
最速・非破壊ePub自炊 〜『坂本龍一の音楽』をリフロー型電子書籍に変換したい

前回記事(PDF対応版)を書いたのが、ちょうど3年前。
あれ以来、世界は激変しつつも、技術分野はごく地味にもろもろが進化してて、さらに快適&高度&高速な自炊が可能な世界になっていたので、アップデートの記事です。
今回は、PDFではなく、さらに先の「ePub」(リフロー型電子書籍)化をめざしました。
一部、エンジニア向けの部分もありますが、参考になれば、と思います。
<なぜそんなに非破壊自炊?>
そもそも、ぼくが非破壊自炊に固執しているのは、『坂本龍一の音楽』(山下邦彦著、2008年)という本があるからなのです。
この本は、とにかくデカくて(40x30x15cm!)、重くて(3.5kg!)、長い!(1055ページ!)(値段もそこそこ、いや安い!)
これが、音楽理論そして坂本龍一氏を愛する者にとっては、一生の宝物なのです。「ああ、もっとラクに気軽にこの本が読めれば、ちゃんと理解できるに違いない」と考えて、はや15年。
前回記事の時点では、雑にスキャンしてPDF化まで、しかできていませんでしたが、今回、新たに見つけたスキャナーアプリが秀逸だったため、それを使ったら、なんだかあれよあれよとePub化できてしまったので、手順を(AS-ISで)シェアします。

作業内容
作業の流れ
今回の作業の流れはこのようになります:
本をスマホでスキャン
画像をクロップしてPDFに
PDFをOCR(文字認識)
OCR結果をテキストファイル化
テキストファイルを整形し、Markdownフォーマット化
MarkdownをePubに変換
使った環境
これとまったく同じ環境でなくても、いろいろ工夫すればできると思いますので、各手順をひとつの「ヒント」として使っていただければ幸いです。
Mac (パワーはあまり必要ないので古い機種でも)
iPhone (これも、アプリが使えればどの機種でも)
Python (必須ではないです。ちょっと楽ちんにやるなら)
Markdown (このファイル形式を通して、整形します)
VisualStudio Code (Markdownをプレビュー・変換など)
VSCode用の Markdown Preview Enhanced 拡張機能
では、実際の手順です。
1. 本をスマホでスキャン
今回、新たに見つけて使ったのは下記のiOSアプリ:
vFlat Scan - PDF Scanner
このアプリは、マジですごい。 本を開いてスキャンすると、
ページの認識が超高速
ページのゆがみ・たわみも認識し補正
ページを押さえる指も画像から自動除去
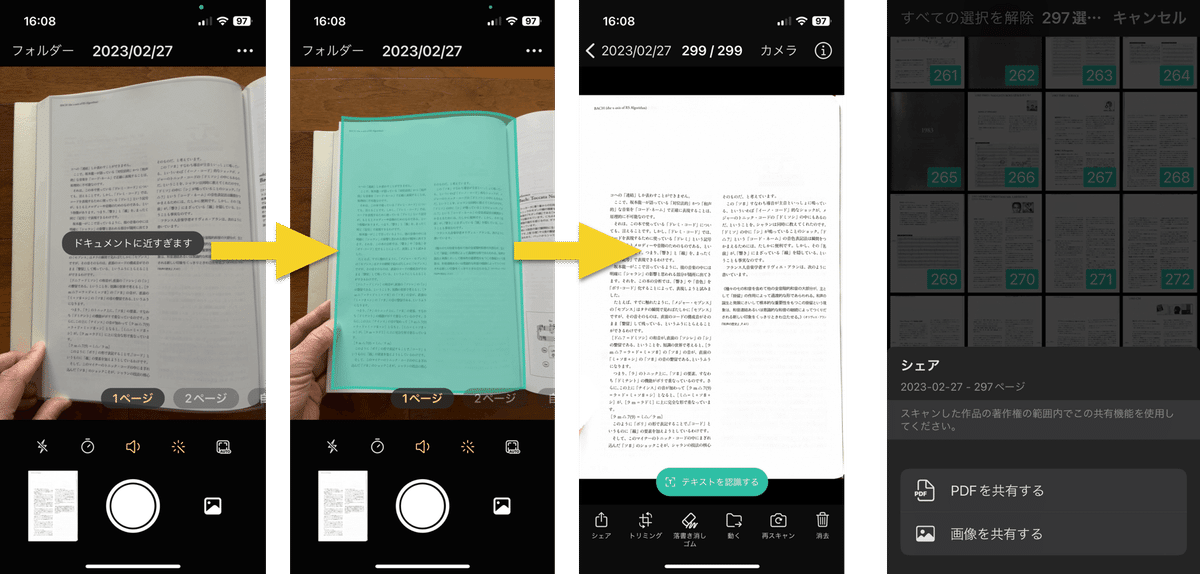
とにかく、とんでもなく高速にスキャン処理が終了します。
スキャンしたファイルを、Macに持ってきて、続く作業を開始です。
2. 画像をクロップしてPDFに
使い方によっては(通常の文字だけの本の場合等)、スキャンしたままのページをそのまま、でもいいかもしれません。
ただ、僕の場合は、対象の本に図版がたくさんあって、段組も不規則な本だったので、OCRが必要な部分だけを手作業でクロッピングすることにしました。
画像編集ソフトはなんでもいいですが、僕は「Seashore」がお気に入りです。
Seashore
このアプリで、手順1で保存した画像を開いて、

文字のある場所を選択してコピー、

コピーした画像を新しいファイルにして、別名で保存、
すればいいんですが・・・ これを何百枚もやるのは、さすがにめんどくさい!!
楽にする方法はいろいろあるでしょうが、今回小さいPythonスクリプトを書きました。(使い捨てなので、ロクなコードじゃないです)
# このコードを走らせておいて、画像編集アプリで画像の一部をコピーすると
# 3秒間隔で新しく入ってくるクリップボードの内容を、SAVE_FOLDERの中に
# 001から連番で保存します
import os
import time
from PIL import ImageGrab, Image
SAVE_FOLDER = "./to_save"
def save_clipboard_image(clipboard_image):
# ファイルネームをファイル数に応じて連番で増やしていく
files_lst = os.listdir(SAVE_FOLDER)
file_name = os.path.join(SAVE_FOLDER, f"{str(len(files_lst)+1).zfill(3)}.jpg")
# clioboard_imageがImage.Image型の場合は保存する
if isinstance(clipboard_image, Image.Image):
clipboard_image.save(file_name, optimize=True, quality=20)
print("saved to {}".format(file_name))
else:
print("no image")
last_image = None
while True:
time.sleep(3) # 無駄に負荷をかけないため
new_image = ImageGrab.grabclipboard()
if last_image != new_image:
last_image = new_image
save_clipboard_image(new_image)これやって保存したクロップ済みの画像をまとめて、PDFを作ります。
Macだと、Finderから画像を全部選択して、「クイックアクション」->「PDFを作成」で簡単です。

3. PDFをOCR(文字認識)
手順2で作ったPDFを、Adobe Acrobat (OCRをするので、Readerではダメ) で開きます。
OCRできればなんのソフトでも良いですし、Acrobatを使う場合も、有料なので、試用期間に使い倒すとか、1ヶ月の間にやりきって解約、など工夫してください。(なので、OCRする手順は省略します。)
4. OCR結果をテキストファイル化
上記でOCRを施したPDFからテキストを抜き出します。
Acrobatでそのままでもいいですが、僕の場合は、Mac標準のプレビューアプリでPDFを開き、「編集」->「すべてを選択」を実行して、

コピー、テキストエディターにペーストする方が、改行位置など精度がよかったです。

そして、この時点である程度、テキストファイルを整形します。
手作業でやったらちくちく時間がかかってしまうので、これもちょっと楽にするために、また小さいPythonスクリプトを書きました。(これもロクなコードじゃないです。しかもこの本限定の経験則です。)
with open('./in.md', 'r') as inf:
with open('./out.md', 'w') as outf:
lastline = ''
while True:
newline = inf.readline()
if newline == '':
break
if len(lastline) > 0:
if lastline[0] == '《': # 行頭が「《」の場合、引用文マークをつける
outf.write('\n\n> ')
elif len(lastline) > 5 and len(lastline) < 25 and lastline[-2] != '。' and lastline[-2] != ')' and '(' not in lastline: # 短めの行で「。」で終わらない場合、小見出しマークをつける
outf.write('\n\n## ')
# 不要な改行を削除する
if (len(lastline) > 25) and (lastline[-2] not in ['。', ')', ')', '。']):
if len(newline) > 25 or (len(newline)>2 and newline[-2] in ['。', ')']):
lastline = lastline.rstrip('\n')
outf.write(lastline)
if len(lastline)>2 and lastline[0]!='《' and lastline[-2]==')':
outf.write('\n') # 改行を捕捉する
lastline = newline
len(lastline) = len(newline)
outf.write(lastline)これをやって、おおまかに整形したら、必要に応じて手作業でちくちく整形を加えて、テキストでは作業終わります。
5. テキストファイルを整形、Markdown化
Markdownは、テキストファイルにいろいろな記号を入れて、かんたんに見出しなどの整形を行える仕組みです。とはいえ、今回僕が使ったのは、
見出しにしたい行の先頭に「# 」や「## 」を入れる。
引用にしたい行の先頭に「> 」を入れる。
画像を挿入したい部分に「」のようなパスを入れる。
くらいで、たいしたことはしていません。なのに、これをやるだけで

というただのテキストが、VSCodeで、Markdown Preview Enhanced 拡張機能を使うと、こういうふうにプレビューできます。内容を確認しながらOCRのミスなど修正しましょう:

6. MarkdownをePubに変換
ここまできたら、pandocでePubに変換します。
細かいことを言わなければそれだけでePubに。
Pandoc
pandoc MusicOfSakamoto.md -o MusicOfSakamoto.epub --epub-cover-image cover.jpg
いろいろしちめんどくさいことやってますが、ここまでやってでも
本自体をモノとしてとっておきたい
ここまでしてもちゃんと読みたい(できれば肌身離さず持っておきたい)
そんな本があって、幸せだとも思います。
そんな本があるあなたに。 Enjoy!!
この記事が気に入ったらサポートをしてみませんか?