
[iOS 17] 音声認識におけるカスタム言語モデルのサポート #WWDC23

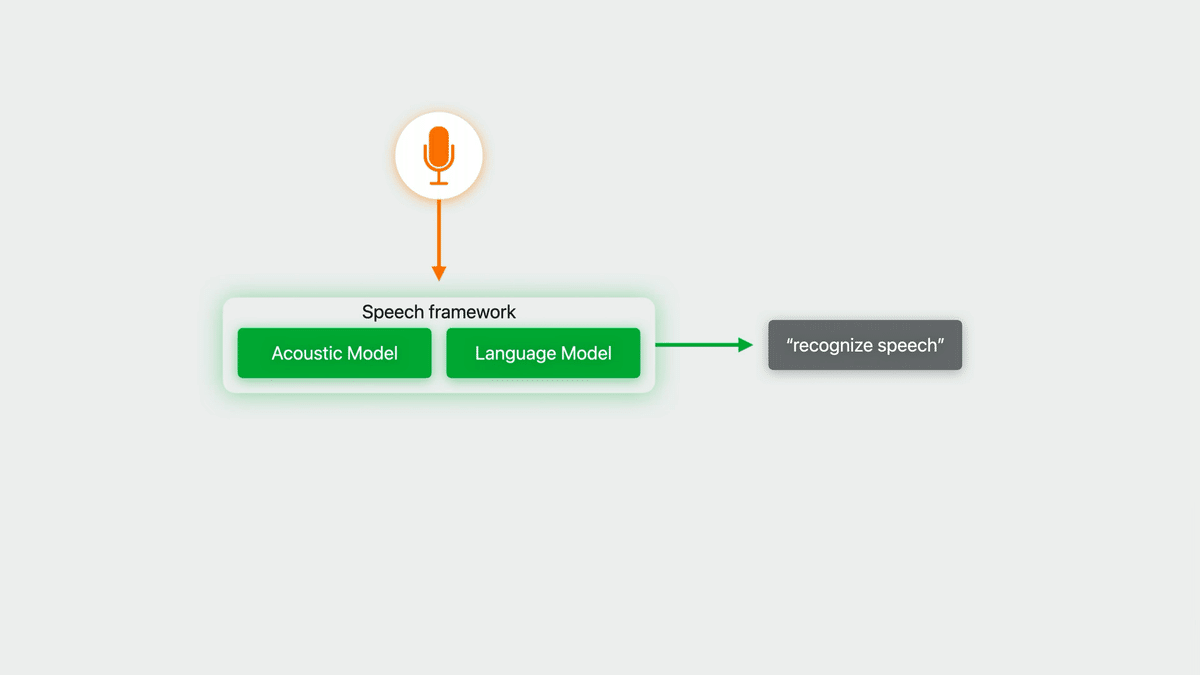
iOSには標準の音声認識フレームワークとして、Speech フレームワークというものが用意されている。日本語もサポートしており、オンデバイスでも動作可能。iOS 10の頃から使える。
が、最近だとOpenAIのWhisperもCore ML版が出て、iOSアプリで音声認識を使うなら、(少なくとも書き起こし用途なら)Whisperの方がいいかな…と思っていた。
音声認識モデルのwhisper.cppがつい最近Core MLサポートしたようなので手元のM1 MBPで動かしてみたところ、実行速度はなんと本家Whisperモデルの約70倍...!
— Shuichi Tsutsumi (@shu223) May 3, 2023
標準フレームワークのSpeechでは実時間ぐらいかかってたので、めちゃくちゃ画期的です。もちろん日本語もサポート、Core…
しかしWWDC23のセッション「Customize on-device speech recognition」を見ると、かなり魅力的なアップデートがアナウンスされていた。
Speechフレームワークにおいてカスタム言語モデルの利用が可能になった、というもの。本記事はこれについて書いていく。
なお、音声認識における「音響モデル」「言語モデル」といったところの解説はわかりやすい記事が山程あると思うので本記事では割愛する。
以下、画像や引用表記は基本的に "Customize on-device speech recognition" セッションからの引用。
これまでの問題
Speechフレームワークに言語モデルもカプセル化されており、カスタマイズできなかった。
セッション内では、チェスアプリを例に取り、

相手が「クイーンズ・ギャンビット」という手を打ってきて、それに対して「アルビンのカウンターギャンビット」という手を打つべく、
"Play the Albin counter gambit. "
と音声入力すると(playにはチェスの手を打つという意味もあるらしい)、音声認識エンジンが「アルバムを再生してください」という音楽リクエストとして誤認識する、ということを言語モデルが固定であることによる問題ケースとして挙げていた。

この問題はめちゃくちゃわかる。SpeechであれWhisperであれ、「この会話の中ではそんな単語絶対に言わないんだけどな…」という認識結果が優先されることはしょっちゅうある。
(なお、SFSpeechRecognitionRequest には従来から contextualStrings というプロパティがあり、システムの語彙にないフレーズを追加する機能はあったが、何度か使ってみたことはあるがそれほどの効き目はなかった)
言語モデルのカスタマイズ
冒頭でも述べたとおり、iOS 17からは SFSpeechRecognizer の言語モデルをアプリケーションに合わせてカスタマイズし、精度を向上させることが可能になった。
言語モデルのカスタマイズの一連の流れについて、セッションでは以下のように解説されている:
To get started with language model customization, first create a collection of training data.
(言語モデルのカスタマイズを始めるには、まず、トレーニングデータのコレクションを作成します。)
You can do this during your development process.
(これは、開発プロセス中に行うことができます。)
Then, in your app, you'll prepare the data, configure a recognition request, and then run it.
(次に、アプリで、データを準備し、認識要求を設定し、そして実行します。)

Data generation
トレーニングデータの収集について。
ここから先は

#WWDC23 の勉強メモ
WWDC 2023やiOS 17についてセッションやサンプルを見つつ勉強したことを記事にしていくマガジンです。また昨年キャッチアップをお休…
最後まで読んでいただきありがとうございます!もし参考になる部分があれば、スキを押していただけると励みになります。 Twitterもフォローしていただけたら嬉しいです。 https://twitter.com/shu223/