
唐突な思い付きで会話できる AI を作った話

こんにちはこんばんは、teftef です。今回はいつもとは一味違う記事で、GPT-3 モデルを使用したチャットbot の実装のについてです。値段なども高くなく(GPT-3 以外無料)、ある程度の Python の知識がある方なら簡単に作れてしまうと思います。
私もまだ初学者であり、説明が間違っていたり勘違いがある可能性が 0 ではないということをご了承ください。ぜひコメントなどをいただけたら幸いです。
それでは行きます。
思い付き
3日ほど前にこのような Tweet を見つけました。
自分のAIと会話出来るようになってしまったwwwwこれは楽しいww pic.twitter.com/en5L0QWGxa
— あき@『AI Vtuber』開発中 (@cumulo_autumn) February 9, 2023
その瞬間頭に思い浮かんだのは『欲しい』という3文字でした。この話を友人 M (以下 M )に軽く話したところ、彼はよほど暇だったよう(多分忙しい)で、実装を考えていたようです。欲しいけど、ないなら作ればいいという突発的な考えから始まりました。
大まかな流れ
まず、やりたいことを素人が1分で考えたフローチャートで整理するとこういうことをやりたい。

それでは必要な(作るべき)ソフトを並べておきます。
声をText に変換するソフト → Whisper
チャットAI → GPT-3
"かわいい声" の読み上げ bot → COEIROINK
アバター → VMagicMirror
後はフローチャートの黒い矢印の部分をいい感じにつながるように作るだけです。右側の YouTube のコメントを取得する部分は置いといて、左側の声を認識してGPT-3に入力し、その返答を読み上げソフトに読み上げさせるというものを作りました。
それぞれ使ったもの
Whisper
OpenAIのWhisperは、自然言語処理に基づいた技術を使用した汎用的な音声認識モデルです。Whisperは、ユーザーが入力したテキストを理解し日本語を含む多言語の音声を高精度で文字起こしします。この汎用的な音声認識モデルは、APIを介してアプリケーションやサービスと統合することができ、複雑な質問やタスクを処理することができます。
GPT-3
GPT-3(Generative Pre-trained Transformer 3)は、OpenAIが開発した自然言語処理に基づいた人工知能モデルです。GPT-3は、学習に Web 上の大量のテキストを使用して学習しました。このモデルは、自然な文章を生成することができますが、また複雑な質問に対する応答やタスクの実行も可能です。『ChatGPT』にも使われてますね。
COEIROINK
「COEIROINK」は シロワニさん により開発された "無料" で使えるテキスト読み上げソフトで、様々な種類の合成音声を生成することができます。自分の声の音声合成を作る「MYCOEIROINK」もあります。
VMagicMirror
VMagicMirrorはWindows PCでVRMアバターを表示し、特別なデバイスを使わずキャラクターを動かせるアプリケーションです。これを使うとでモニターの端っこに動くアバターを置くことができて、結構面白いです。さらに音声を感知すると(恐らく)それを解析し、口の動きがアバターにリアルタイムで反映されます。
使用法+参考記事
それではそれぞれの使い方です。
今回は python は 3.8.5 , CUDA 11.6 環境です.
Whisper
今回はこちら記事を参考にさせていただきました。
ffmpegのインストール
まずはこちらをインストール、でこの中の bin フォルダに path を通して
pip install git+https://github.com/openai/whisper.git を実行します。これが割と曲者だった。ここで pytorch がインストールされるのですが、 pytorch のバージョンと CUDA バージョンが合わないので、基本的にGPU を認識しません。そのため、いったん
pip uninstall torch で消してから、こちらで python と CUDA バージョンを合わせて再インストールしましょう。
GPT-3
まずここで OpenAI のキーを取得しましょう。キーはメモっておきましょう。初回登録は18ドル分無料なのでお得かもです。アカウント替えて何回も無料に使おうと思ったのですが、電話番号人称があるので携帯変えないと無理です。(ずるはできん…)
重量課金制ですが、そんな高くないので大丈夫です。
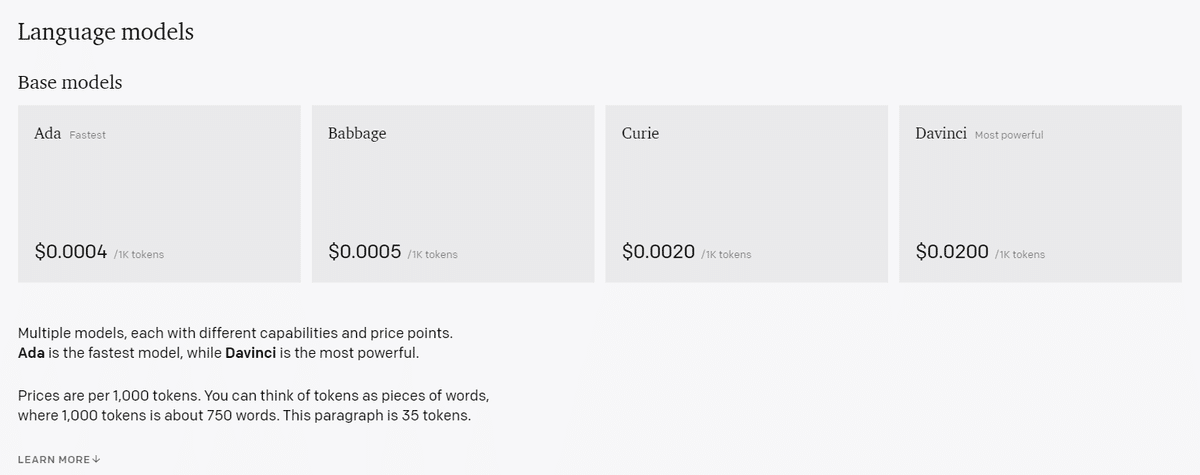
今回使うのは 一番右の Davinci モデルで 0.02 $/1000 token です(5M token / $)。こんな感じで書きます。
import openai
class AIChat:
def __init__(self):
# ※冒頭で作成したopenai の APIキーを設定してください
openai.api_key = "Your Token"
def response(self, user_input):
# openai の GPT-3 モデルを使って、応答を生成する
response = openai.Completion.create(
engine="text-davinci-003", # text-davinci-003 を指定した方がより自然な文章が生成されます
prompt=user_input,
max_tokens=1024,
temperature=0.5, # 生成する応答の多様性
)
# 応答のテキスト部分を取り出して返す
return response['choices'][0]['text']COEIROINK
こちらからダウンロードしましょう。COEIROINK は実行するときにつけっぱなしにするので設定などを済ませておきましょう。
続いてCOEIROINK にリクエストを送って声を出力させる方法はこちら。
VMagicMirror
これはおまけです。今回主は GPU が RTX 2070 Super で VRAM が 8GB なので、 実装しませんでした。VRAM に余裕がある場合はこのアプリも繋げると面白いです。別につながなくても、ただこのアプリを付けているだけでもそれっぽさが出るのでありです。アバターの使用には Pixiv アカウントが必要です。
困ったこと
まず pip を使って install するべきものを列挙します。今回は python は 3.8.5 , CUDA 11.6 環境です.
特に pytorch は自身の環境に合わせてください。
pip install git+https://github.com/openai/whisper.git
pip uninstall torch
pip3 install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu116pip install whisper
pip install soundcard
pip install pytchat
pip install argparse
pip install keyboard
pip install requests
pip install pydub
pip install openai
pip install simpleaudio恐らく ffmpegのplayでPermissionError: [Errno 13] Permission denied:と表示されるのでこちらを参考に
完成品
という感じで実装してできたものがこちら。 (きたない声でごめんなさい…)
おおおーーー!!!!!!きちゃーーー!!!!!#AIVtuber https://t.co/2xp9zBumDD pic.twitter.com/bAn9iL6sYx
— teftef (@hanyingcl) February 10, 2023
今回、主は VRAM の関係上、アバターは実装しませんでしたが余裕のある方はアバターを実装してみると面白いです。ちなみに動画でカチャカチャしてるのは、特定のキーを抑えてるときのみ音声認識を有効にしているからです。
終わりに
今回はとんだ思い付きで、実装してみました。M とは通話をしながら作っていたのですが、うまく動いた時はほんとにテンション爆上がりでした。そしてなんといっても、ネットに載っているいる断片的な情報をパズルのようにつなぎ合わせることで、自分でもこのようなものを作れるということがとても良い経験となりました。協力していただいた M には感謝です。(ほぼ彼が基本的な実装をやっていた。主は研究室帰りからやったので追いつくのに必死だった…)
何かわからないことがあった時に調べるということはとても大切だと思います。ネットの海を漁れば何かしらが出てきますが、答えにたどり着くために『調べ方』や『どこを見るか』はより大切だと思います。それでもうまくいかない場合は ChatGPT などに聞いてみるのも、これからの時代の新たな選択肢となってくるのではないでしょうか。
次回予告と宣伝
今回は番外編でした。コードが汚いのでまとまったらそのうち公開しようと思っています。続編はこちら↓
最後に
最後まで読んでいただきありがとうございました。最後に少し宣伝です。主のteftefが運営を行っているdiscordサーバーを載せます。このサーバーではMidjourneyやStble Diffusionのプロンプトを共有したり、研究したりしています。ぜひ参加して、お絵描きAIを探ってみてはいかがでしょう。(teftef)
↓↓もしよろしければこの記事と開発の支援お願いいたします!
この記事が気に入ったらサポートをしてみませんか?