartoonSegmentation
昨今のセグメンテーションタスクを行うモデルの学習データにアニメ画像があまり含まれていないため、CartoonSegmentationではアニメ画像用いて独自のセマンティックセグメンテーションデータセットを構築しています。
これによってアニメ画像に対する性能 (IoU) が大幅に向上しています。

また、ネットワーク構造も大きく分けて 2 段階になっていて、低解像度でマスクとバウンディングボックスを大まかに予測します。続いてのステージでは先ほどの粗いマスクのリファインを行い最終的に高解像度のインスタンスを抽出します。このステップでより詳細な画像解析を行い、精度の高いセグメンテーションを実現します。(詳しくは別記事で書きます。)
結果


もう少し例を見てみます。



このように左の髪の毛が跳ねている部分までしっかりと抜けていることがわかります。
追加実験の結果
では、複数人を抜きたい場合を見てみましょう



しっかり抜けていますね。続いてもっと複雑な画像で試してみると

このように、少し荒いですが、しっかりと個人個人がセグメンテーションされています。
コード
まとめ
被写体抽出した結果をまとめておきます。
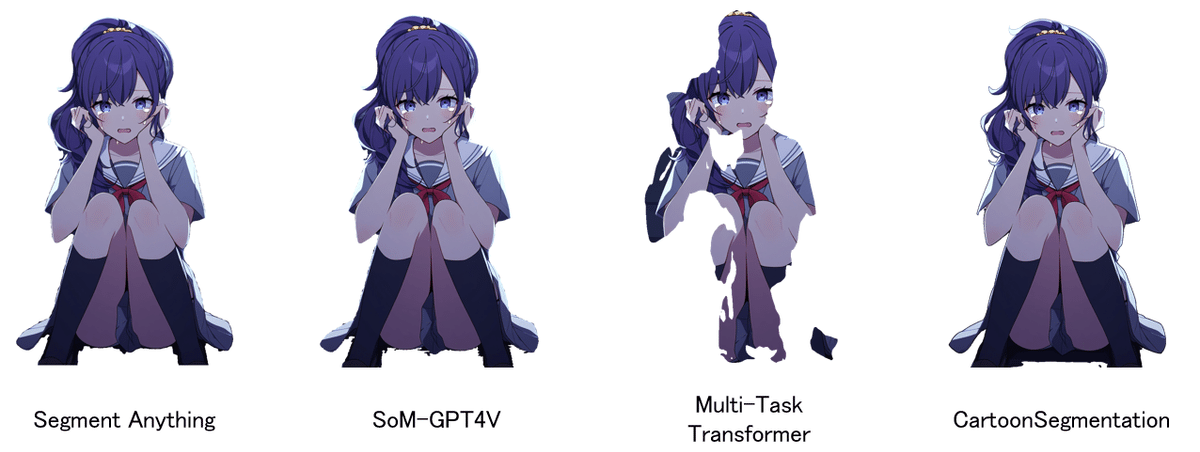
まあ、個人的には CartoonSegmentation が最もいいかなーと思っていますが、 SegmentatAnything や SoM-GPT4V では汎化性能が高いという点で見ると、アニメデータセットを使ってファインチューンし時にさらに性能が上がるんではないかと考えています。
おまけ
Person Segmentation in the Browser with TensorFlow.js
Zoom や Meet で使われる背景ぼかしに使われています。 Web カメなどを起動して、リアルタイムで人物をセグメンテーションすることができてます。しかし、もちろん精度はそこまでいいわけではないので、今回は見送りですね。(リアルタイム性という面では断トツです。)

リアルタイムで、ここまで分けられるなら十分だと思います。
参考文献
最後に
というわけで、キャラクターのパーツ分けを自動化しようという目的で、セグメンテーションタスクがどのくらい使えるのかというのを4 つの手法の結果を出しながらまとめてみました。 CartoonSegmentation に関しては、読んでいて、非常に気になったので、別記事でまとめるかもです。
最後に少し宣伝です。主のteftefが運営を行っているdiscordサーバーを載せます。このサーバーでは Midjourney やStable Diffusionのプロンプトを共有したり、研究したりしています。ぜひ参加して、お絵描きAIを探ってみてはいかがでしょう。(5,300 字,teftef)
↓↓もしよろしければこの記事と開発の支援お願いいたします!
※注意 : 支援してくださる方へ
※注意 :ここから先は何も内容がありません。しかし、この記事をお読みいただき、良かったと感じていただけたのであれば、この記事と開発の支援お願いいたします!
ここから先は
¥ 500
この記事が参加している募集
この記事が気に入ったらチップで応援してみませんか?