
「GPT4新機能ハッカソン24耐」に参加してきました

お久しぶりです。レトリバ武井です。
前に記事を書いてからずいぶん間が空いてしまいました。時の流れとは速いものですね。
さて、今回は2023-11-17から2023-11-18にかけて行われた「GPT4新機能ハッカソン24耐」というハッカソンイベントの参加サポートと作ったアプリの紹介記事となります。
わたくしごとですが、ハッカソンというイベントが実はこれまで一回も出たことがなく、初のハッカソン参加となりました。
当日作ったアプリは私個人の方のgithubにも上げていますので、そちらもご参考ください。
https://github.com/takei-yuya/gpt4-hackathon-20231117/
「GPT4新機能ハッカソン24耐」ハッカソンについて
まず、このハッカソンについてですが、 詳細はconnapassのイベント概要をご参考ください。
11/17日19時にはじまり、翌11/18の19時に終わる、「24耐」、24時間耐久ハッカソンとなっています。
が、入退室自由ということで、私は一度家に帰らさせていただきました。さすがに金曜勤務から連続はつらい……!
ハッカソン開催の3日前の、11/14に参加表明してどうにか調整していただいて参加させていただく運びとなりました。
ありがとうございます。
当日オープニングセッションで発表された内容としては、
ルール0: OpenAIを使え
ルール1: 沢山作れ
ルール2: すごいものを作れ
ルール3: 笑えるものを作れ
という4つのルール、そしてテーマとして
「その手があったか!」
というシンプルな、というか割と自由なテーマのハッカソンでした。
ちなみに、「その手があったか!」というテーマに対して、
「画像をアップロードしたら手の画像かどうか認識して、手だったら「温かそうな手」の画像が出てくる「その手が温か!」なんてどうでしょう」
などとしょうもない冗談をつぶやいたら、すぐ隣で爆速で実装されてしまいました。
これがハッカソンの速度感!
他にも、GPTで般若心経や走れメロスをギャル語で読んでくれるギャル語変換アプリ (note記事)や、
シナリオがわかってしまうとネタバレになってしまうため、一生に一度しか遊べないゲームであるマーダーミステリーに対して、シナリオ前半だけ与えてあとはAI任せで遊ぶマダーミステリーゲームエンジン (note記事) だったり、
あるいは、物理デバイスと連携させて、デバイスから与えられる「引っ張られる感覚(牽引力錯覚)」に従うと勝手にクイズに正解できちゃう謎デバイスが出てきたりと、
自由なアイデアが飛び出すハッカソンでした。
特にギャル語変換アプリは、その変換結果がハッカソン中にAmazon Kindleで出版されて購入できるようになっているなど、行動力のパワーで優勝をもぎとっていきました。
成果物
さて、私の成果物ということで、このイベント中で、2つのアプリを作成しました。
一つは「テセウスの船」と題して、DALL·E 2モデルのImage generation APIのEdits機能を使った小ネタを、
もう一つは、「お絵描きしりとり」と題して、画像認識、対話、画像生成を作ったちょっとしたアプリを、それぞれ作成したので紹介します。
「テセウスの船」
こちらは、後述の「お絵描きしりとり」を一通り作り終わったあと、あと3~4時間というぐらいのときに、もう一個ぐらいなにか作れないかな、と思って作った小ネタとなります。
ソースコードはこちら
https://github.com/takei-yuya/gpt4-hackathon-20231117/tree/main/theseus
まず「テセウスの船」という言葉についてですが、これは帝政ローマ時代、プルタルコスによって挙げらた哲学上のパラドクスで、
簡単には「複数の部品からなる船を、部品が朽ちるたびに新しい部品に順次置き換えていったとき、もしすべての部品が入れ替わったら、その船は元の船と「同じ」船といえるかどうか」という話です。
より細かい話についてはWikipediaの記事などをご参考ください。
同名の漫画、またそれをもとにしたテレビドラマから、この言葉を知ったという方も多いのではないでしょうか?
さて、なんでこんな話をしたのかというと、OpenAIのAPIリファレンスを眺めていたとき、「Create image edit」というAPIを見つけました。
これは、画像とマスク画像を与えると、マスク画像によってマスクされた部分はそのままに、マスクされていない部分をAIがプロンプトに従って「いい感じ」に埋めるAPIとなっています。
ドキュメントの例だと、プールのあるラウンジの画像と、プールの一部分に穴をあけたマスク画像、「フラミンゴがいる」というプロンプトの組み合わせで、ラウンジのプールにフラミンゴを描かせています。
では、もし、このAPIを使い、画像の全体を順次、AIの生成した画像に置き換えていって、すべてのピクセルが置き換わった時、
「テセウスの船」の逸話ように、元の画像と同じといえるだろうか?、あるいはAIが生成したと呼んでよいのか、
あとは、単純にどんな風に置き換わっていくのだろうか?などと思い立ってしまい、じゃぁ試してみよう!といった流れで作ってみました。
実装としては、すごく単純に、全体を8x8に区切り、64のマスのうち1つだけ「穴」をあけたマスク画像を64種類用意し、ランダムな順序で、
元画像を起点に、生成された画像とマスク画像をEdits APIに順次投げ込むだけ、という実装になっています。
プロンプトは一貫して「A ship」という端的なテキストを利用しました。
当日発表では、Google画像検索にて「船」を検索したとき、一番最初に出てきた、内航海運様のタンカー画像をお借りして、
柱の一部が変わったり、背景の雲がちょっと変わったり、という細かなを観察しつつ、最終的にすべてのピクセルがAIが生成したものに置き換わった画像をして、
じゃぁ、これは元の画像と同一なのか、AIが生成したものといえるのか、という「テセウスの船」を題材に疑問を投げかけ、発表を終えました。
ここでは、違う画像となりますが、みなさまおなじみの「いらすとや」さんから、
「豪華客船・フェリーのイラスト」をお借りして、実行してみた例をあげてみます。

この例では、海に魚が発生したり、窓の形が微妙に変わったり、急にリアルな碇(?)が付いたり、煙突が変な形になったり、と変異を遂げています。
本当はこれを前座に、もう一つ、メインで作った「お絵描きしりとり」の発表のする予定だったのですが、話が長くなってしまい時間切れとなり、
当日の発表はここでおしまいとなってしまいました。
……最後の30分ぐらい暇してたので、発表時間を意識した発表練習をしておけばよかったなぁ、というのが今回の反省です。
「お絵描きしりとり」
こちらが、実はメインでハッカソン中に書いていたアプリとなります。
個人的な話になるのですが、株式会社ガンズターン様が公開されているアプリ「イラストチェイナー」というゲームがあり、私のお気に入りのゲームになっています。
これは、他人の書いた絵をみて、何が書いてあるか推測して、しりとりになるよう次の絵を描いて、相手に当ててもらって、を繰り返すゲームです。
非常に好きなゲームなのですが、その性質上一人で遊ぶことができず、遊び相手を探す必要があります。
(イラストチェイナーのアプリにはFREE ROOMという、誰かとマッチングして遊べるモードもあるのですが、人見知りの私にはハードルが高いので……。)
そこで、これを一人で遊べるようなると個人的にうれしいなぁ、という野望をもとに、
今回GPTの強化で入った、GPT-4 Turbo with Visionによる画像認識と、既存のDALL-Eによる画像生成を合わせて、AIとプレイする一人用モードが作れるのでは?とハッカソンのネタにしてみました。
実際に、作成したアプリを元にどんなしりとりができるのか試してみます。
本当はGUIでガワを作りたかったのですが、時間が足らずコマンドラインツールになっています。
実行例
起動すると、以下のようなプロンプトがでます。今回のしりとりの先頭は「す」です。
「す」から始まる画像のURLを入力します。
「ん」で終わる場合、一文字手前の文字を使います
しりとりの最初の文字は「す」です
ラウンド1/5: 単語を表す画像のURLを入力してください今回は、例のごとくいらすとやさんから画像をお借りしまして、「すいか」の画像のURLを貼ってみます。

また、画像の推論の補助になるよう、文字数を入力します。「すいか」なので3文字です
ラウンド1/5: 単語を表す画像のURLを入力してください
https://1.bp.blogspot.com/-4twz96rvKOQ/X2VqQwHfKWI/AAAAAAABbDo/f8oN48v6xw8hGZFC230x2vm41KrymHUPgCNcBGAsYHQ/s1600/fruit_suika_kodama.png
何文字の単語ですか?
3頭文字の「す」、文字数の「3」、そしてURLの画像を元に、OpenAI VISION APIを利用し、画像認識を認識、なんの単語なのかを推測します。
そして、GPT-4のチャットで次の単語を生成し、DALL-E 2モデルで画像を生成します。
画像を認識しています...
次の単語を考えています...
画像を生成しています...
end of file reached
https://dalleproduse.blob.core.windows.net/...
●●●生成された画像はURLで返ってきますので、開いてみましょう。
もともとマウスで絵を描いてしりとりをする、というコンセプトだったので、GPT側はマウスで書いたような絵柄で画像生成しています。

「●●●」ということで、三文字の単語を生成したようです。
「すいか」の末尾の「か」、文字数3文字、生成された画像と照らし合わせて、これは間違いなく「カエル」でしょう。
これで、お絵描きしりとりの1ラウンドが終了です。
5ラウンドまでしりとりを繰り返し、最後にGPTがどのように認識していて、何を生成したのかを答え合わせをします。
ということで、ラウント2、「る」から始まる単語を考えます。
GPT4-Vの認識性能を試すため、ちょっと複雑に「ルームランナー」で行ってみましょう。
「ランニングマシン」「ランニングしている男性」いろいろ単語解釈できそうですが、しりとりの頭文字と、文字数「7」でちゃんと認識してくれるでしょうか?

ラウンド2/5: 単語を表す画像のURLを入力してください
https://4.bp.blogspot.com/-WSlIVeLJNzk/WwJaOJwU2HI/AAAAAAABMKs/-ObqKdLzbNMCEvrOT3jPk0xQn463HKWkwCLcBGAs/s800/gym_running_man.png
何文字の単語ですか?
7
画像を認識しています...
次の単語を考えています...
画像を生成しています...
https://dalleproduse.blob.core.windows.net/...
●
……なんでしょう?
犬っぽくは見えますが、「●」と一文字の単語のようです。
この文字数を取得するあたりは、OpenAIのFunctionCallingの仕組みを使い、単語と単語の読み(ルビ)を取り出して、ルビの文字数で「●」を出しているのですが、
時々、生成に失敗し単語とルビがひっくり返ってしまうことがあります。
そういう場合には検知してもう一回APIを発行しなおしてあげるのがよさそうですが、ハッカソン中はあまり起きなかったのでケアできていないです。
そして、「ルームランナー」は通じなかったような気配がしますね。
多分、「いぬ(ルビ: 犬)」なんじゃないかな、ということで、「ヌートリア」とかいってみましょう。

ラウンド3/5: 単語を表す画像のURLを入力してください
https://1.bp.blogspot.com/--PK9lhtyyaU/WMJK0DqrEgI/AAAAAAABCas/FU1OU0AKs3MvnxXMEYcBk468JpFt6FF9QCLcB/s800/animal_nutria.png
何文字の単語ですか?
5
画像を認識しています...
次の単語を考えています...
画像を生成しています...
https://dalleproduse.blob.core.windows.net/...
●●●●
4文字でこの画像。ライオンにしか見えないですね。「ヌートリア」も通じなかったようです……。
当日テストしてたときは、結構マイナーな動物にも意外に対応してくれていたのですが、ちょっとうまくいきませんね。
このお絵描きしりとりでは、「ん」で終わった場合、ゲームオーバーにせずに、一文字前の文字をしりとりに使うので、「ライオン」の「お」を使います。
しりとりを成立させたいので、ここは安牌、わかりやすそうな「おおかみ」あたりでいってみましょう。

ラウンド4/5: 単語を表す画像のURLを入力してください
https://1.bp.blogspot.com/-uvbG0mtEfaE/WMo-Z2m8emI/AAAAAAABCpY/SjC9G7q0sKkYlcexkbeALF7fQYBm3IwqwCLcB/s800/animal_ookami.png
何文字の単語ですか?
4
画像を認識しています...
次の単語を考えています...
画像を生成しています...
https://dalleproduse.blob.core.windows.net/...
●●●
おお、これは「みかん」。「おおかみ」からもつながりますし、文字数も3文字であっていそうです。
最終ラウンド、ラウンド5。
またも「ん」で終わっていますので、一文字手前の「か」を使って、最後、ちょっと攻めてロダンの「考える人」で行ってみます。

ラウンド5/5: 単語を表す画像のURLを入力してください
https://2.bp.blogspot.com/-nMjuko9tXGc/Ut0BV0jJHkI/AAAAAAAAdW0/tRb8t3PEY28/s800/kangaeruhito.png
何文字の単語ですか?
7
画像を認識しています...
次の単語を考えています...
画像を生成しています...
https://dalleproduse.blob.core.windows.net/...
●●
二文字で、この画像。「とり」でしょうか?だとするとちゃんと「考える人(かんがえるひと)」を認識できたように思われます。
さて、5ラウンドまでやったので、答え合わせの時間です。
ラウンド1、こちらは「スイカ」の画像を送りました。さて、どう認識されていたでしょうか?

https://1.bp.blogspot.com/-4twz96rvKOQ/X2VqQwHfKWI/AAAAAAABbDo/f8oN48v6xw8hGZFC230x2vm41KrymHUPgCNcBGAsYHQ/s1600/fruit_suika_kodama.png
文字数: 3
予想先頭文字: す
認識結果: すいかお、ちゃんと「すいか」と認識しています。
では、相手の返答です。「カエル」のように見えましたが、果たして

https://dalleproduse.blob.core.windows.net/...
文字数: 3
単語: かえる(かえる / frog)あっていました。
ラウンド2も続けていきましょう。
こちらから送った画像は、「ルームランナー」(ランニングマシンで走る男性のイラスト)でした。

https://4.bp.blogspot.com/-WSlIVeLJNzk/WwJaOJwU2HI/AAAAAAABMKs/-ObqKdLzbNMCEvrOT3jPk0xQn463HKWkwCLcBGAs/s800/gym_running_man.png
文字数: 7
予想先頭文字: る
認識結果: るんにんぐますしんる、「るんにんぐますしん」???
ちょっとよくわからない単語が飛び出しました。頭文字の「る」と「ランニングマシン」がどうもごっちゃになってしまったようです。
GPT-4 VISION APIはかなりの認識精度のモデルではあるのですが、制約条件などを付けると、こういう結果生成をしていまうことがあるようです。
そして、それに続く単語画像はというと……。
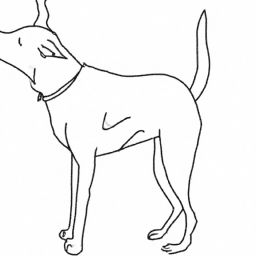
https://dalleproduse.blob.core.windows.net/...
文字数: 1
単語: いぬ(犬 / Dog)やはり、犬でした。
「単語:」の部分は、「単語: {単語}({ルビ} / {英語})」のフォーマットで出力しているのですが、やはり単語とルビがひっくり返ってしまったようです。
単語とルビがひっくり返ってしまった結果、ラウンド3の画像認識にも影響がでてしまいました。

https://1.bp.blogspot.com/--PK9lhtyyaU/WMJK0DqrEgI/AAAAAAABCas/FU1OU0AKs3MvnxXMEYcBk468JpFt6FF9QCLcB/s800/animal_nutria.png
文字数: 5
予想先頭文字: 犬
認識結果: ビーバー「予想先頭文字」が「犬」になってしまった結果、頭文字の情報がうまく使えず、画像からの推測で「ヌートリア」が「ビーバー」となってしまいました。
そして、「ビーバー」に続く、GPTのしりとりの単語はというと……

https://dalleproduse.blob.core.windows.net/...
文字数: 4
単語: ライオン(らいおん / Lion)うーん、ちょっとポンコツ。なんで「ビーバー」の次が、「ら」から始まるライオンなんでしょうね……。
とはいえここで、わかりやすい「ライオン」の絵がでてくれたのでラウンド4で挽回。
「おおかみ」のイラストに対する画像認識もあっており、生成された画像はこちら予想通り「みかん」の絵だったようです。


https://1.bp.blogspot.com/-uvbG0mtEfaE/WMo-Z2m8emI/AAAAAAABCpY/SjC9G7q0sKkYlcexkbeALF7fQYBm3IwqwCLcB/s800/animal_ookami.png
文字数: 4
予想先頭文字: お
認識結果: おおかみhttps://dalleproduse.blob.core.windows.net/...
文字数: 3
単語: みかん(みかん / Mandarin orange)ラウンド5は「考える人」と少し変化球を投げましたが、「とり」のような画像が返ってきており、しりとりがちゃんと繋がっていたので、きっと大丈夫でしょう。


https://2.bp.blogspot.com/-nMjuko9tXGc/Ut0BV0jJHkI/AAAAAAAAdW0/tRb8t3PEY28/s800/kangaeruhito.png
文字数: 7
予想先頭文字: か
認識結果: かんがえごとhttps://dalleproduse.blob.core.windows.net/...
文字数: 2
単語: とり(とり / bird)と、思ったら「考える人」じゃなくて「かんがえごと」でした。
文字数はあっていないですが、確かにこのイラストは「かんがえごと」していますね。
末尾の文字があっていたので、しりとり的には影響なく、予想通り「とり」で終わりです。
感覚的なところですが、GPTはトークンで文字列を生成・認識するため、文字数ぴったり、というに弱いイメージがありますね。
実装
実装に関しては、先ほどのリポジトリの別ディレクトリに置いています。
https://github.com/takei-yuya/gpt4-hackathon-20231117/tree/main/oekaki_shiritori
社内的な事情になるのですが、レトリバは Microsoft for Startups Founders Hub を通じ Microsoft for Statups プログラムへの参加をしています。
そのため、Azure OpenAI Service API前提でコードを書いていたのですが、画像認識のAPIであるVISION APIが、まだAzure OpenAI Serviceでまだサポートしておらず、
当日、急遽OpenAI本家側のAPIにクレジットを追加して、画像認識部だけOpenAIを使う、というちぐはぐな実装になっています。
また、Azure OpenAI Serviceの中でも、USリージョンではDALL-E 2が利用可能になっているものの、JPリージョンではまだ使えず、
逆にGPT-4のモデルは、JPリージョンではデプロイできるものの、USリージョンではデプロイできず、という背景があり、
結果的に3つのエンドポイントをはしごする実装になっています。
加えて、このUSリージョンのDALL-Eモデルは事前にテストしたところ、日本語に弱く、英語でプロンプトを与える必要があることがわかりました。
結果、
OpenAI のVISION APIで、画像を認識、
Azure JPリージョンのGPT-4モデルでしりとりの次の単語を生成し、しりとり用に読み(ルビ)と画像生成用に英語に翻訳した単語を作成、
Azure USリージョンのDALL-eモデルで、英語に翻訳した単語から画像を生成、
という流れになりました。
今思うと全部OpenAIのエンドポイントにして、一個のプロンプトで頑張る手もあったかと思うのですが、ハッカソンではこのようなコードになりました。
OpenAIと、Azure OpenAI Serviceとで、APIが異なるため、差異を吸収するようのクラスを書いてはいるのですが(openai_client.rb)、
こういった事情で、あまりテストはできておりません。
実装の本質は、基本的にはOpenAI、Azure OpenAI ServiceのAPIを叩くだけで、プロンプトを試行錯誤しているだけですが、
VISION APIに関しては、外部連携するための補助の仕組みである functions/tools や、
出力フォーマットを指定する response_formatなどに対応していないため、単語ひとつだけを抽出できるよう、Ruby側で補助しています。
あとは、CLIでユーザとのインタラクションをして、お絵描きしりとりを実装しています。
先にも書いた通り、本当はGUIまで作って、画面で遊べるようにしたかったのですが、ハッカソンということでコアの部分まで書いて終わりとしました。
画像を見るためにいちいちURLを開いたり、ゲームとしてもテンポ感が薄れてしまうので、いずれガワも作りたいところです。
なお、以上にあげた制限は、いずれも2023/11/18現在での制限となります。
たとえば、Azure OpenAI Serviceにおける、GPT-4 Turbo with Vision (GPT-4V)に関しては、Microsoft社の2023-11-15の発表の中で、
GPT-4 Turbo with Vision (GPT-4V): When integrated with Azure AI Vision, GPT-4V will enhance experiences by allowing the inclusion of images or videos along with text for generating text output, benefiting from Azure AI Vision enhancement like video analysis. GPT-4V will be in preview by the end of 2023.
と、年内にはGPT-4VのPreviewが利用可能になるとの情報が出ています。
この辺りは時々刻々と新しい情報が出ていますので、ぜひキャッチアップしていければと思っています。
総評
今回ハッカソンでいろいろなAPIを試し、何度も試行してはちょっとプロンプトをいじったり、プログラムで補助をしたり、とを繰り返していました。
全体的には、おおよそうまく動くものの、今回のお絵描きしりとりの実行例にも出てきた、謎の単語の生成(「るんにんぐますしん」)や、単語とルビのとり間違い、
「ビーバー」と予想したのに「ライオン」をしりとりに出す、など、まだまだちょっとした「ポンコツ感」があるなという印象です。
お絵描きしりとりというゲームにおいては、このあたりの「ポンコツ感」は意外性という面白さに変えられたのですが、
実用で使うには、まだまだ色々な工夫や、使いこなすためのノウハウが必要になるな、ということを感じた開発でした。
最後になりますが、今回ハッカソン参加にあたり、
企画してくださったshi3z様、
協賛・提供してくださった ZETA株式会社様、
会場提供してくださった note株式会社様、
初対面ながら快く受け入れてくださったML15チームの皆様、
そして、関わってくださった皆様全員に感謝申し上げます。
楽しいハッカソンイベントでした、ありがとうございます!