
python:機械に売上予測をしてもらおう!

①データを準備する
下記のURLから3つファイルをDL。今回は、お弁当屋さんの売上を予測してみます。
・train -> 機械学習用
・test -> 機械テスト用
・sample -> 提出用

signateはkaggleのような国内のサイトです。
②データの中身をチェック
・各種ライブラリのインポート
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
from sklearn.linear_model import LinearRegression as LR #線形回帰モデル
%matplotlib inline
・データのチェック
train = pd.read_csv("C:/Users/user/Desktop/Lunchbox/train.csv")
test = pd.read_csv("C:/Users/user/Desktop/Lunchbox/test.csv")
sample = pd.read_csv("C:/Users/user/Desktop/Lunchbox/sample.csv", header=None)
train.head()
test.head()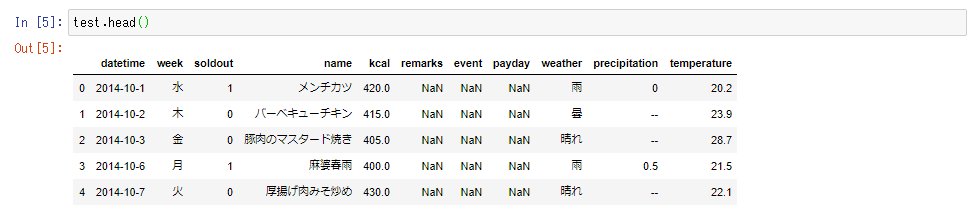
sample.head()
データの成形
とりあえず、"week"と"temperature"を使用して、予測するので、その項目にnullがないか、確認
train.isnull().sum()
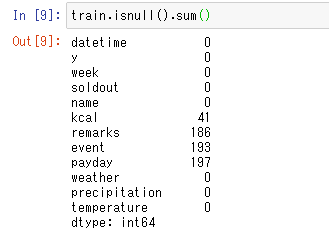
文字情報だけの"week"は使えないので、pandasのget_dummies関数を使って、one-hot表現、ダミー変数化する
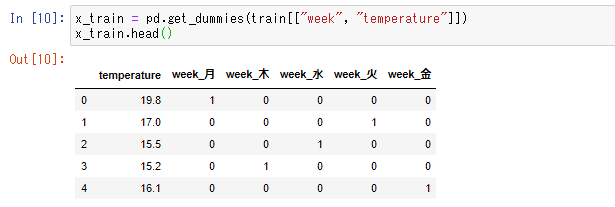
x_train = pd.get_dummies(train[["week", "temperature"]])
x_train.head()"week"に入っている文字を列に直し、その列に当てはまる場合は1、当てはまらない場合は0を入力するような形。
・目的変数の用意
y_train = train["y"]
モデルの作成
#線回帰モデルの定義
model = LR()
#説明変数と目的変数を設定し、学習
model.fit(x_train, y_train)
#傾きの確認
model.coef_
#切片の確認
model.intercept_モデルを使って予測
# 検証用データ
x_test = pd.get_dummies(test[['week', 'temperature']])
# 予測
pred = model.predict(x_test)
print(pred)
・サンプルファイルを編集し、アップロードして評価
sampleファイルの2行目を予測した売上数に置き換え。submitファイルとして保存。
sample[1] = pred
sample.to_csv("C:/Users/user/Desktop/Lunchbox/submit.csv", index=None, header=None)

精度評価は、正解と予測数値の誤差(絶対値)を二乗、平均し、平方根をとった平均二乗平方根誤差を使用され、0に近づければ近づくほど評価が良い。暫定評価40は結構悪いということ。
精度を良くするための試行錯誤
・trainファイルのyをグラフにしてみる
plt.plot(train["y"])
plt.show()
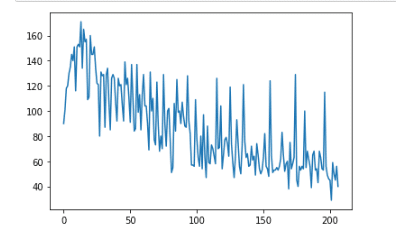
時間とともにy(売上)が減少しているのがわかる。
・年と月の列を作成する
# datetimeを分割して設定
train['year'] = train['datetime'].apply(lambda x : x.split('-')[0])
train['month'] = train['datetime'].apply(lambda x : x.split('-')[1])
test['year'] = test['datetime'].apply(lambda x : x.split('-')[0])
test['month'] = test['datetime'].apply(lambda x : x.split('-')[1])
# 新規で定義したカラムのデータ型はobject型になってしまうため、int型へ変換する
train['yaer'] = train['year'].astype(np.int)
train['month'] = train['month'].astype(np.int)
test['yaer'] = test['year'].astype(np.int)
test['month'] = test['month'].astype(np.int)

・実績と予測の差を取る
pred = model.predict(x_train)
train["pred"] = pred
train.head()

実績と予測の差データのGAPを作成して、GAP列を昇順でソート表示
train["GAP"] = train["y"] - train["pred"]
train.sort_values(by=['GAP'],ascending=True)

お楽しみメニューがある場合は、y(売上実績)が伸びていて、モデルで予測した数値と差があるのがなんとなくわかる。
・お楽しみメニューがある場合は、1、ない場合は0の列(remarks_in)を作成
関数を作成(lambdaで書く場合)
remarks_2 = lambda x: 1 if x == "お楽しみメニュー" else 0関数を作成(defで書く場合)
def remarks_2(x):
if x == "お楽しみメニュー":
return 1
else:
return 0
remarks_in列を作成
train['remarks_in'] = train['remarks'].apply(lambda x : remarks_2(x))
test['remarks_in'] = test['remarks'].apply(lambda x : remarks_2(x))
確認
train.sort_values(by=['remarks_in'],ascending=False)[:10]

精度が上がるか試してみよう
x_train = train[["year", "month", "remarks_in","temperature"]]
x_test = test[["year", "month", "remarks_in","temperature"]]
y_train = train["y"]
model = LR()
model.fit(x_train, y_train)
pred = model.predict(x_test)
sample[1] = pred
sample.to_csv("C:/Users/user/Desktop/Lunchbox/submit2.csv", index=None, header=None)

結構上がりました!
チュートリアル記事
過去記事
その他
回帰分析:回帰分析とは、ある変数xが与えられたとき、それと相関関係のあるyの値を説明・予測することです。
線回帰:y = a + bx ( y = 目的変数 / a = 切片 / b = 傾き / b = 説明変数 )
a切片:説明変数が最小の場合のYの値
b傾き:線の傾き
単回帰分析:説明変数が1つで分析する方法。
重回帰分析:説明変数が2つ以上で分析する方法。
lambda式:関数を名前を付けずに簡潔に宣言できる。
lambda 引数:処理内容
train['year'] = train['datetime'].apply(lambda x : x.split('-')[0])上記では、datetimeの情報を取り、その中で"-"を区切りにして、最初のほうをyearとして、データを作成するような式。引数として、設定されているxはappryメソッドにより、引き渡すことができる。

この記事が気に入ったらサポートをしてみませんか?