
Qスターとは何か?可能性空間の効果的な検索がクリエイティビティをもたらす

このThe AI GRIDの動画が秀逸だったので、背景から紹介する記事です。
背景
Extremely concerning!https://t.co/Ru2FU2tOFG
— Elon Musk (@elonmusk) November 23, 2023
イーロン・マスクが数日前に「非常に懸念!」と懸念砲をOpenAIにむけて放っていたので、なんじゃ?と思って見てみたら、例の取締役会に解任されてマイクロソフトに移籍するはずだったCEOのサム・アルトマンの話で、どこらへんが懸念材料なのか掴みかねていたところ…
Q*Anon https://t.co/BaosFs4diz
— Elon Musk (@elonmusk) November 23, 2023
一時間後に自分のツイートを引用しQ*Anonとだけヒント。
で、さっきのロイター通信の記事をちゃんと見てみると

QスターというArtificial general intelligenceつまり汎用人工知能でブレイクスルーがあったとOpenAIが考えているらしいのです。
チャットGPTで世間を賑わしているOpenAIなので、彼らが興奮しているということはチャットGPTの限界を超えた可能性が高いです。記事内のOpenAI社員からのリークによると小学校の数学の問題程度ならば、問題を読んで回答することが出来ると。もうちょっと進歩させれば人間の仕事を奪うことになります。そのために遺憾砲が炸裂したのでしょう。
追記)
更に言うと、未確認情報の社員の内部告発ではQUALIAは最高レベルの暗号を破るらしい。BTCも政府の機密情報ですら危ないし、メタ学習能力がすごいらしく人間を超えるのは時間の問題なのかもしれません。でも未確認情報です。ロイター通信も手紙の存在は報道してますが、確認できていません。
The AI GRIDの続報で、真偽不明のOpenAIの内部告白について議論している。
— ShironoY しろの Ph.D 英検4級 (@shironoy7) November 27, 2023
これが本当ならばQUALIAと呼ばれるOpenAIの内部プロジェクトは
・QUALIAはメタ学習で自分の思考について学習し
・学習内容を別のタスクに応用できる
・AES-192、MD5など最高レベルの暗号を破るhttps://t.co/80kp3C0K0p pic.twitter.com/UgHHAvJc28
因みにQ*とかいてQスターです。アスタリスクともいうこの*ですが、英語でアスタリスクとはまず言いません。普通はスターです。あとは#もシャープでは絶対に通じないと思う。正解はパウンドかハッシュタグのハッシュ。
Qスターアルゴリズムとは?
Qスターがなにかは正式に発表されるまで想像するしかないです。しかし、名前からだいぶ推測できる部分もあり、機械学習に詳しい方ならQ-LearningとA* searchを組み合わせた感じ?とピンとくるでしょう。
Q-Learning
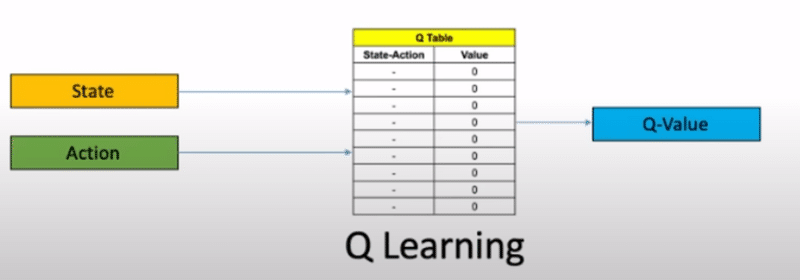
まず、Q-Learningというのは強化学習の一種で、強化学習とは適当に行動する個体が偶然でも好ましい行動したら報酬を与えることで、個体は徐々に報酬がよりもらえる行動を選ぶようになるみたいな感じです。犬にお手を教えるようなイメージです。

よくあるのはゴールまでの経路を考えるようなタスクで、途中の障害物を避けたり、報酬を取りながら最短ルートでゴールさせたいみたいな課題でつかわれます。右の表(Table)がロボットの行動の選択肢とそれに対応する現時点でロボットが考える評価値の関係を示すものでQ Tableとか言われます。
AIを最適化するのに予め訓練データを人間が一生懸命作るよりも、実世界に放って現実から学べるなら楽ちんですし、現実世界にあるデータ(ウィキペディアの全文テキストなど)を使ってコンピュータは繰り返しを飽きずにできるので人間には効率悪い学習法でも、コンピュータの中でシミュレートして何億回でも繰り返すと、AIがどんどんと上達しちゃって人間を追い越すかもしれないわけですな。それで将棋とか囲碁でも人間はAIに敵わなくなってしまったわけです。
人間も夜寝ている間に夢を見てAIがビデオゲームをプレイするように現実世界のシミュレーションをしてQ Tableをアップデートしていると思われます。
AIがゲームを攻略する基本技術がDeep Q Network
Q Tableをディープラーニングでもって推定しようとするとDQNになります。
Deep Q-Network(略称:DQN[1])とは、Googleの子会社ディープマインドが開発した数理モデルである。深層強化学習アルゴリズムを利用したもので、このモデルで学習したエージェントは、一部の電子ゲームにおいて人間以上のスコアを獲得できている[1][2]。
Deep Q NetworkはDQNと略されますが、
DQN(ドキュン)とは、日本語の文脈で「粗暴」「非常識」「軽率」「反社会的」「低脳」な者、またはそのように見える風貌の者へ使われるインターネットスラング・蔑称の一つ
こちらのDQNとは全く違うものですのでご了承下さい。
A* search

これも似たようなもので、迷路の最短ルートを計算するときなんかに使われるアルゴリズム(計算方法)で、ゲーム制作とかすると敵とかをA地点からB地点まで可能で最短ルートな経路を計算する必要とかよくあるのでよく使われます。これは決まった計算方法なので学習とか必要ないです。

迷路に限らずグラフ理論で問題を表現できちゃえば使えるので、迷路の最短ルートだけではなくより一般的な課題でも最適解に近い答えを見つけることができるのが特徴です。
つまり、今時に汎用性の高い知性を作ろうと思ったらA* searchとDQNを組み合わせてメッチャ学習させたらよくね?となり、じゃあこの2つを組み合わせたものがQ*なのか?と名前から推測することができます。
チャットGPTの限界を超える方法とクリエイティビティ
しかし、A start searchがなぜQ-Learningを改善する鍵となるのでしょうか。

ハサビスに顔が似てるけど違う人。
だれ?
グーグル傘下のDeepMindの誰々さんがいうには、
超意訳
チャットGPTとかの大規模言語モデルは実際のデータにあるパターンを真似ているに過ぎず、人間のような創造性(クリエイティビティ)がない。クリエイティビティには多数の組み合わせからなる可能な選択肢の中からよい案を探し出す必要があり、それは検索機能が必要だ。可能性空間のよい検索方法が考え出されるまで大規模言語モデルを超えるAIは不可能だろう。
グーグルといえば検索機能ですね。で、さっきのA*アルゴリズムはなんでしたか?そうですねA start searchです。検索機能です。
ハリーポッターをカニエウエストのスタイルで書き直してみたらどうだろう?とかそういう無限の組み合わせの中から良さそうなものを推測して絞り込んで、絞り込まれた少数の選択肢について別の角度から再確認して評価することで創造性のあるアイデアが生まれると言っているわけです。
良いこといいますね。
ビデオはここでDeepMindの話になって大規模言語モデルの限界の話(再学習させてアップデート大変、兎に角学習データの質が命)になりますので、Q starが何かについてはあとは想像になります。
素人によるQスターの推測
つまり、AIがビデオゲームを何億回もプレイしながら強化学習(Q-Learning)でうまくなれるのわけですが、ゲームの内容が複雑(現実世界)になるとゲームの状態と自分が取れる選択肢が増えていきます。またゴールについても長期的・中期的・短期的な良し悪しを考え出すと、その瞬間瞬間に考慮すべきことの項目が爆発的に増えていきます。それでも現時点のゲーム状態とそれに対する行動選択肢をQ tableで表現することは可能です。そして、AIとしては不完全なQ tableの推測値しかない状態からこの膨大な大きさのQ tableの推測値を改善していく必要があるわけで、そのあたりをDeep LearningでQ tableのどの辺りに良い回答がありそうかを不完全な情報から推測しながら行動してデータを取りつつ推測値をアップデートしながらまた推測と繰り返すことで膨大な可能性の全ては網羅できなくても最適解に近いスマートな回答を出せるかもしれません。
そんな感じに広大なQ tableの中で探索すべき部分、無視すべき部分をフィルターすることが大事でありアルファGoはまさにこれをやったわけです。つまり、
A starのアルゴリズムに数学的に近いアプローチ、性質をもったDeep LearningのアルゴリズムでもってQ tableのフィルター、取捨選択、検索をやったものがQスターなんじゃなかろうか?
そうすれば現在の大規模言語モデルではできないアップデートの問題がなくなり、常に最新データを投げ続けて改善しつづければ良くなりますし、データの質の問題も学習最初はともかく検索の段階である意味で良いデータと悪いデータを振り分けているのでこれもクリアできそう、と素人が推測しました。適当です。真に受けないで自分で確認して下さいね。
おわり。