
Pythonを使って地声を読み上げに吹き替えてみた (pyannote.audio x whisper x VOICEVOX x OpenCV x SpeechRecognition x wave x FFMPEG)

こんにちはRcatです。
今回はこちらの記事で紹介している作品の解説版となります。
具体的には、地声で収録した動画を全自動で読み上げの実況に変換してしまうツールです。
さすがPythonいろんなライブラリがあって、組み合わせ次第で何でもできてしまいますね。
それでは中身について見ていきましょう。
はじめに
利用規約
情報や作品の活用時は事前に利用規約をご確認ください。
https://note.com/rcat999/n/nb6a601a36ef5
コメントについて
利用規約のガイドラインを確認の上コメントしてください
仕組み
まず、本作にはどのような要素が含まれているのか説明しておきます。気になるところだけ見ていただくのもOK。
具体的な処理手順としては次のようになります。
全体の処理手順
後ろにカッコ書きで書いてあるのは使うライブラリやソフトウェアです。
動画から音声をデタッチ(FFMPEG)
吹き替えに必要な地声音声データを入手音声の前処理(FFMPEG)
文字起こしの精度を上げるためにノイズ除去を行います。
有無ではかなり差があります。
こちらでどの程度差があるのか紹介しています。参考にしてください。
https://note.com/rcat999/n/n83bdd0d151ff音声を話者分離(pyannote.audio)
一言一言の発音区間を入手。どの単語を何秒間で話せばいいかという情報。音声データ分割(wave)
音声データを発音区間ごとに分解。文字起こし(whisper or speech_recognition)
分割した音声データを使って区間ごとに文字起こしを行います。
自分のパソコンで起こす場合はwhisper。
オンラインで起こす場合はspeech_recognition。LLMによる校正(Dify & Gemini)
読み上げソフトは辞書を入れておけば自動的にそのように読んでくれますが、手で入れておくのもなんか今時じゃないですよね。
ここはテキスト生成AIの力を使いましょう。音声読み上げ(VOICEVOX)
文字起こしした文字列をVOICEVOXで読み上げます。速度調整
キャラによって発音速度が違うので、発音区間に収まるように速度を調整しながら生成します。
こうすることで地声との整合性をとります。
連結(wave)
読み上げで出来上がったファイルを1つのファイルに連結します。
具体的には空のwavファイルを生成し、発音区間に応じて上書きしていきます。マージ(FFMPEG)
元の動画データに再度アタッチすれば吹き替え完了。テロップの追加(OpenCV & Pillow)
せっかく文字起こしをしているので、OpenCVを使って動画にテロップを書き込みます。日本語は非対応なので、その部分はPillowを使うことで補います。
使うライブラリやソフトウェアの紹介
ソフトウェア
FFMPEG
動画や音声ファイルの処理を行えるツールです。
今回は動画から音声を切り離したり、ノイズ状況を行ったり、ファイルのフォーマット変換を行ったりするのに使っています。VOICEVOX
テキスト読み上げソフトです。
1つのソフトの中に30キャラ以上が含まれており、多彩な声で読み上げが行えます。
実態がWebサーバーなので、PythonからAPIを叩きに行けるのが非常にありがたい。最近のアップデートからかわからないが、生成速度がだいぶ早くなった印象。
公式 : https://voicevox.hiroshiba.jp/
ライブラリ
pyannote.audio
話者分離を行うライブラリです。
話者分離は、文字起こしなどを行わずに入力された音声ファイルで誰がいつ喋ったのかという情報を分析する手法のことのようです。whisper
OpenAI製の音声認識AIです。
こちらに実況の音声を入力してテキストに変換します。強力なGPUが必要です。SpeechRecognition
こちらも音声認識のライブラリです。
様々なサービスに対応しているようですが、とりあえず簡単そうなGoogleを使っています。オンラインで変換できるので、性能の低いパソコンでも文字起こしができるのか特徴です。wave
wavサウンドファイルを読み込んだり、書き込んだりするのに使う標準ライブラリです。
今回は話者分離で得た情報を元に区間ごとにバラバラにするのと、最後に1つのファイルにマージするために使います。OpenCV
言わずと知れた動画編集ライブラリです。
こちらを使って動画の中からフレームを読み取り、テロップの書き込みなどを行います。Pillow
こちらも言わずと知れた画像編集ライブラリです。
画像に日本語のテキストを埋め込むために今回は使います。
全体のソースコードについて
さすがに1000行以上のソースコード全てを解説はしません。
ここではポイントとなる箇所だけの解説を行います。
ソースコード全体はこちらの記事で配布を行っていますので、関数やクラス同士の関係性などを詳細に知りたい人は配布を受けてください。
ステップ1 動画から音声を分離する
本作の始まりは音声データの入手です。
まずは一番手っ取り早い"実況しながら録画を行う"という手法で収録された地声入り動画を処理する前提とします。
そのため、まずは動画から音声を切り離す必要があります。
ソースコード
こちらが動画を切り離すためのソースコードです。
ちょっとメモ書き用のコメントが含まれていたので、そちらは見なかったことにしてください。

とはいえ、やってることは単純で620行目から5行で済んでいます。
まずはsubprocessライブラリを使って外部のプログラムを起動しようとしています。起動する内容はffmpegです。
普通のコマンドラインにするとこんな感じ
'ffmpeg -i 入力データ -q:a 1 -map a -f wav - -map 0:v ビデオの出力先'この内容は入力された動画を音声と無音動画に分離するという意味です。
また、特徴として音声の出力先は標準出力にしています。
こうすることで、いちいちファイルを介すことなく、バイトIOでデータを扱うことができます。
ちなみにこの方法だとデータが8バイトだけおかしなことになるので、そこだけは注意。詳しくはこちら。
ステップ2 前処理
ソースコード
次に前処理のノイズ除去の工程です。
前工程データバイトIOを渡してノイズを除去します。
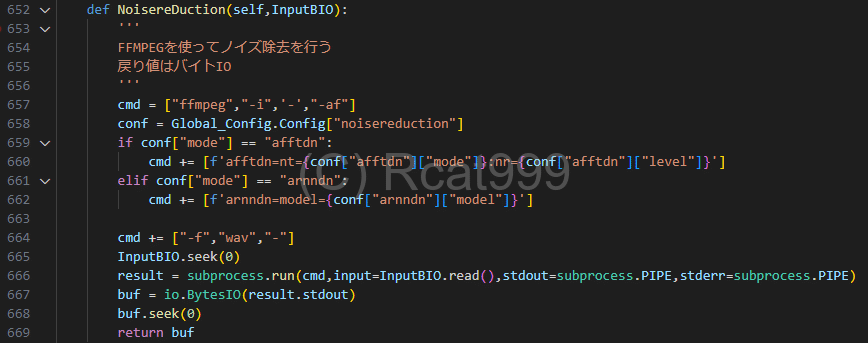
とはいえ、やってることは前回と同じでFFMPEGを使ってノイズ除去をかけています。
ノイズ除去のコマンドや種類と効果は以下の記事をご確認ください。
こちらでの特徴はファイルの入力も標準入力にしてしまったというところです。
最初のステップではまだ動画のファイルだったのでファイルを読み込んでいましたが、既にバイトIOに取り込んでいるので、それを標準入力して起動しています。もちろん出力もバイトIOです。
データのエラー訂正
次に今回のように標準出力を使った場合のみに起きる問題点を訂正します。
具体的にはデータの中でファイルサイズが書き込まれる領域に対して0xFFが書き込まれるという現象です。そのままでも再生できるので大丈夫かなと思ったんですが、waveライブラリを使った追加の処理を行おうとしたらエラーになってしまいました。
詳しくはこちらの記事で紹介しています。
ステップ3 話者分析を行う
音声データの処理が完了したら、次は喋っている区間の検出です。
そのままのファイルを文字起こしすることもできますが、それを読み上げるだけでは動画とのタイミングがずれてしまいますね。
そのため、発言ごとに区切って何秒からどれくらい喋ったのか?という情報を事前に入手します。
whisperライブラリは文字起こしと同時に、この辺りの情報も出力しますが、1秒単位でしか返さない場合もあるので、分析は別途行うこととしました。
また、予定ですが、話者分離つまり、誰がという情報を使えば複数のキャラクターでの読み上げが可能になるとも考えています。
ソースコード
まずは前半部です。
この辺は公式のところに書いてあるソースコードとほぼほぼ一緒です。
バイトIOを使ってデータを渡したかったので、事前に読み込みなども噛ませています。
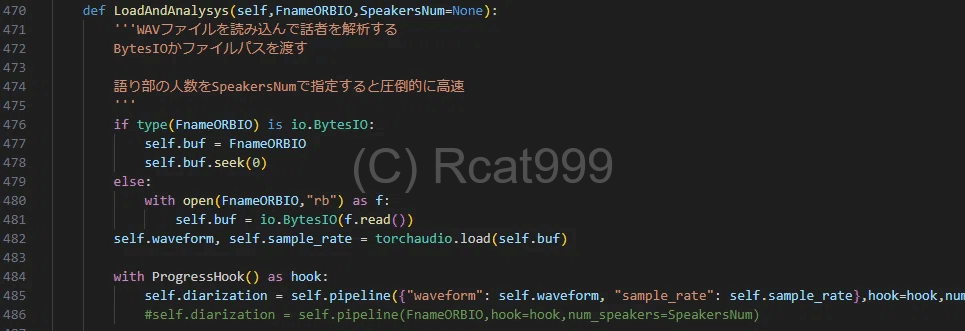
一番下のHookは進捗を表示するのに使います。短ければいいですが、長ければいつ終わるかわかんないのであった方がいいと思います。
また、このライブラリですが、事前に何人が話しているのかという情報を与えることもできます。
この場合、処理が圧倒的に高速になるので、できれば指定した方がいいです。特に今回の実況なんて1人で喋ってるだけなので1と入れるだけでいいです。
次に後半部です。
こちらは分析結果を受け取って整理する段階です。

この先で使うために、一旦辞書にデータをまとめ直しています。
得られる情報は、誰が話したのか?いつから話したのか?いつまで話したのか、何秒話したのかです。
また、誰がに関してはなぜか文字列で出てくるので、正規表現を使って数字だけに直しています。
後はよくわからないのですが、なぜか0.1秒の区間しゃべった判定になっている時などがあり、もちろん文字起こしもできなければ読み上げもできないので、そういった区間はなかったことにしています。
ステップ4 音声を区間に応じて分ける
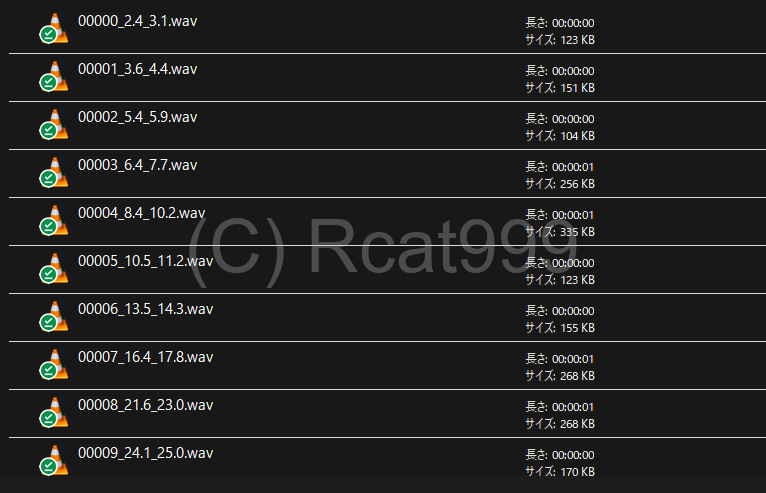
分析が済んだところで、次は分析と文字起こしの整合性を取るために事前にデータを分割します。
分割後は以下のような感じになります。
ソースコード
今回の処理に直接関係のない部分は塗りつぶしてあります。ツールの全体の動作には必要な部分ですので、気になる方はダウンロードしてみてください。
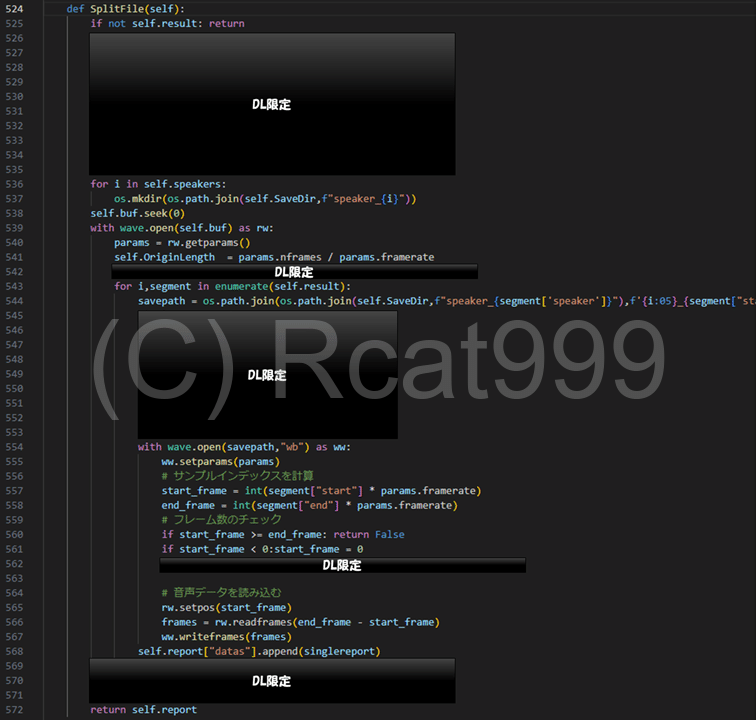
音声の処理が始まるのは539行目からです。
ここで開いているのは大元の地声だけの音声ファイルです。
その次にForループで区切っていますが、ループにかけているのは前回得た区間の情報です。
その中で区間からフレームを計算し、何フレーム目から何フレームまでを抜きとって保存するといった処理を繰り返しています。ちなみに上でやったデータのエラー訂正をしていない場合、ここでエラーになります。
ステップ5 音声認識で文字起こしを行う
さて、個別の音声データが出来上がったところで、いよいよ文字を起こします。
文字起こしをするメインの関数がこちらです。今回も関係ない箇所はわかりやすいように伏せておきます。
今回は2つのライブラリを選択できるようにしてあるので、まずは分岐から始まります。
ソースコードメイン

ソースコードwhisperの場合
自分のパソコンで文字起こしを行うwhisperの場合は以下のようになっています。正直コメントしかないですね。
主にメモ書きやGPUの使用を管理するためにクラスにしています。あとはインスタンスでモデルを読み込みっぱなしにできるので、後の作業がしやすいというのもあります。
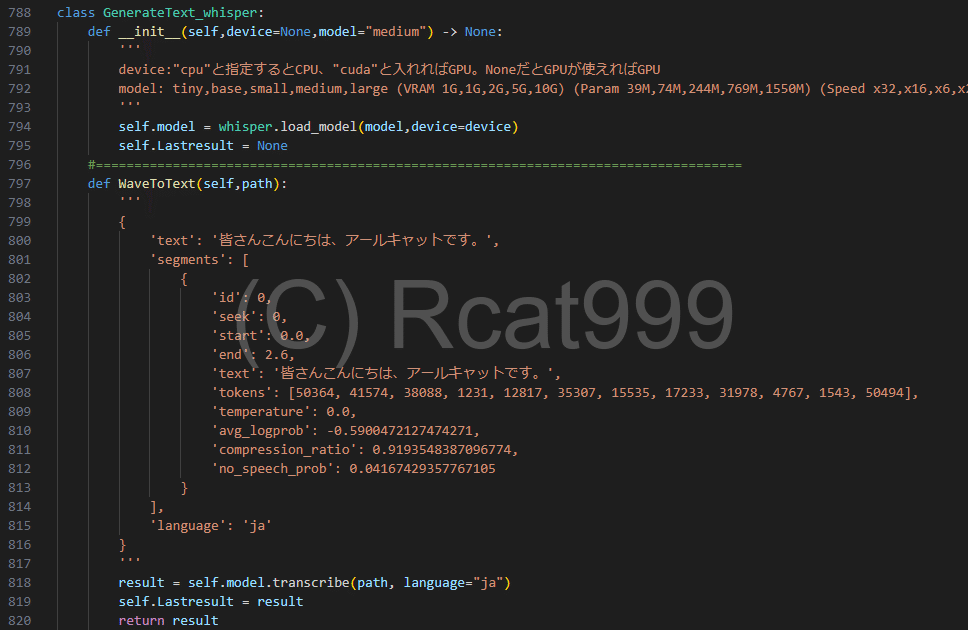
まずインスタンス時にAIを読み込んでいます。
この時にモデルの大きさを指定することができるので、精度と自分のパソコンの性能と相談して決めてください。モデルの種類や必要な性能はコメントに書いてあります。
そしてテキストの生成です。
ここではwavファイルのパスを渡すと文字として返すような関数にしています。ちなみにたくさんコメントが書いてありますが、これがwhisperが返してくる戻り値になります。
メインの関数で"text"というキーを抜き出していたのはこういう理由があります。
ソースコードspeech_recognitionの場合
オンラインで文字起こしをする場合のソースです。
こちらも調べればよく出てくるようなソースのままです。違いといえばバイトIOを使っているところでしょうか?

大きな特徴としては、認識にかける前に最後に1秒間無音区間を追加するという処理をしています。
これはspeech_recognitionライブラリのせいなのかrecognize_googleメゾット特有の動作なのかは分かりませんが、なぜか最後の方は認識できないという仕様があります。
そのため、喋っている音声区間ピッタリに区切ったファイルを入力すると、当然最後の数文字が文字起こしされなくなります。
それでは困るので、無音区間を1秒間追加してから投げるということをしています。
また、データを返す時の形式をウィスパーの方に合わせています。
まあテキストしか読まないのでテキストのキーを持った辞書にするだけなんですが。
ステップ6 校正
未実装
ステップ7 読み上げ
文字起こしが済んだら、いよいよ読み上げです。
ソースコードメイン
こちらが音声合成を行うためのメイン関数です。その名もステップ3。こちらも関係のない記述は一旦伏せてあります。
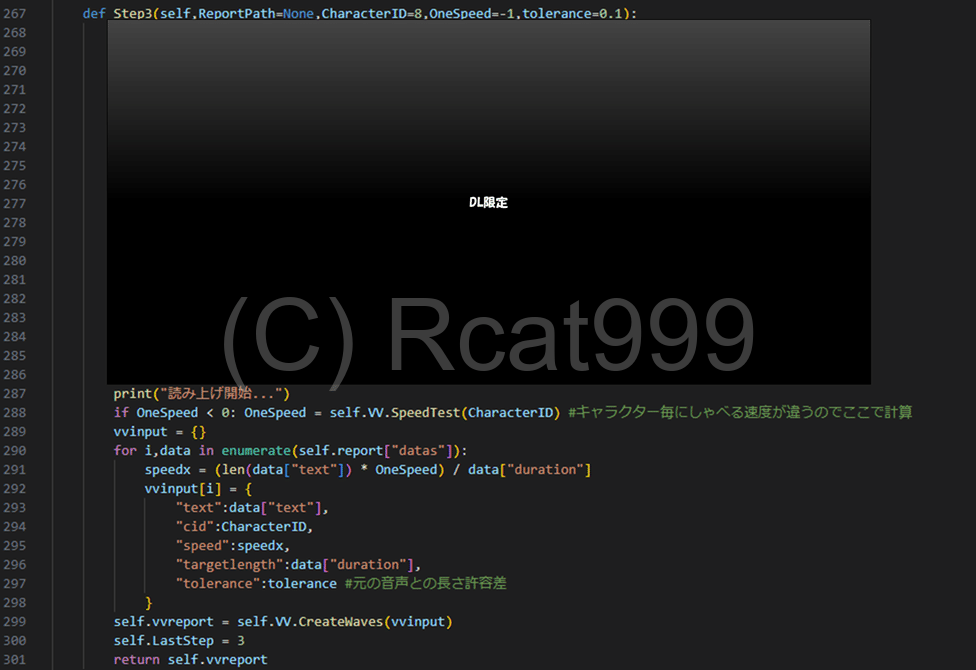
まず、最初にキャラクターがしゃべるスピードを計算します。キャラクターによってしゃべる速度はかなり違うからです。
この情報を元に、文字数から読み上げにかかる時間を予想し、発音区間内に収まる速度倍率を設定します。
そして読み上げ用データの作成です。
先に辞書で読み上げ用のデータを作成します。この中には読み上げるテキストやどのキャラクターを使うか、スピード倍率及び音声長さのターゲットの情報が含まれます。
最後に読み上げ関数を実行して、読み上げの音声データを作成します。

ちなみにボイスボックスはモジュール自体を分けているので、別でインポートしています。
ソースコードVOICEVOX
メイン関数から呼び出している読み上げ関数は次の通りです。
この関数はまとめて生成することを前提としているので、辞書形式で読み上げデータを入力していく必要があります。
上の方にコメントで書いてありますが、この形式で入力するようにメイン関数ではデータを作っていました。

ちなみに、ここではまとめで生成する都合上、音声ファイルを保存しそのパスを返すようなやり方をしています。
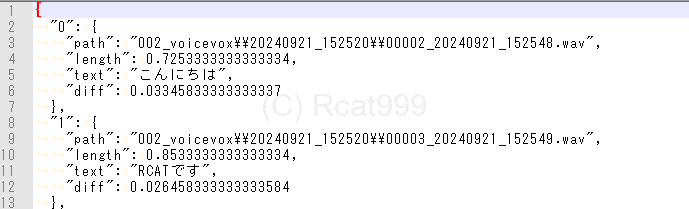
reportという変数がありますが、これがVOICEVOXが生成した音声ファイルなどの情報を含んだデータになります。
ちなみにレポートの中身はこんな感じです。
どこに保存したか、音声の長さ、内容、ターゲットからの差分が含まれています。
ソースコード VOICEVOX 読み上げリクエスト関連
次に具体的にどうやって生成をしているのかというところを見ていきましょう。
生成に使っているのは次の関数です。
VOICEVOXを使った読み上げには2つのステップがあります。
1つ目がテキストの分析と音声合成用のデータ作成です。この辺は公式のAPIリファレンスを確認していただいた方がいいかもしれませんが、まず、最初に読み上げるテキストを分析して、読み上げ用の符号に変換します。
具体的には指定されたURLに読み上げたいテキストをポストで送れば必要な情報が返ってくる仕組みです。

よくわかんないと思うので、実際の応答を見てみましょう。
このモジュールは手動でも実行できるので、実行すると以下のような結果が得られます(print行のコメントを解除した場合)。
import voicevox as V
v = V.VOICEVOX()
v.CreateWave("ねこかわいい",Cid=8,Play=True)
{
"accent_phrases": [
{
"accent": 1,
"is_interrogative": false,
"moras": [
{
"consonant": "n",
"consonant_length": 0.046383969485759735,
"pitch": 5.892535209655762,
"text": "ネ",
"vowel": "e",
"vowel_length": 0.0923309400677681
},
{
"consonant": "k",
"consonant_length": 0.05872572213411331,
"pitch": 5.988620758056641,
"text": "コ",
"vowel": "o",
"vowel_length": 0.08133900910615921
}
],
"pause_mora": null
},
{
"accent": 3,
"is_interrogative": false,
"moras": [
{
"consonant": "k",
"consonant_length": 0.052951984107494354,
"pitch": 5.742798328399658,
"text": "カ",
"vowel": "a",
"vowel_length": 0.07227755337953568
},
{
"consonant": "w",
"consonant_length": 0.04524584859609604,
"pitch": 5.88362979888916,
"vowel": "a",
"vowel_length": 0.06538953632116318
},
{
"consonant": null,
"consonant_length": null,
"text": "イ",
"vowel": "i",
"vowel_length": 0.15184266865253448
},
{
"consonant": null,
"consonant_length": null,
"pitch": 5.94594669342041,
"text": "イ",
"vowel": "i",
"vowel_length": 0.11915982514619827
}
],
"pause_mora": null
}
],
"intonationScale": 1.0,
"kana": "ネ'コ/カワイ'イ",
"outputSamplingRate": 24000,
"outputStereo": false,
"pauseLength": null,
"pauseLengthScale": 1.0,
"pitchScale": 0.0,
"postPhonemeLength": 0.1,
"prePhonemeLength": 0.1,
"speedScale": 1.0,
"volumeScale": 1.0
}これを見る限り、発音に必要な細かな情報が入っていることが分かります。
この情報を生成するのがステップの1となります。
次にオプションの変更です。一番下のところに"speedScale"や"prePhonemeLength"という表記があるのがわかるでしょうか?
これはそのまま話す速さや出力ファイルの無音区間を指定するものです。
ここを調整してファイルの長さを合わせます。当然ですが、無音区間はなしです。
これは辞書のキーを直接編集して行っています。
次に後半の読み上げ部分です。
ここでは、先ほど生成した読み上げ情報をポストすることで、読み上げされた音声のバイナリを得ることができます。
やることとしてはそんなに難しくなく、先ほど編集した情報をリクエストボディにくっつけてポストするだけです。
ただし、同じテキストでも何度も生成する可能性があるので、リクエストの部分だけ関数を分けています。
というのもいくら文字数から大体の速度を計算できたとしてもどうしても読み上げ全体の長さがずれることはあります。漢字が多かったり、ひらがなしかなかったり、英語が混じっていたりすればそれは当たり前ですね。

というわけで、この中のループでは読み上げたデータの長さを取得して、ターゲットで指定された長さと合致するかどうかを確認しています。
もし合わない場合、どのくらいずれているのか確認して速度を調整した後、もう一度挑戦します。
ちなみにぴったりは絶対に合わないので、デフォルトでは10%の長さ違いまでが許容されています。
まあ、それでも会わないことはあるので、だいたい6回ほど計算し直しても無理なら無理なことが多いので6回で打ち止めです。詳しい計算部分についてはダウンロードにしておきます。
これらの手順を踏んで読み上げを行います。

ステップ8 連結
さて、読み上げの音声が出来上がったら、次は全てを連結して1つの音声に戻します。
ソースコードメイン
こちらがそのメイン関数です。こちらも関係のない箇所は伏せてあります。
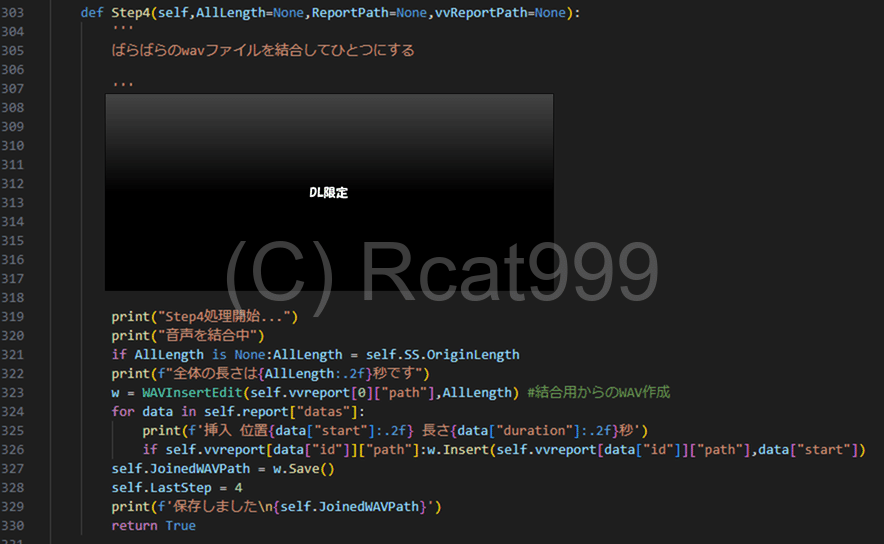
こちらではまず専用のクラスをインスタンスして空のファイルを作っています。
その後、読み上げたファイルをレポートを読み取りながら順次挿入していくという感じです。ここで言うレポートとは一番最初の話者分析のことです。あの時、何秒から話し始めたという情報を取得しましたよね?それはここで使うんです。
ソースコード 空のWAV挿入クラス
作成した挿入用のクラスはこちらです。
インスタンス時に全体の長さを決めて空のデータを作成します。
この時、ファイルを一緒に渡す必要があります。それはこの後挿入するデータとフォーマットを合わせるため、その情報を取得するためです。

インスタンスが終わったらInsertを使って順次指定した秒数のところにファイルを入れることができます。
全てのフレームを挿入し終えたらwaveライブラリを使って保存すれば1つのファイルにまとめることができます。
ここまでで吹き替えた音声データの作成が終了しました。
ステップ9 動画との再結合 テロップも添えて
さて、最後のステップです。
最初のステップで放置してある無音の動画と吹き替えた音声をもう一度くっつけます。
とはいえ、このステップは特に難しいことはありません。なにせFFMPEGがやってくれるのですから
ソースコードメイン
こちらがメインのソースコードとなります。今回も関係のないところが伏せてあります。
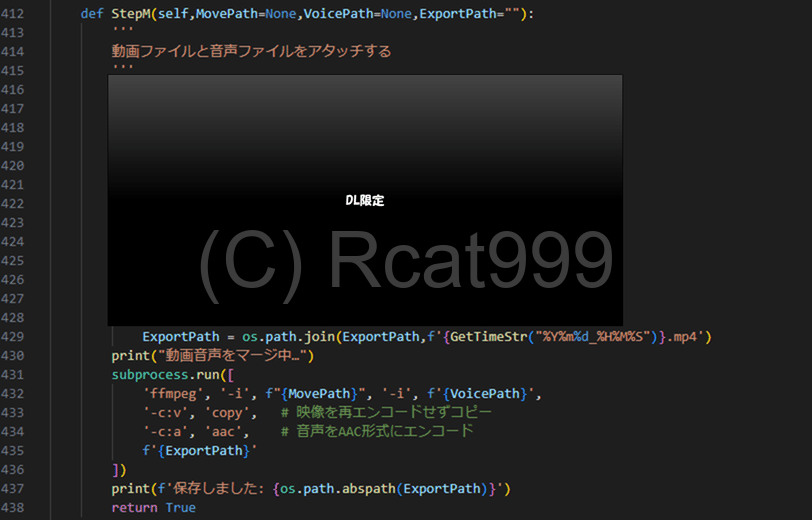
やっていることは保存先パスの作成とコマンドの実行です。
FFMPEGに対して無音の動画と今回作った吹き替え音声を選択します。また、オプションで映像には一切手をつけるなというオプションと一般的なAACで音声を付け加えるようにという設定があります。
映像に手をつけないことで、品質の劣化を防ぎ処理の高速化が見込めます。
なんとこれだけで吹き替え動画が完成しました。パチパチ
ソースコード テロップの入力
先ほどの動画を作る前に無音の動画を編集してテロップを入れる工程が実はあります。というのもこれはオプションなのでやらない場合もあるので、手順としては間違っていません。こちらが最後の手順です。
まずは前半部の紹介です。同じく関係のない部分は伏せておきます。
ここではOpenCVを使います。
無音の動画を開き、必要なプロパティを取得しておきます。
また、同時に出力用の動画も用意します。

テロップの設定です。
テロップは縦方向の大きさに対するパーセンテージで大きさを決めているので、その辺を計算しています。
そして後半部です。
ここでは動画のフレームを読み込みながら一つ一つテロップを刻み込んでいきます。
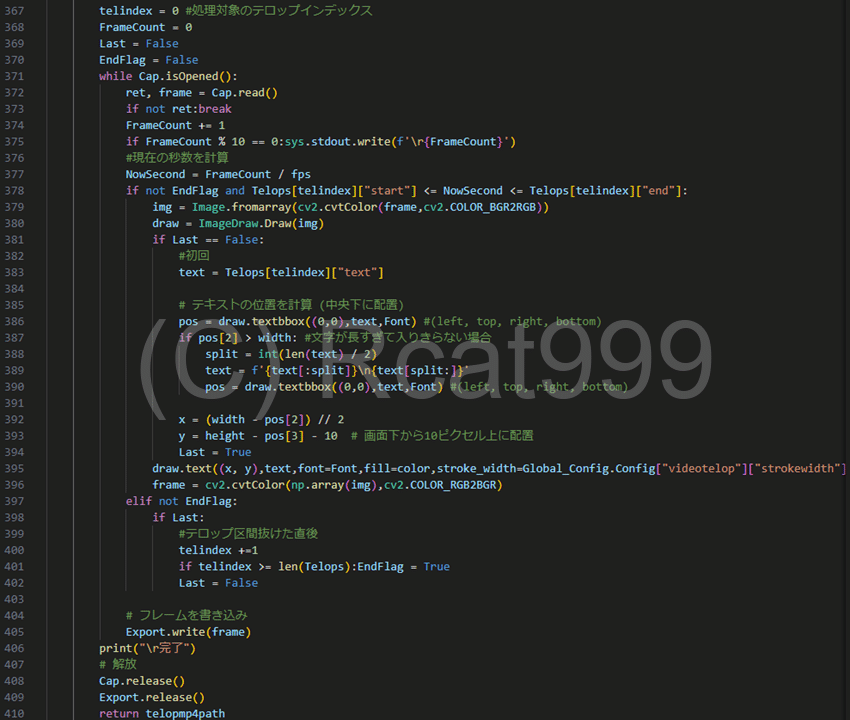
まず必要な情報はテロップがある区間にいるのかいないのかというところです。ここでも話者分析の、いつからいつまで喋ったのかという情報を使います。
この情報を元にフレームレートから現在のフレームがしゃべっている区間にいるのかいないのかで分岐を行います。
もし喋っている区間にいる場合はテロップを刻み込みます。
ちなみに余計な負荷をかけないように、入った時と抜けた時を検知して、その時だけテキストオブジェクトの生成などを行っています。
OpenCVにも文字を書き込む機能はあるのですが、英数字しか対応していないので、Pillowを使用して画像加工として文字を刻んでいます。
ここでポイントになってくるのが"textbbox"というメソッドです。
こちらはテキストを描写した時にどの程度の領域にテキストが出てくるのかを計算するメソッドです。
これを使うことで、画面の真ん中下にテロップを書き込むことができます。また、動作を確認していませんが、長すぎた場合1回だけなら折り返す機能もついてます。
ちなみにこの"textbbox"後のバージョンから追加されたもので、私の過去の作品だと似ている違うメソッドを使っていることがあります。最新バージョンだとそれは廃止されたので立ち上がらないんですよね…。
AIに聞いてもたまにこの古いメソッドの方で回答を出してくることがあるので、コピペで動かない場合はこの辺が問題になっていることが多いです。
古いメソッドはpillowのバージョン9番台まで存在しています。
まとめ
今回は全自動で地声の実況をVOICEVOX実況に変換するツールを解説しました。
Pythonは本当に色々なライブラリがあるので、アイディアと組み合わせ次第で何でもできてしまいますね。
まだいくつかつけたいけど、つけられていない機能もあるので、ゆっくりアップデートしていこうかなと思います。
それではまたお会いしましょう。
情報が役に立ったと思えば、僅かでも投げ銭していただけるとありがたいです。