
相関関係を意識すると予測精度が上がる

ビッグデータとか、データマイニングといった言葉を日常的に耳にするようになって久しくなりました。既にもう新技術でもなんでもありません。理系に限らず文系のビジネスマンであっても統計の素養は欠かせない時代になっています。
たとえば「雨降りの日が増えると、交通渋滞の頻度も増す」のように、2つのデータのあいだに「一方が増えれば、他方も増える」といった大まかな傾向があるかどうかを調べなくてはいけないシーンは少なくないはずです。
そこに文系も理系も関係ありません。
ある傾向の度合いがある程度以上のとき、
2つのデータのあいだには「相関関係がある」ということができます。
……と間くと「"ある程度以上″ってどの程度?」と思う人もいるかもしれません。
(屁理屈ではなく、真剣にそう思える人は数学的に発想する素質があります)
ビジネスに統計を用いることが大きな注目を集めている昨今、データマイニングという言葉を問いたことのある人は多いと思います。
データマイニングとは、
「データ(data)から潜在的なニーズなどを掘り出す(mining)」
という意味ですが、そこから転じて
「膨大なデータを解析することで、
それまで明らかになっていなかった有益(かつ意外)な情報を引き出す」
といったニュアンスを含むことが多いようです。
世にデータマイニングの事例を最初に紹介したのは、1992年12月23日付「ウォールストリートジャーナル」掲載の「Super Computer Manage Holiday Stock」という記事だったといわれています。
記事の内容はこうです。
アメリカ中西部の小売ストア・チェーン Osco Drugs は、25店舗のキャッシュレジスターのデータを分析したところ、ある人が午後5時に紙おむつを買ったとすると、次にビールを半ダース買う可能性が大きいことを発見した。
この記事は「紙おむつと缶ビール」という意外な組み合があることがわかったということで大きな話題になり、今でもデータマイニングの有効性を示す例としてしばしば世界中で引用されています。
ちなみに、Osco Drugs では
「ジュースと咳止め薬」
「化粧品とグリーディングカード」
などの30の異なる組み合わせも検証したそうですが、
「ビールと紙おむつ」
ほどの相関は見つからなかったそうです。
だからといって「紙おむつが1パック売れると必ず缶ビールも半ダース売れる」というわけではないので、紙おむつの購入と缶ビールの購入のあいだに因果関係があるとはいえません。
しかし、この2つが無関係でないことがわかれば、
たとえば、
「子どものいる家庭では、日曜の午後に妻から
紙おむつの買い物を頼まれた夫がついでに缶ビールも買って帰るのではないか?」
とか、
「小さい子どもがいる家庭では(まだ)夫婦仲がよい場合が多く、
日用品を買いに来た妻が夫のためにビールも買って帰るケースが多いのだろう」
などと考察することができます(後者は多少うがった見方ですが)。また、紙おむつと缶ビールに相関関係があることから、これらを並べて陳列すればさらに売上があがることも期待できそうです。
ときどき相関関係と因果関係を混同している人がいますが、これらは似て非なるものですから注意が必要です。相関関係があるからといって、必ずしも因果関係があるとは限りません。逆に、因果関係があるときは必ず相関関係があります。

2つのデータのあいだに相関関係が成立するかどうかを客観的に判断するには、
「相関係数」(Correlation coefficient)
といわれる指標を使います。
相関係数の数学的な背景は決して易しいものではありませんが、相関係数の値を出すこと自体は私たちになじみの深い「Excel」を使えば簡単にできます。しかも、因果関係が成立するかどうかを見極める難しさに比べて相関係数の値を使って相関関係を検証することははるかに容易です。
ビジネスにおいては、相関関係が成立することさえわかれば十分ということが多いはず
……であれば、これを使わない手はありません。
たとえば、「最高気温とビールの売上」を題材にしてみましょう。
最高気温は、日本国内のビール売上に最も影響が最も大きいと思われる東京の(正確にいうと東京都千代田区大手町の)最高気温(日平均℃)を、またビールの売上は、ビール酒造組合の市場動向レポートから「国産の課税移出数量」(単位はKL)を使うと次のような表ができます。
最近では、四半期や半期しかデータを取っていないようなので、月単位でデータを取っていた2014年まで遡ってみると、

という表ができます。
このようなデータから、Excelを使って相関係数を求める手順は次のようになります。

①Excelにデータを入力する。
②適当なマスを選択して、ウィンドウ上部のツールバーの「数式」のタブをクリック。
③「関数の挿入」から、
→「その他の関数」
→「統計」
→「CORREL」
とすすむ。
④「CORREL」をクリックすると、「関数の引数」という小さなウィンドウが開く。
⑤そのなかの「配列1」と「配列2」に相関係数を計算したいデータを指定する。
今回は「配列1」には、「東京の最高気温」の訓個のデータを、
「配列2」には、「ビールの売上」の釧個のデータをそれぞれ選択。
⑥最後に「OK」をクリック。
以上のようにすると「0.413490225」という値が算出されます。
ざっと四捨五入して、「0.413」としましょう。
これが「最高気温とビールの売上」の相関係数です。
次に、この「0.413」という数値を評価していくわけですが、そのまえに「散布図」と呼ばれる図を見てみましょう。ありがたいことに散布図もExcelで簡単につくれます。
相関係数は散布図とセットにすると、より直感的に理解できます。
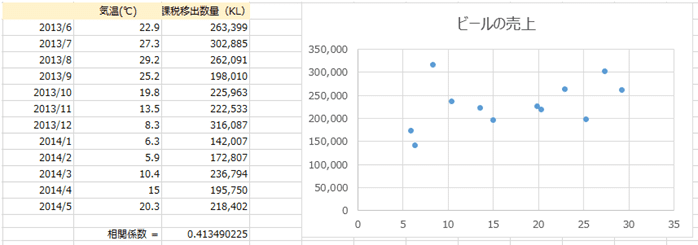
もしも、2つのデータ間に相関がある場合、散布図の点はある直線の近くに集まるという法則があります。
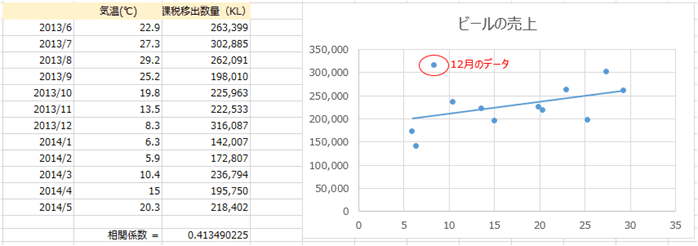
左の散布図では、楕円で囲んだ点以外は図内の直線近くに分布しています。
これを近似値線と言います。
散布図を見れば、相関があるかどうかのだいたいの感じはつかめますが、それはあくまで主観的かつ大雑把な印象なので、散布図は客観的な判断や詳細な比較には向いていません。
だからこそ、相関係数という数字が必要なのです。
じつは相関係数は、必ず「-1」と「1」のあいだの数をとることがわかっています。
一般に、相関係数の値によっての程度は次のように判断することができます。
相関係数が1に近い=正の相関がある
相関係数がOに近い=相関がない
相関係数が-1に近い=負の相関がある
「正の相関」というのは「一方が増えれば、他方も増える」ような相関で、「負の相関」というのは「一方が増えると、他方は減る」ような相関のことです。

先ほど計算した「0.413」という値は0と1のなかほどですが、相関の強弱は上図のように判断するので、「最高気温」と「ビールの売上」には中程度の正の相関があるといえます。
じつは、12月はクリスマスや正月のために流通が増えると言うのもあるでしょうが、なによりも忘年会シーズンのせいで一気に増えると言うことがわかっています。
もしも、この12月を除いて相関係数を確認してみると「0.743」という高い係数を出し、気温とビールに非常に強い結びつきがあると言うことがわかってきます。
中学・高校の頃であれば「数学」、大学生以降は「統計学」として学ぶ内容ですが、こうしたデータの相関関係を見ることができるようになってくると、
マーケティング
のみならずビジネスの判断や決断に根拠が伴い、強い意志につながったり、周囲の信頼を得られやすくなったりと様々なメリットを生み出すようになります。同時に、様々なデータの裏に潜む関係性についても明らかにできるようになり、主観的な直観や思い込みと言ったヒューマンエラーのもとになる考え方も減っていきます。
なにより思い込みや好き嫌いなどの感情の入る余地が少なくなります。定量的に評価できるものであれば、テストの品質や人材の評価などにも使えることでしょう。
たとえば私は多くのトラブルプロジェクトの内容から、こと「マネジメント」スキルに起因する問題点を予測するために、こうした相関関係を意識したYES-NOチャートを作ってなんとなくプロジェクトマネージャーやリーダー、あるいはそれらを管理する上司などとの会話・日頃のしぐさなどを観察することがあります。

相関関係を確認し、状況を把握、予測し、あらかじめ問題が起きないように対策を講じる際にもとても役立ちます。
いただいたサポートは、全額本noteへの執筆…記載活動、およびそのための情報収集活動に使わせていただきます。