
業務で使う、電子素子のデータシートからPYTHONで必要グラフを抽出した話

こんばんは、以前、スプレッドシートAPIについてお話しました。
最近、主業の車載ECU設計にあたり、計算書を作成する必要があり、
使用する電子部品素子のPDFから画像をちまちまとってきているというめんどくさい業務があったので、それを意識した記事を書きたいと思います。
実際の業務手順はこれ
①各メーカのデータシートをダウンロード。
自動化できるか?→否 ダウンロードしに行ったほうが早い。
まぁ一覧くらい作って、特定フォルダにぶっこむところくらいはやってもいいかも。
②PDFから素子データ抽出(テキスト情報はOCR対応できる)
ここら辺は多分ちょろいと思う。概要は↓を応用予定。今回は論じない予定
③PDFからグラフを抽出したい。
本編のメインはここです。狙いは、PDFからグラフを抽出して、
エクセルでも、スプレッドシートでも、バシバシ勝手に貼り付けたい。
実際のところ、データシートから読み取りが必要な情報が結構あるため、
ここはかなりめんどくさい。
PDFからの画像読取は、OPENCVを使う。
④OPENCVについて
OpenCV(Open Source Computer Vision Library)は、コンピュータビジョンや画像処理のためのオープンソースライブラリです。初めはインテルが開発し、その後、開発はコミュニティによって継続されています。OpenCVは、画像処理、ビデオ解析、物体検出、機械学習、ディープラーニングなど、さまざまなコンピュータビジョンタスクをサポートしています。C/C++ベースで開発されており、PythonやJavaなどの他の言語でも利用可能です。高速な画像処理や、カメラキャリブレーション、物体追跡、リアルタイムの画像解析など、幅広いアプリケーションに使用されています。また、豊富な機能とモジュールにより、研究、教育、産業界でのプロジェクトに広く活用されています。OpenCVは、コンピュータビジョンや画像処理の開発者コミュニティにとって不可欠なツールとして認識されています。
⑤作成コード
これが実際に作ったコード。
自分が使いやすいようにいろいろチューニング
OPENCVはnpも使う。正直あまり、慣れてない。
必要ライブラリをインポート
from pdf2image import convert_from_path
import pytesseract
import cv2
import matplotlib.pyplot as plt
import os
import numpy as np
import glob2.ダウンロードファイルの前処理→画像化
ここから、まずは、確認したいデータシートをダウンロード→保管した
ディレクトリを指定。今回は、東芝TTC017というトランジスタ。
(いろいろ主業で苦労させられているもの)
ここで、まずOPENCVの偉大さがよくわかる。今回ページとしては、
たかだか、7ページだが、すべて画像データとして、分割&保存。
凄まじい。
# PDFファイルのパスを指定
pdf_file = r"C:\Users\Owner\Desktop\work_current\TTC017_datasheet_ja_20150324.pdf"
# 変換したいPDFファイルを指定して、PDFから画像に変換
pages = convert_from_path(pdf_file)
# 画像ファイルを保存するパス
output_path = r'C:\Users\Owner\Desktop\work_current\output\output'
# 各ページをJPEGファイルとして保存
for i, page in enumerate(pages):
page.save(f'{output_path}page_{i+1}.jpg', 'JPEG')

3.画像読み込み フィルタ処置→2値化
画像化したデータシートをOPENCVで読み込む。
ざっとした流れはこんな感じ
①:グレイスケール(モノクロ)で読み込み
image = cv2.imread(i,0)#0でグレースケール
いろいろネットに読み込み方が書いてあるが、上記が一番手っ取り早い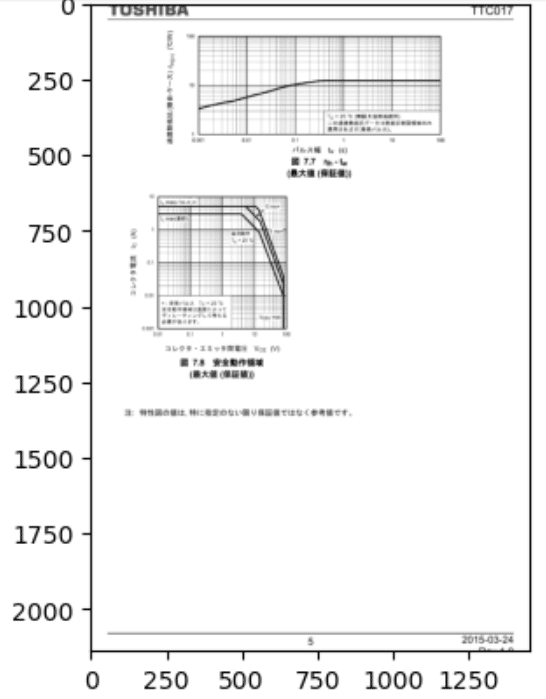
②:クロージング*処置(フィルター処理)
PDFの画像には、細かいゴミや、いらない空白などがあるため、それを極力少なくする処理。正直、このフィルター作業、いろんな処置方法があり、
最適を探すのにかなり時間がかかった。細かい説明は割愛。
*:膨張→縮小して、いらない形状をつぶすフィルター処置
#フィルタ処理膨張
kernel = np.ones((45, 100), np.uint8)
#フィルタ処理膨張
image1 = cv2.erode(image, kernel, iterations = 1)
image1 = cv2.dilate(image1, kernel, iterations=1)
#plt.imshow(image1)
#plt.show()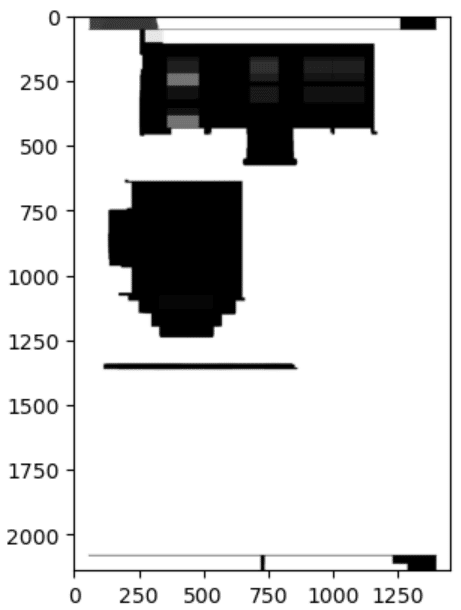
③:モノクロ状態を2値化(白黒を際立たせて、黒色部分の輪郭を取得)
一回目の2値化、1回目はどうしても、要らない輪郭が登場するので、それを把握することが目的。contoursで、矩形の座標、高さ、幅情報を把握。
threshold にて、濃さが250以下を白と判定。
# 閾値の設定
threshold = 250
ret,image2= cv2.threshold(image1, threshold, 255, cv2.THRESH_BINARY)
#plt.imshow(image2)
#plt.gray()
#plt.show()
#形状の外形を示す矩形情報を取得
contours = cv2.findContours(image2, cv2.RETR_CCOMP, cv2.CHAIN_APPROX_SIMPLE)[0]
#print(len(contours))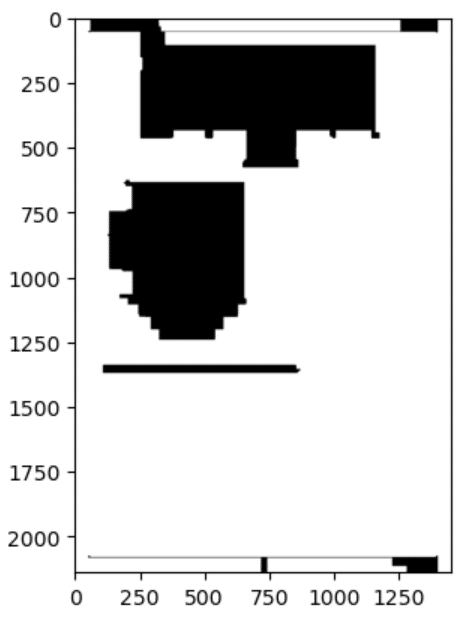
④:いらない輪郭を消す作業。
考え方は以下。③で手に入れた、輪郭で、明らかに要らないであろう、矩形を面積で判定させる。(AREA‗MAX=500)面積500未満の矩形は不要、
対象部分を白塗りする作業
#ゴミ除去のためフィルタ
new_contours=[]
FILL_COLOR=(255,255,255)
AREA_MAX=500
i=0
#print(contours)
for c in contours:
s=abs(cv2.contourArea(c))
#print(s)
if s <= AREA_MAX:
new_contours.append(c)
#print(len(new_contours))
#print(new_contours)
image3 = cv2.drawContours( image, new_contours, -1,FILL_COLOR,-1)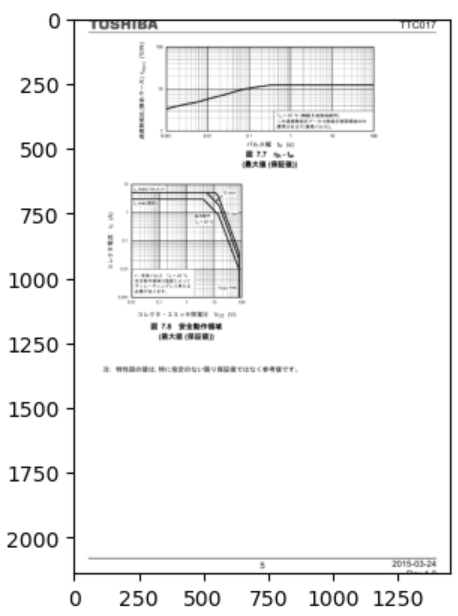
⑤:白塗りして、不要な形状を削除した状態で、再度輪郭を取得。
やってることは③と同じ。
#フィルタ処理膨張
kernel = np.ones((45, 100), np.uint8)
#フィルタ処理膨張
image4 = cv2.erode(image3, kernel, iterations = 1)
image4 = cv2.dilate(image4, kernel, iterations=1)
#plt.imshow(image4)
#plt.show()
# 閾値の設定
threshold = 250
ret,image4= cv2.threshold(image4, threshold, 255, cv2.THRESH_BINARY)
#plt.imshow(image2)
#plt.gray()
#lt.show()
contours = cv2.findContours(image4, cv2.RETR_CCOMP, cv2.CHAIN_APPROX_SIMPLE)[0]⑥:⑤で取得した重ねた輪郭に合わせて、PDFを分割。
for i in range(1, len(contours)):
ret = cv2.boundingRect(contours[i])
cv2.rectangle(image, (ret[0], ret[1]), (ret[0] + ret[2], ret[1] + ret[3]), (0, 255, 0), 3)
image5 = image[ret[1]:ret[1] + ret[3], ret[0]:ret[0] + ret[2]]
#plt.imshow(image5)
#plt.gray()
#plt.show()
path = r"C:\Users\Owner\Desktop\work_current\output\survage"
path2 = ''+str(n)+str(l)+'.jpg'
path = os.path.join(path, path2)
cv2.imwrite(path,image5)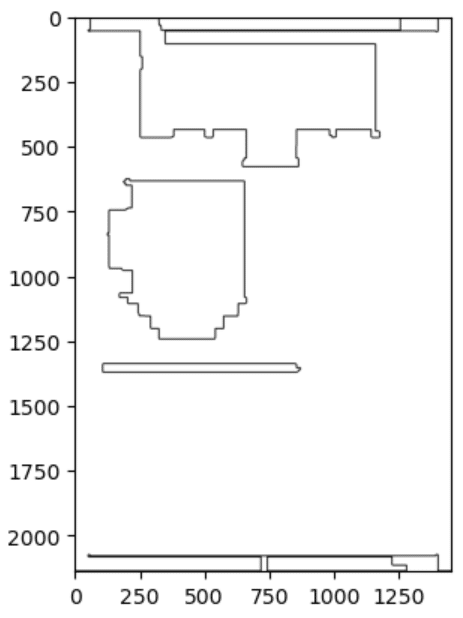


⑥まとめ
以下に、自動で全部サルベージできるようにプログラム済み。
最終的には、2000ページくらいある、マイコンもこれで対応できるか?
# 画像を読み込む。
os.makedirs(r"\Users\Owner\Desktop\work_current\output\survage", exist_ok=True)
file_list = glob.glob(r"C:\Users\Owner\Desktop\work_current\output\*.jpg")
#print(file_list)
n = 1
for i in file_list:
#print(i)
image = cv2.imread(i,0)#0でグレースケール
"""
triming = 100
height, width = image.shape[:2]
image = image[triming:height - triming, triming:width-triming]
print(height, width)
plt.imshow(image)
plt.show()#確認用
"""
#フィルタ処理膨張
kernel = np.ones((45, 100), np.uint8)
#フィルタ処理膨張
image1 = cv2.erode(image, kernel, iterations = 1)
image1 = cv2.dilate(image1, kernel, iterations=1)
#plt.imshow(image1)
#plt.show()
# 閾値の設定
threshold = 250
ret,image2= cv2.threshold(image1, threshold, 255, cv2.THRESH_BINARY)
#plt.imshow(image2)
#plt.gray()
#plt.show()
#形状の外形を示す矩形情報を取得
contours = cv2.findContours(image2, cv2.RETR_CCOMP, cv2.CHAIN_APPROX_SIMPLE)[0]
#print(len(contours))
#ゴミ除去のためフィルタ
new_contours=[]
FILL_COLOR=(255,255,255)
AREA_MAX=500
i=0
#print(contours)
for c in contours:
s=abs(cv2.contourArea(c))
#print(s)
if s <= AREA_MAX:
new_contours.append(c)
#print(len(new_contours))
#print(new_contours)
image3 = cv2.drawContours( image, new_contours, -1,FILL_COLOR,-1)
#plt.imshow(image3)
#plt.gray()
#plt.show()
#ゴミ除去後やり直し
#フィルタ処理膨張
kernel = np.ones((45, 100), np.uint8)
#フィルタ処理膨張
image4 = cv2.erode(image3, kernel, iterations = 1)
image4 = cv2.dilate(image4, kernel, iterations=1)
#plt.imshow(image4)
#plt.show()
# 閾値の設定
threshold = 250
ret,image4= cv2.threshold(image4, threshold, 255, cv2.THRESH_BINARY)
#plt.imshow(image2)
#plt.gray()
#lt.show()
contours = cv2.findContours(image4, cv2.RETR_CCOMP, cv2.CHAIN_APPROX_SIMPLE)[0]
#print(len(contours))
l = 1
for i in range(1, len(contours)):
ret = cv2.boundingRect(contours[i])
cv2.rectangle(image, (ret[0], ret[1]), (ret[0] + ret[2], ret[1] + ret[3]), (0, 255, 0), 3)
image5 = image[ret[1]:ret[1] + ret[3], ret[0]:ret[0] + ret[2]]
#plt.imshow(image5)
#plt.gray()
#plt.show()
path = r"C:\Users\Owner\Desktop\work_current\output\survage"
path2 = ''+str(n)+str(l)+'.jpg'
path = os.path.join(path, path2)
cv2.imwrite(path,image5)
l = l + 1
n = n + 1
こんなのものやってます。