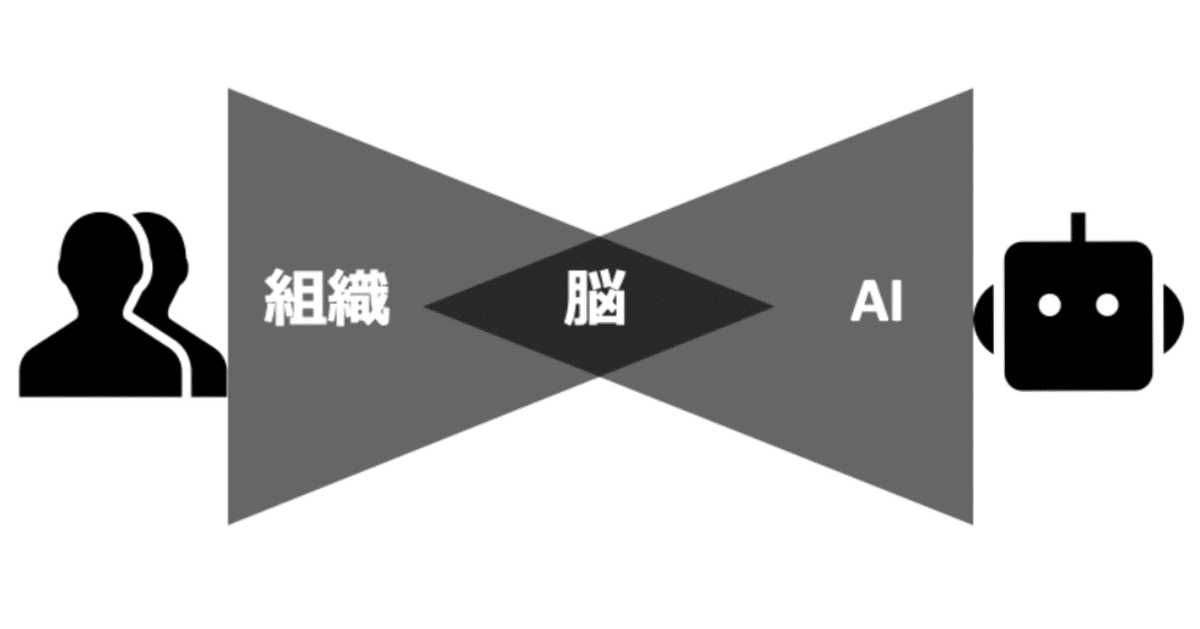
学習する組織・脳・AI〜経営から強化学習や囲碁AIまで

世界トップ棋士に勝利した囲碁AIの開発元であるDeep Mind(Google傘下)が、脳とAIに関する新しい発見をして、その論文が科学ジャーナルのネイチャーに先日掲載されました。強化学習について、最新のAIの仕組みが、脳のドーパミンの仕組みをうまく説明できるようです。
そこで、今回は学習をテーマにします。「組織」という集団による学習から、個人レベルの「脳」による学習、そして、「AI」による強化学習まで、一気通貫の旅です。(これぞ修学旅行)
組織については、世界的に評価される日本の経営学者であり、アジャイル開発のスクラムの源流を作った野中郁次郎氏の理論をベースに、僕自身がLINEのAI事業LINE BRAINを立ち上げる中で実践している例を紹介します。
脳とAIについては、前提となる基礎知識を説明した後に、Deep Mindによる最新の強化学習の研究を紹介し、さいごに応用例としてハイプサイクルの仕組みを強化学習で読み解きます。
僕は、経営学、脳科学、AIの研究者ではありませんが、それぞれの領域をふらりと渡り歩く者として、「事前の専門知識がなくてもコレを読めばだいたい分かる」というnoteを目指してみます。
学習する組織〜暗黙知と形式知
「組織は絶えず変化しなければならない」と経営学者ピーター・ドラッガー氏は述べています。変化するためには、組織として「学習」していく必要があり、システム思考などの重要性が説かれています(Senge, P.M. 1990)。
その学習によって、組織は知識を創造していきます。知識には、大きく2つの種類があります(Polanyi, 1966)。
暗黙知:特定の状況に関する個人的な知識
形式知:形式的・論理的言語によって伝達できる知識
その知識を組織で発展させるには、4つの知識変換モードが必要なようです(Nonaka, 1996)。
共同化:個人の暗黙知→チームの暗黙知
表出化:チームの暗黙知→個別の形式知
連結化:個別の形式知→体系的な形式知
内面化:体系的な形式知→個人の暗黙知
これらの4つの知識変換を繰り返すことで、知識創造のスパイラルが形成されます。では、LINEにおけるAI事業LINE BRAINを立ち上げたケースで具体的に考えてみましょう。
1. 共同化
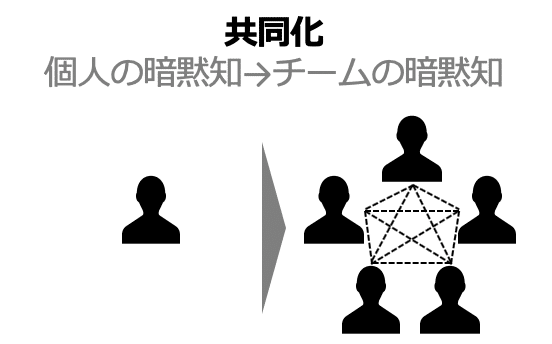
経験を共有することによって、メンタル・モデルやスキルなどの暗黙知を創造します(Cannon Bowers, 1993)。
LINE BRAINでは、ワークショップを開催したり、雑談することで、僕自身のAI業界での経験や知識を共有したり、各チームのAI研究者の最新研究や興味・関心などを引き出しました。そうやって、新たな発見をしたり、同じゴールを目指す土台作りをします。
個人的には、お茶や食事をしながらリラックスした状態での雑談が重要だと考えており、そのための美味しいお店リストを常に更新しています。
2. 表出化
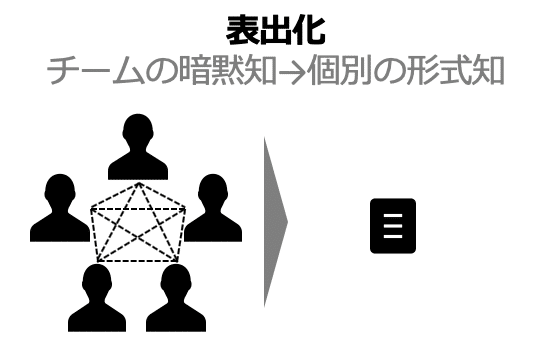
暗黙知を明確なコンセプトに表します。書くということが、暗黙知を形式知に変換します(Emig, 1983)。表出化では、よく非分析的な方法として、メタファーやアナロジーが使われます。
LINE BRAINでは、コンセプトを作るためにアナロジーを利用しました。まだ事業名も決まっていない時、最近のAI技術が脳の仕組みであるニューラルネットワークを模しており、また、LINEの各種サービスを最適化する頭脳として活用されているため、「LINE BRAIN」と名付けました。
また、LINEのミッションとして「CLOSING THE DISTANCE」というヒトとヒトや、ヒトとモノの距離を縮めるというコンセプトがあり、そこから連想して、AIのB2B事業を表現する「CLOSING THE DISTANCE BETWEEN AI AND BUSINESS」というミッションを定めました。
3. 連結化
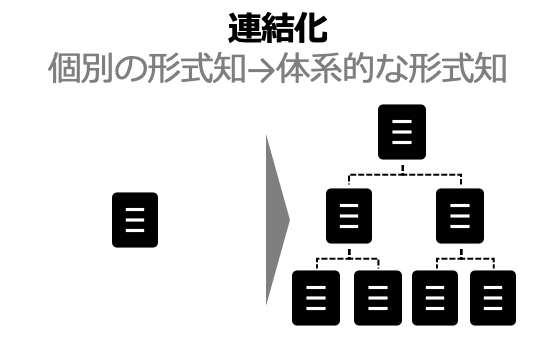
コンセプトを組み合わせて、一つの知識体系を創り出します。さまざまな情報・知識をつなぎ合わせて、整理・分析しながら、新しい知識を生み出します。
LINE BRAINでは、画像(OCR, 顔認識, 物体認識, 動画分析)・音声(音声認識, 音声合成)・テキスト(チャットボット , 自然言語理解)という技術領域の横軸と、事業・プロダクト・AIエンジンというビジネス階層の縦軸でマトリックスを作り、各領域をさらに深掘りました。
例えば、OCRという技術領域では、AIエンジンとして世界最高レベルだと分かったので、事業として市場規模はどれくらいで潜在顧客はどにいるか、プロダクトしてどうパッケージすれば市場にフィットするかなどを検討しました。
より具体的には、社内のwikiで情報をツリー状に階層化・整理して、知識を体系化しています。
4. 内面化
形式知を暗黙知に体化します。行動による学習と密接に関連しているようです。
LINE BRAINでは、メンバー個人に大きな裁量を与えて、個人が行動して暗黙知を獲得できるようにしています。
例えば、顧客を訪問してニーズを聞いたり、プロトタイプを開発してニーズを検証したり、実データでAIエンジンの精度を評価する中で、新たな知識が創出されています。
組織と脳の関係
では、学習する組織と個人の脳には、どのような関係があるでしょう?
組織論における形式知・暗黙知は、脳科学における陳述記憶・非陳述記憶にマッピングできそうです(Ray, 2020)。

陳述記憶は、言語で記述できる記憶です。特定の時間と場所で起きたイベントについてのエピソード記憶、時間や場所に依存しない事実や知識の意味記憶があります。これらの記憶は、まず海馬で作られ、徐々に高次の大脳皮質に広がっていくようです。
一方、非陳述記憶は、言語で表現できない記憶です。自転車の運転の仕方を体で覚えるような手続き記憶などがあります。手続き記憶は、直観を生む大脳基底核や運動を制御する小脳が関わっているようです。
さて、組織論における形式知・暗黙知との関係として、陳述記憶は暗黙知から形式知へと変換されるのに対し、非陳述記憶は暗黙知のままだと考えられます。
例えば、職人技は言葉で説明するのが難しく「見て盗む」必要があるのは、その技が非陳述記憶だからであり、その知識を継承するためにOJT (On-the-Job Training)等が必要なのかもしれません。
学習する脳〜3つの方式
では、個人の脳において、学習はどのようにおこなわれるのでしょう?
脳には、3つの学習方式があるようです(K. Doya, 1999)。
1. ヘブ学習または教師なし学習(海馬・大脳皮質)
2. フィードバック誤差学習または教師あり学習(小脳)
3. 強化学習(大脳基底核)
1. ヘブ学習
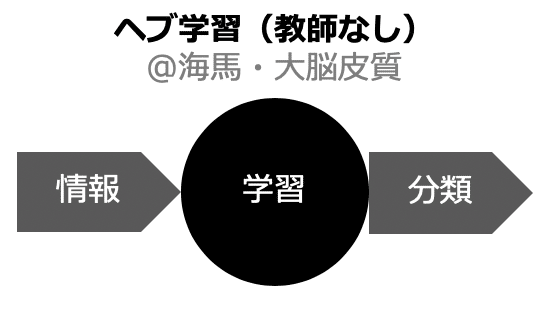
ヘブ学習は、同時に起こる事象をリンクして記憶します。心理学者のドナルド・ヘブ氏が、「細胞Aと細胞Bが同時に活動するとき、細胞AB間のシナプスが強化される」と論じたことが由来です。同時に発火(Fire)すると結合(Wire)ができるので、「Fire and Wire理論」とも呼ばれます。
さまざまな記憶の中から、ある繋がりに気づき、新しいパターンを発見した時のアハ体験は、このヘブ学習だと考えられます。
例えば、「リンゴ」からの連想で、「果物」を思いつくか、産地の「青森」や企業の「Apple」を思い浮かべるかは、人それぞれのシナプスの強度によるのでしょう。
2. フィードバック誤差学習
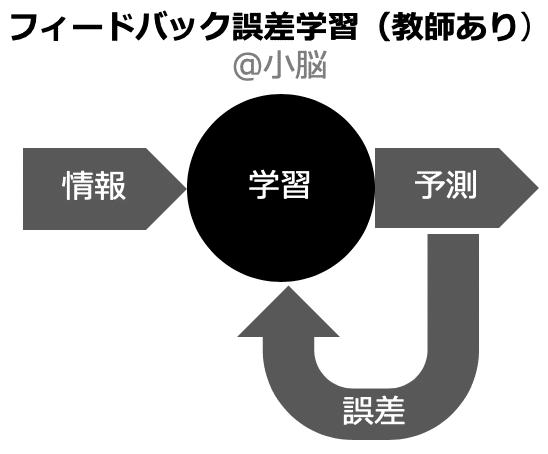
フィードバック誤差学習は、自分の予測と実際の現象の誤差を小さくすることで、予測の精度を上げられるように、身体や環境の脳内モデルを作っていきます。
自分の予測が当たった時のアハ体験は、このフィードバック誤差学習だと考えられます。
3. 強化学習
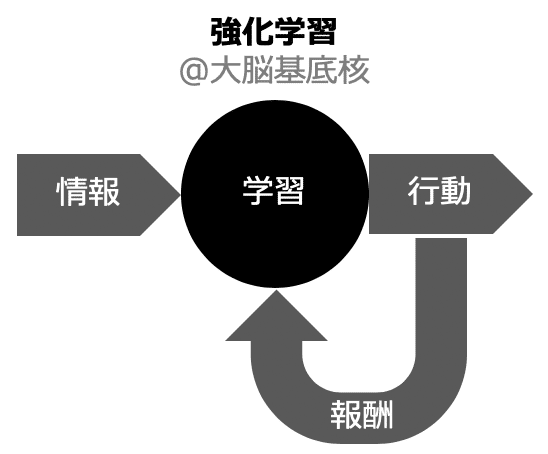
強化学習は、行動によって得られる報酬について、将来得られる報酬の合計を最大化できるよう、適切な行動即を作っていきます。
ある状況の価値を適切に判断して行動即を学び、うまくいくことが多くなったと感じる体験は、強化学習だと考えられます。
例えば、囲碁や将棋のプロ棋士の直観的な思考は、強化学習のようです(ひらめきなどの「直感」とは異なる)。脳活動をfMRIで調べたところ、次の一手を決めるときは、大脳基底核が活発に活動していたようです(X. Wan, et all, 2011)。
熟考する時間を与えて、論理的に思考させると、プロ棋士とアマ棋士で正答率も脳の活動パターンもほぼ同等であり、大脳基底核はあまり活動しない。
しかし、制限時間を1秒にして、じっくり考える暇を与えないと、プロ棋士の方がアマ棋士より正答率が高くなり、大脳基底核の活動が活発になる。さらに、広範囲の大脳皮質が大脳基底核と相関した活動をしており、これは広範囲の大脳皮質に散在する情報を大脳基底核に統合して、行動を選択していると考えられる。
脳とAIの関係
では、脳における学習と、AIの学習には、どのような関係があるでしょう?
例えば、囲碁AIは、2016年3月に世界トップレベルの棋士イ・セドル氏に勝ち越し、2017年5月に世界最強とされる棋士カケツ氏に全勝しました。実は、その囲碁AIは、プロ棋士の直観的な思考である強化学習を、Deep Q-Networkという強化学習のアルゴリズムで実現しているようです。これは、脳とAIの近い関係を予感させます。
脳とAIの関係を考えるために、3つの階層に分けてみます(Marr, 1982)。

1. 計算理論
脳が計算で果たすべき目的は何か、そして、外界の物理的な拘束条件が与えられたときに、その目的を果たすためにはどのような計算が必要かを考えます。
強化学習を例にします。動物がある実験課題を与えられて、課題に成功すればジュースなどの報酬をもらえるとします。報酬を得るために、動物は労力を払わなければなりませんが、将来もらえる報酬を最大化するように行動を学習すると仮定します。このように、動物の行動学習を「報酬最大化問題」として設定することが、計算理論のレベルです。
2. 表現とアルゴリズム
計算理論のレベルで定められた計算を遂行するには、どのような表現を用いるべきか、また、その表現のもとで具体的な計算方法(アルゴリズム)は何かを考えます。
また、強化学習を例にします。先ほどの報酬最大化問題は、理論上は無限未来の報酬を計算する必要があり、学習にかかる時間とコストが大きくなり過ぎます。動物がそのような計算をおこなっているとは考えにくいです。そこで、時間差分(Tempral Difference: TD)誤差という計算方法を導入することで、計算量を減らします。このTD誤差の考え方は、無限未来の積分計算を、局所的な微分によって計算するようなイメージです。
3. 実装
表現・アルゴリズムのレベルで定められた具体的な計算方法を、ハードウェア(神経細胞やコンピューター)上で実現するにはどのようにすればよいか考えます。
またまた、強化学習を例にします。先ほどのTD誤差が、神経細胞や神経回路でのように実装されているかを理解する必要があります。実際、大脳基底核ドーパミン細胞がTD誤差信号を表現していると、サルの実験で発見されています(Schultz et all., 1997)。詳しく見てみましょう。
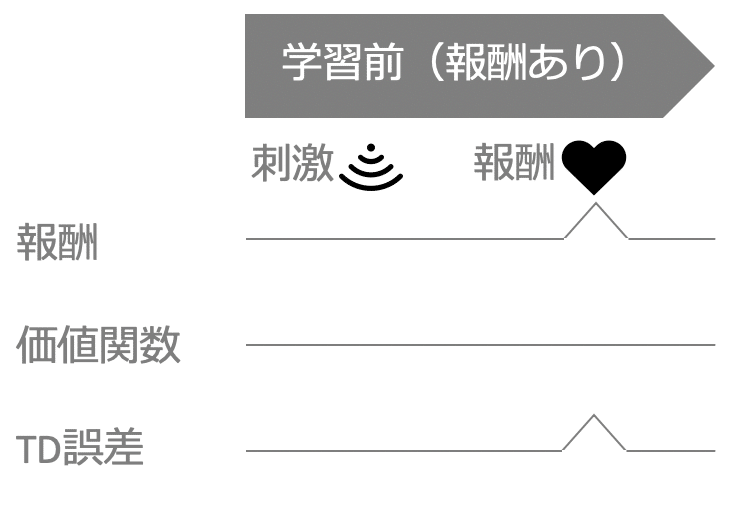
まず、サルに視覚的な刺激を提示して、その後に、報酬としてジュースを与えます。サルは予想外の報酬に反応して、TD誤差に相当するドーパミンが活性化します。
そして、刺激が提示されると報酬が与えられることを学習します。

学習後、刺激が提示されただけで、その状況の価値(価値関数)が高いと判断し、TD誤差に相当するドーパミンが活性化します。その後、報酬が与えられても、それは期待通りの結果であり、TD誤差に相当するドーパミンは活性化しないです。
例えば、行きつけのレストランで、メニューを読む刺激が幸せで、実際に食べる報酬は期待通りの結果を確認する行為なのかもしれません。
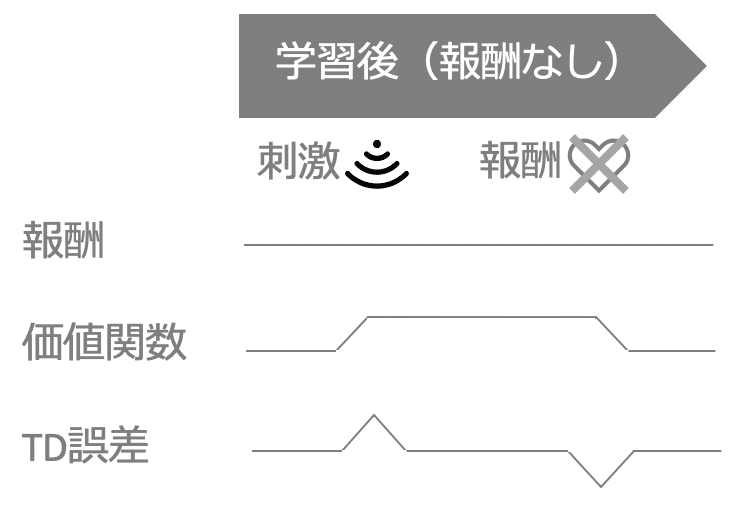
学習後、刺激が提示されたにも関わらず、報酬が与えられないと最悪です。TD誤差に相当するドーパミンは、逆に抑制されてしまいます。
例えば、行きつけのレストランで、お気に入りのメニューを選んだのに味が落ちていると、失望の淵に追いやられるような感じでしょうか。
このように、脳の仕組みと、強化学習というAIに活用されるアルゴリズムが近い関係であることが解明されました。
ただし、全てのAIが脳の仕組みと同じわけではありません。例えば、ディープラーニング(深層学習)というAIのアルゴリズムでは、確率的勾配降下法(または誤差逆伝搬法)という計算の工夫をしますが、そのような脳の仕組みは見つかっておらず、人工的な学習方式のようです。(参考:数理モデルでつなげる脳の仕組み)
学習するAI〜最新の強化学習
では、学習にまつわる最新のAI研究はどこまで進んでいるでしょう?
世界トップ棋士に勝利した囲碁AIは、さらに進化を遂げています。囲碁AIのベースである強化学習AIは、「アタリ」というゲームにも挑戦していますが、そのスコアが年々上昇しています。

その大きな飛躍の要因が、従来の強化学習(Classic Deep RL)と異なる、報酬が確率的に分布しているとことを考慮した新しい強化学習(Distributional RL)です。
囲碁AIが世界トップ棋士に勝利したのは2016-2017年であり、従来の強化学習だったと思われますが、もし新しい強化学習を適用すると、さらに強い囲碁AIが生まれそうです。
さて、最新の強化学習のAIは、ゲームに強いだけではありません。マウスの脳内のドーパミンの仕組みをうまく説明できることが分かりました。

従来の強化学習のTD誤差(Classical TD)に比べると、新しい強化学習のTD誤差(Distributional TD)の方が、マウスのドーパミン細胞のデータ(Neural data)に近いことが分かります。
このように、AIの開発を進めることにより、逆に脳の仕組みが明らかになることは、計算論的神経科学という領域を切り開いていきそうです。
強化学習の応用例〜ハイプサイクルを読み解く
では、強化学習の仕組みが分かると、どのような応用ができるでしょう?
社会現象を説明できると面白そうです。
例えば、先進技術が社会に広がっていく現象は、黎明期→過度な期待のピーク期→幻滅期→啓蒙活動期→生産性の安定期という「パイプ・サイクル」になるようです。

ちなみに、2019年の先進技術のハイプサイクルでは、敵対的生成ネットワーク(通称GANというAIアルゴリズムの一種)は黎明期、AI PaaSや5Gが過度な期待のピーク期のようです。
このハイプサイクルは、社会の期待の移り変わりを表しており、「社会による学習」というものを強化学習で説明できるかもしれません(Ray, 2020)。
黎明期:新技術のキーワードをたまに目にして(刺激)、最新の研究結果を聞いたりする(報酬)
過度な期待のピーク期:新技術のバズワードをよく目にして(刺激)、象徴的なショーケースを知る(報酬)
幻滅期:一部の人たちが新技術を採用するも(刺激)、技術を応用した期待通りの成果が得られない(報酬なし)
啓蒙活動期:新技術はもはや普及技術として紹介され(刺激)、期待値が低い分だけ技術採用の成果に満足する(報酬)
生産性の安定期:新技術の話題はあまり出ず(刺激なし)、技術採用の成果も当たり前のものとなる(報酬なし)
さいごに
「学習」をテーマに、組織経営というマクロから、脳やAIというミクロまでを旅してきました。
かなり時間を掛けて執筆したので、もし面白いと感じたならスキボタン♡を押していただけると、その報酬で強化学習して、次回の執筆も頑張れると思います。
今回は、初回のnoteで提唱したSTADのフレームワークを元に、学習する組織のデザイン(D)、学習する脳のサイエンス(S)、学習するAIのテクノロジー(T)を横断して、「学習」というものを捉えてみました。
今回のnoteに興味を持ち、より詳しく学びたい方は、下記の書籍や記事をご参考ください。
いただいたサポートは、note執筆の調査費等に利用させていただきます