
Pythonでヒストグラム(2)

(1)ヒストグラムをきれいに描く
前回の続きです。
(2)使うデータ
これまでと同じく、irisデータを使います。
(3)実際に計算してみる
今回のコードは下記のとおりです。前半は前回と同じです。追加した部分を紹介します。
その前に、私は毎回print(df)やdf.describeでデータの確認をしています。これは癖をつけることをおすすめします。どのデータを使っているのか?古いデータを指定していないか?といったミスを減らすことにつながります。
では、今回のコードの説明を始めます。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
df = pd.read_csv('iris.csv')
print(df)
ax = df.describe()
print(ax)
#binsなどの計算に必要な変数を指定します。
start = 4
end = 8
interval = 0.5
bins_count = ((end - start)*2 + 1)
#binsを指定します。
bins = np.linspace(start, end, bins_count)
#グリッド線をつけます。
plt.grid(True, linestyle='dotted', linewidth=1)
#グラフのタイトルをつけます。
plt.title('Histgram')
#x軸、y軸の名前を決めます。
plt.xlabel('sepal.length')
plt.ylabel('count')
#横軸の範囲を指定します。
plt.xticks(np.arange(start, end+interval, interval))
plt.xlim(start, end)
#縦軸の範囲を指定します。
plt.yticks(np.arange(0, 41, 5))
plt.ylim(0, 40)
#グラフを出力します。
plt.hist(df['sepal.length'], bins=bins, rwidth=0.9, align='mid')
plt.show()出来上がりのグラフはこちらです。
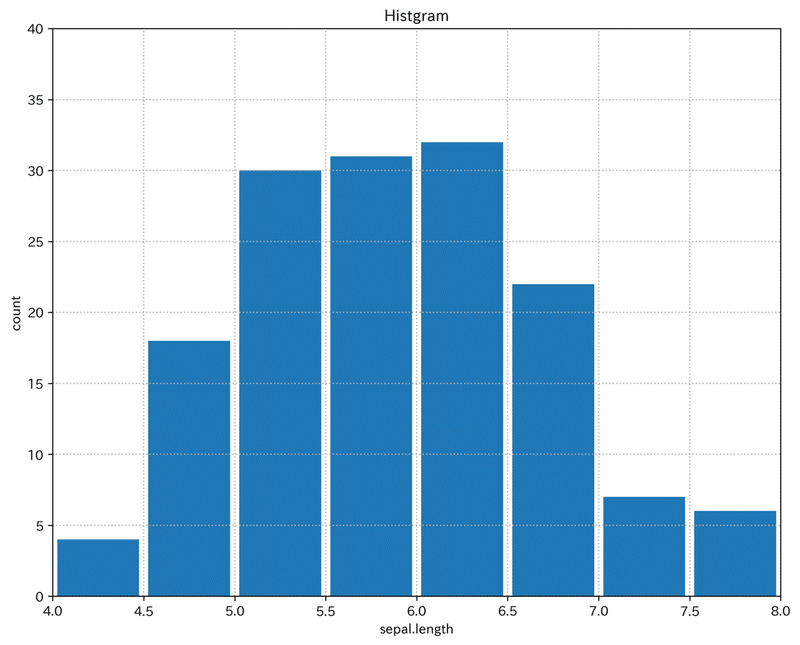
■15~21行目
#グリッド線をつけます。
plt.grid(True, linestyle='dotted', linewidth=1)
#グラフのタイトルをつけます。
plt.title('Histgram')
#x軸、y軸の名前を決めます。
plt.xlabel('sepal.length')
plt.ylabel('count')コメントで記載しているとおりですが、それぞれ、グリッド線、タイトル、軸名を描く処理です。タイトルや軸名は日本語でもOKです。
#グラフのタイトルをつけます。
plt.title('ヒストグラム')
#x軸、y軸の名前を決めます。
plt.xlabel('がく片の長さ')
plt.ylabel('頻度')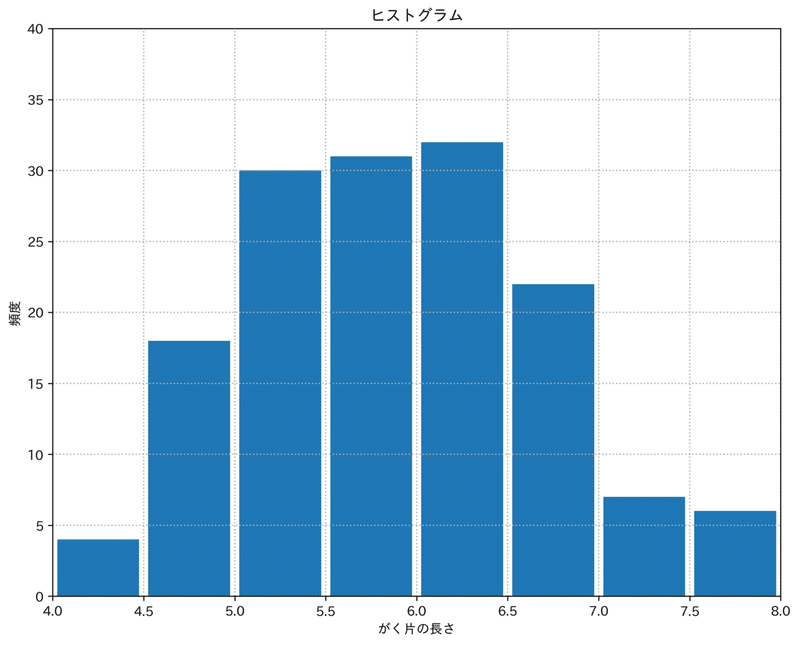
他の部分はほとんど変わりません。次に、ヒストグラムに累積相対度数を追加する方法をアーカイブします。
(4)累積相対度数を打ち込む
コードはこちらです。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
df = pd.read_csv('iris.csv')
print(df)
ax = df.describe()
print(ax)
#binsなどの計算に必要な変数を指定します。
start = 4
end = 8
interval = 0.5
bins_count = ((end - start)*2 + 1)
#binsを指定します。
bins = np.linspace(start, end, bins_count)
#グリッド線をつけます。
plt.grid(True, linestyle='dotted', linewidth=1)
#グラフのタイトルをつけます。
plt.title('ヒストグラム')
#x軸、y軸の名前を決めます。
plt.xlabel('がく片の長さ')
plt.ylabel('頻度')
#横軸の範囲を指定します。
plt.xticks(np.arange(start, end+interval, interval))
plt.xlim(start, end)
#縦軸の範囲を指定します。
plt.yticks(np.arange(0, 41, 5))
plt.ylim(0, 40)
#ここからが若干違う部分です。-------------------------------------------------------
#グラフを出力します。
n, bins, patches = plt.hist(df['sepal.length'], bins=bins, rwidth=0.9,align='mid')
# 第2軸用値の算出
y2 = np.add.accumulate(n) / n.sum()
x2 = np.convolve(bins, np.ones(2) / 2, mode="same")[1:]
# 第2軸のプロット
ax2 = plt.twinx()
#折れ線グラフとしてプロットします。
plt.plot(x2, y2, ls='--', color='k', marker='o')
#上述のとおりです。
plt.yticks(np.arange(0, 1.1, 0.2))
plt.ylim(0, 1)#軸の表示範囲
ax2.set(ylabel='累積相対度数')
plt.show()また図は下記のとおりです。
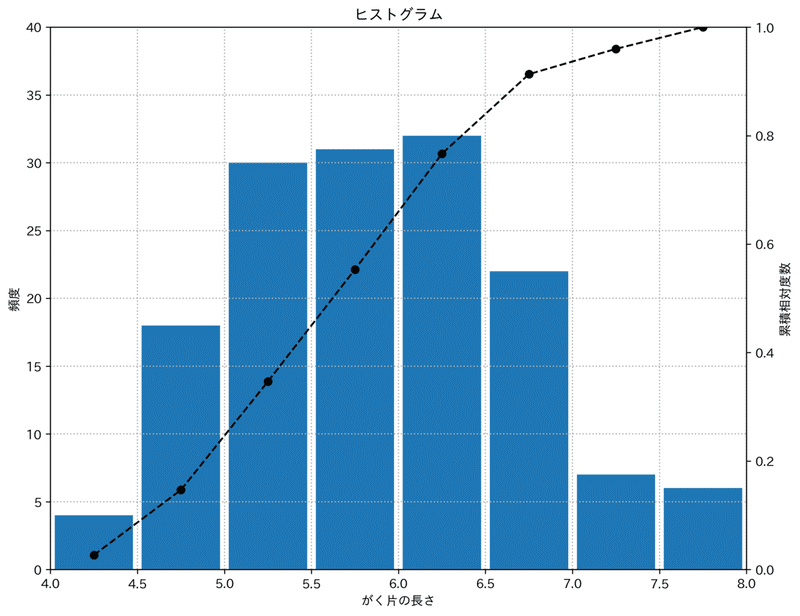
■修正30行目
n, bins, patches = plt.hist(df['sepal.length'], bins=bins, rwidth=0.9, align='mid')plt.hist()では、x軸、y軸の値をそれぞれを抽出することができます。この数字を使って、累積相対度数を計算し、折れ線グラフで打ち込むことができます。
■修正31~33行目
# 第2軸用値の算出
y2 = np.add.accumulate(n) / n.sum()
x2 = np.convolve(bins, np.ones(2) / 2, mode="same")[1:]ここを説明し始めると、若干長くなるので、NumPyの解説をご覧ください。やっていることは、割合を計算しリストの作成になります(若干正しくはないですが…)。
■修正34~37行目
# 第2軸のプロット
ax2 = plt.twinx()
#折れ線グラフとしてプロットします。
plt.plot(x2, y2, ls='--', color='k', marker='o') plt.twinx()で、ここ以降は第2軸の処理であることを指定します。
plt.plot()は新しいコードです。これまではヒストグラムしか説明してきませんでしたが、matplotlibでは、あらゆるグラフを描くことができます。今回使用するplt.plot()では、折れ線グラフを打ち込めます。le='--'は、折れ線グラフを点線で描くことを、marker='o'は、各ポイントを●で描く指定です。
■修正41行目
ax2.set(ylabel='累積相対度数')第2軸のラベル名を指定します。ちなみに、axという変数を用いていますが、matplotlibを本気で使い始めると、axという変数をよく使うことになります。ここは別の機会に説明したいと思います。
(5)まとめ
長くなったので、今回はここまでです。次回でヒストグラムは最後にしようかな。
今回、最後に作成した図はパレート図と呼ばれます。データの特徴を把握するうえで、大変わかりやすいグラフです。
まだ、統計解析の第1歩が続いていますが、結局、この辺りの基本が重要だと思います。高度な統計解析をするまえに、まずは基本データを整理し、特徴を明らかにしたうえで、次のステップに行くべきだと思います。p値や相関係数を出さないと何も語れない、と勘違いする人が結構いますが、基本データの整理でも語れることはたくさんあります。地味ですが、気長に分析をしていきたいと思います。
(6)参考
■matplotlib
https://matplotlib.org/