
Pythonでヒストグラム(3)

(1)ヒストグラムをきれいに描く
前回の続きです。ヒストグラムは最終回です。
今回は、前回の最後に作成したパレート図に、頻度を打ち込む方法をアーカイブします。案外、この方法は調べても出てこなかったりするので、便利では?と思います。Excelだと簡単にできるのに、Pythonだと若干めんどくさい処理です。
あと、ついでに正規性の検定をして、その結果をグラフ中に打ち込んでいます。なんか盛りだくさんになってしまいました。
(2)使うデータ
これまでと同じく、irisデータを使います。
(3)実際に計算してみる
今回のコードは下記のとおりです。コメントをたくさん書いているので、だいぶ長いコードになっていますが、適宜修正して活用してください。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import scipy.stats as stats
df = pd.read_csv('iris.csv')
print(df)
ax = df.describe()
print(ax)
#-----------------------------------------------------------------------------
#binsなどの計算に必要な変数を指定します。
start = 4
end = 8
interval = 0.5
bins_count = ((end - start)*2 + 1)
#binsを指定します。
bins = np.linspace(start, end, bins_count)
#グリッド線をつけます。
plt.grid(True, linestyle='dotted', linewidth=1)
#グラフのタイトルをつけます。
plt.title('ヒストグラム')
#x軸、y軸の名前を決めます。
plt.xlabel('がく片の長さ')
plt.ylabel('頻度')
#横軸の範囲を指定します。
plt.xticks(np.arange(start, end+interval, interval))
plt.xlim(start, end)
#縦軸の範囲を指定します。
plt.yticks(np.arange(0, 41, 5))
plt.ylim(0, 40)
#グラフを出力します。
n, bins, patches = plt.hist(df['sepal.length'], bins=bins, rwidth=0.9,align='mid')
#-----------------------------------------------------------------------------
#-----------------------------------------------------------------------------
# 正規性の検定(シャピロ・ウィルク検定)
#-----------------------------------------------------------------------------
shapiro = stats.shapiro(df['sepal.length'])
if shapiro[1] < 0.05:
a = 'p=' + str(round(shapiro[1],4)) + '(正規分布でない)'
elif shapiro[1] > 0.05:
a = 'p=' + str(round(shapiro[1],4)) + '(正規分布である)'
#-----------------------------------------------------------------------------
#-----------------------------------------------------------------------------
# 正規性の検定結果をグラフにプロット
#-----------------------------------------------------------------------------
plt.text(start+0.1, 38, '正規性の検定(シャピロ・ウィルク検定)' + str(a), va='bottom')
#-----------------------------------------------------------------------------
#-----------------------------------------------------------------------------
# ヒストグラムの頻度を打ち込む
#-----------------------------------------------------------------------------
xs = (bins[:-1] + bins[1:])/2
ys = n
for x, y in zip(xs, ys):
plt.text(x, y+0.5, "%d" % y, horizontalalignment="center")
#-----------------------------------------------------------------------------
#-----------------------------------------------------------------------------
# 第2軸のプロット
ax2 = plt.twinx()
# 第2軸用値の算出
y2 = np.add.accumulate(n) / n.sum()
x2 = np.convolve(bins, np.ones(2) / 2, mode="same")[1:]
#折れ線グラフとしてプロットします。
plt.plot(x2, y2, ls='--', color='k', marker='o')
#上述のとおりです。
plt.yticks(np.arange(0, 1.1, 0.2))
plt.ylim(0, 1)#軸の表示範囲
ax2.set(ylabel='累積相対度数')
#-----------------------------------------------------------------------------
plt.show()出来上がりのグラフはこちらです。
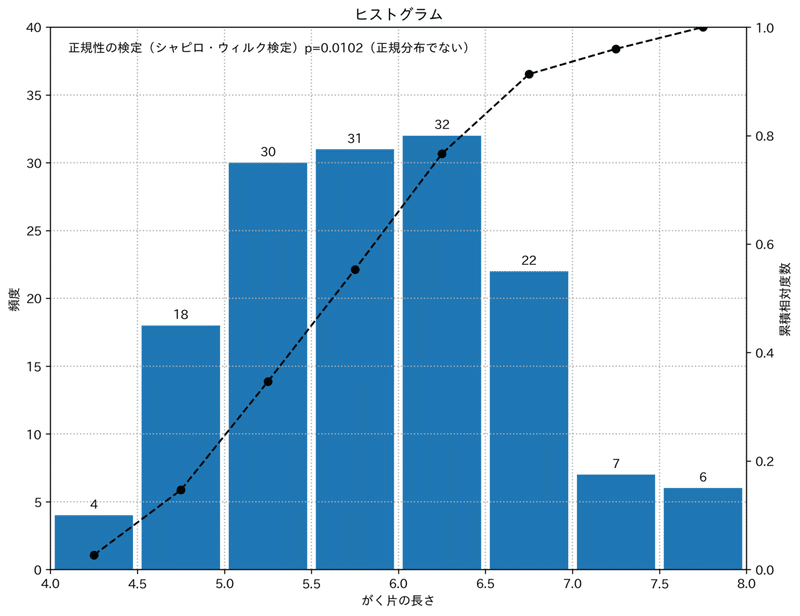
コードの中盤から、新しい処理です。
#-----------------------------------------------------------------------------
# 正規性の検定(シャピロ・ウィルク検定)
#-----------------------------------------------------------------------------
shapiro = stats.shapiro(df['sepal.length'])
if shapiro[1] < 0.05:
a = 'p=' + str(round(shapiro[1],4)) + '(正規分布でない)'
elif shapiro[1] > 0.05:
a = 'p=' + str(round(shapiro[1],4)) + '(正規分布である)'
#----------------------------------------------------------------------------- コメントで記載しているとおりですが、正規性の検定を行なっています。ここではシャピロ・ウィルク検定で計算しています。シャピロ・ウィルク検定の帰無仮説は、標本が正規分布に従う母集団からサンプリングされたものである、なので、p>0.05となれば正規分布していることになります。そのため、シャピロ・ウィルク検定の結果から正規分布かそうでないかを文字として指定しておきます。これは、このあとの処理で使い、グラフに打ち込みます。なおシャピロ・ウィルク検定については、こちらを参照ください。
また、この検定を行なうために、事前にScipyをインポートします。
import scipy.stats as statsこちらは数値解析を行なうライブラリで、よく使います。注意点として、Scipyで計算する際に、空白行があるとエラーになります。df.dropna()とかで処理することもできます。
plt.text(start+0.1, 38, '正規性の検定(シャピロ・ウィルク検定)' + str(a), va='bottom')先ほどif文で指定した正規性の検定の結果をグラフに打ち込んでいます。plt.text()で、グラフの任意の場所に文字を打ち込むことができます。詳しくはこちらをご覧ください。
xs = (bins[:-1] + bins[1:])/2
ys = n
for x, y in zip(xs, ys):
plt.text(x, y+0.5, "%d" % y, horizontalalignment="center") 前回の記事で、plt.hist()がx軸、y軸の値を内部に有していることをお伝えしました。ここでもその値を用いて、ヒストグラムのビンの上に頻度を打ち込んでいます。海外の記事を参考にした記憶がありますが、どこか記録がありませんでした。
xsはx軸の位置を指定しています。平均を取って、ビンの中央になるように調整しています。ysはy軸の位置を指定しています。for文はビン毎に頻度を打ち込む処理になります。
以上が前回からの追加部分になります。コードが長くなってしまい、またコメントをたくさん書いているので読みずらいですが、Python初心者はこれぐらいコメントを書いておいた方が良いと思います。あとで読み返した時に、何の処理かを把握できるようになります。
これで、論文に使えるグラフを相当きれいに作成することができました。さらにこだわってグラフを作成する方法はどこかで紹介したいと思いますが、はまると永遠なので、適度にアーカイブします。
(4)まとめ
ヒストグラムの最終回です。コードも解説もごちゃごちゃしていますが、10分くらいで記事を書いているので、ご容赦ください。
(5)参考
■matplotlib
https://matplotlib.org/
■NumPy
https://numpy.org/doc/stable/contents.html
■Scipy
https://www.scipy.org/
■シャピロ・ウィルク検定
https://data-science.gr.jp/implementation/ist_r_shapiro_wilk_test.html