
政治資金収支報告書×Python×検討

政治資金収支報告書は、政治家や政治団体が受け取った寄付や支出などの収支情報を公開するための文書です。これらの報告書は一般に公開されており、政治の透明性や公正さを担保するために重要な情報源となっていますが、昨今この法律を蔑ろにする方々が多かったので、pythonでいろいろできないか、模索してみました。
データの収集と前処理
まず、政治資金収支報告書のデータを収集する必要があります。政府や自治体のウェブサイトからデータをダウンロードするか、オープンデータポータルなどから入手することができます。今回は、例の不明を記載なされた、
収支報告書を分析してみたいと思います。
以下からダウンロード。
まぁいっぱいあるわ。読ます気が全くない書類ですよ。
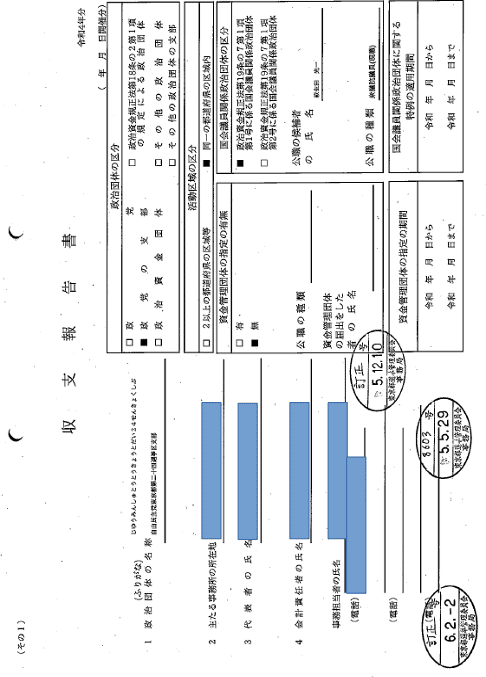
例の人のPDF一枚目 自由民主党東京都第二十四選挙区支部。もうさ、
PDFでダウンロードできるけど、全部90度回転。ほんとくそ。
データの分析と可視化
次に、Pythonのデータ分析ツールやライブラリを使用して、収支報告書のデータを分析し、可視化してみたいですが、今回はOCRを使ってみた。
今回はpdf2imageただし、pdfが横向きで分析しにくいので、写真に変更して、すべて右側に90度回転。
from pdf2image import convert_from_path
import pytesseract
from PIL import Image
from pdf2image import convert_from_path
import cv2
# PDFファイルのパスを指定
pdf_file = r"C:\Users\Owner\Downloads\sn74lvc7001a-q1.pdf"
# 変換したいPDFファイルを指定して、PDFから画像に変換
pages = convert_from_path(pdf_file)
# 画像ファイルを保存するパス
output_path = r'C:\Users\Owner\Desktop\work_current\output\output'
# 各ページをJPEGファイルとして保存
for i, page in enumerate(pages):
# JPEGファイル名を指定
jpg_file = f'{output_path}page_{i+1}.jpg'
# 画像を保存
page.save(jpg_file, 'JPEG')
# 画像を読み込む
img = cv2.imread(jpg_file)
# 画像を横向きに回転させる
#rotated_img = cv2.rotate(img, cv2.ROTATE_90_CLOCKWISE)
# 回転後の画像を保存
#
cv2.imwrite(jpg_file, img)こいつを動かしてみるとpdf103枚を全部横向きにして、.jpgに変更可能。


いざ OCR
データを横向きに変更できたので、OCRを実施。いかがなものか。
# 画像ファイルのパスを指定
image_path = r'C:\Users\Owner\Desktop\work_current\output\outputpage_2.jpg'
# 画像ファイルを開く
img = Image.open(image_path)
# OCRエンジンでテキストを抽出
text = pytesseract.image_to_string(img, lang='jpn') # 日本語の場合、lang='jpn'とします
# 抽出したテキストを表示
print(text)出力結果は、以下

結論
政治家の収支報告書では、OCRもままならないくらい読みにくい資料であることが確認できました。
今後は、別のライブラリを使用できないか考えてみよう。
でも。他のもっと見やすい資料なら、このプログラムも使い勝手よさそう。
この記事が気に入ったらサポートをしてみませんか?