
新人オンコール担当者への引き継ぎ資料:あるいはシステム障害時のノウハウメモ

こんにちは、くふうAIスタジオの@0tanyです。トクバイサービス のSREを担当しています。
私は長らくオンコールローテーションに参加していましたが、この度、体制変更によりオンコール対応から離れることになりました。
この記事は、新たにオンコールを担当する新人への引き継ぎ資料をベースに社外向けに再構成したものです。対応に役立つ実践的な知識も含めているので、現場で役立つヒントを見つけていただければ幸いです。
1. オンコール対応とはなんぞや?
トクバイでは複数の監視システムよりアラート(あるいはPager)を発報させています。主たる監視システムは Grafana(+Prometheus) / CloudwatchAlarm / StatusCake です。
監視アラートは以下のような状態を早期に検知させるためのもので、これらの状態に対する調査・対処を行うのがオンコール対応です。
システムに問題が発生し、正常な動作を維持できなくなっている状態
ユーザーが正常にサービスを利用できない状態
2. オンコール対応、あるいはシステム障害に対する全体プロセス
オンコール対応における全体プロセスは以下の通りです。
1. 状況確認
受信したアラートや検知された事象の内容を迅速に確認・把握する。
システム全体にどの程度の影響が及んでいるか、あるいは、アラートが誤検知であるかどうかの判断も含まれる。
2. 影響調査
検知された事象がサービスに与えるリスクを評価する。
サービス全体に影響を与えるのか、一部の機能だけなのか、ユーザーへの影響範囲とその深刻度を迅速に判断し、対応の優先順位を決定する。
影響範囲が所定のレベルを超えていた場合、関係部署へのエスカレーションを行う。
3. 原因調査
事象の根本原因を特定する。
アプリケーションやインフラ、関連するサブシステムや外部サービスのいずれが問題の原因なのか、問題解決のための情報を調査・収集する。
4. 復旧対応(暫定対応含む)
問題を解決し、サービスを正常状態に戻すための対応を実施する。
必要に応じてアプリケーションの実装やインフラの環境構成を変更することもあり得る。
また、迅速な復旧が難しい場合は、暫定的な対応策を講じ、被害を最小限に抑える処置を行う。
5. 恒久対応
復旧対応が一時的なものであった場合、問題の再発を防ぐための恒久的な処置を実施する。
6. 障害分析・再発防止策
障害発生時の対応を振り返り、発生原因や対応プロセスを詳細に分析し、ポストモーテムに取りまとめる。
ここで得られた教訓をチーム全体で共有し、再発防止策を講じることで次回の障害対応に活かす。
また、振り返りの結果をもとにシステムやプロセス全体の改善を行う。
3. オンコール担当者としてあなたに知っておいてほしいこと
3.1 オンコール対応時に意識してほしいこと
オンコール対応時の心構え
システム障害対応の最も重要な目的はシステム自体を直すことではなく、以下の2点を達成することです。
発生しているユーザーへの影響がこれ以上拡大しないよう、被害を最小限に抑えること。
影響を受けているユーザーに対して、できる限り早期にサービスを復旧させること。
復旧を目指す上で、必ずしも原因調査やシステムの復旧作業そのものが最優先になり得ないケースもあります。
例えばユーザー・顧客へのアナウンスや、サービスのメンテナンスモードへの移行、バッチ処理やサブシステムの一時的な停止等、サービス全体を復旧させるまでのプロセスにおいて優先して行わなければいけないことは様々です。また、復旧のゴールもシステムを元の状態に戻すのがゴールとなるのか、あるいは緊急で新たな修正を加えるべきなのか、臨機応変に対応する必要があります。
これらの対応を実施する上で、明らかに自分の手に余る場合、関連部署や上長に遠慮なくエスカレーションしてください。
ランブックの活用
トクバイサービスのオンコール時には、オンコール対応の手順やガイドラインを記載した"ランブック(通称アラート対応ガイド)"が用意されています。まずは落ち着いてランブックを参照しつつ対応を進めてください。
3.2 調査TIPS
ここではランブックに記載のないシステム障害、あるいはインシデントに遭遇した時の、トクバイシステムの歩き方をTIPS的にまとめます。
メトリクスの調査(CloudWatch)
トクバイサービスはAWSを基盤としているので、基本的なメトリクスはCloudWatchMetrics上に存在します。新たにシステム構築をした際、関連するシステム系統の主要メトリクスをCloudWatchDashboardに事前に集約しておく等の対応をしておくと後々の運用時に便利です。
トクバイサービスではAWS ECSで稼働しているシステムが多く存在しますが、ECSタスク単位の詳細なメトリクスはContainerInsightsにより出力されるパフォーマンスログデータをビジュアライズする必要があります。具体的には以下のようなクエリをCloudWatchLogsのLogs Insightsで実行してください。
ロググループに/aws/ecs/containerinsights/{ECSクラスタ名}/performanceを選択
CPU使用率を確認したい場合のクエリ例。以下のクエリを実行して可視化(Visualize)タブを選択
fields @timestamp, CpuUtilized, CpuReserved
| filter ispresent(ContainerName)
and ContainerName like /app/
and Type = "Container"
and TaskId = "{ECSタスクID}"
| stats avg(CpuUtilized / CpuReserved * 100) as AvgCpuUtilization by bin(1m)
| sort @timestamp descメモリ使用率を確認したい場合のクエリ例。以下のクエリを実行して可視化(Visualize)タブを選択
fields @timestamp, MemoryUtilized, MemoryReserved
| filter ispresent(ContainerName)
and ContainerName like /app/
and Type = "Container"
and TaskId = "{ECSタスクID}"
| stats avg(MemoryUtilized / MemoryReserved * 100) as AvgMemoryUtilization by bin(1m)
| sort @timestamp desc以下はECS Fargate上で実行されたとあるバッチアプリケーションのCPU使用率の画像例です
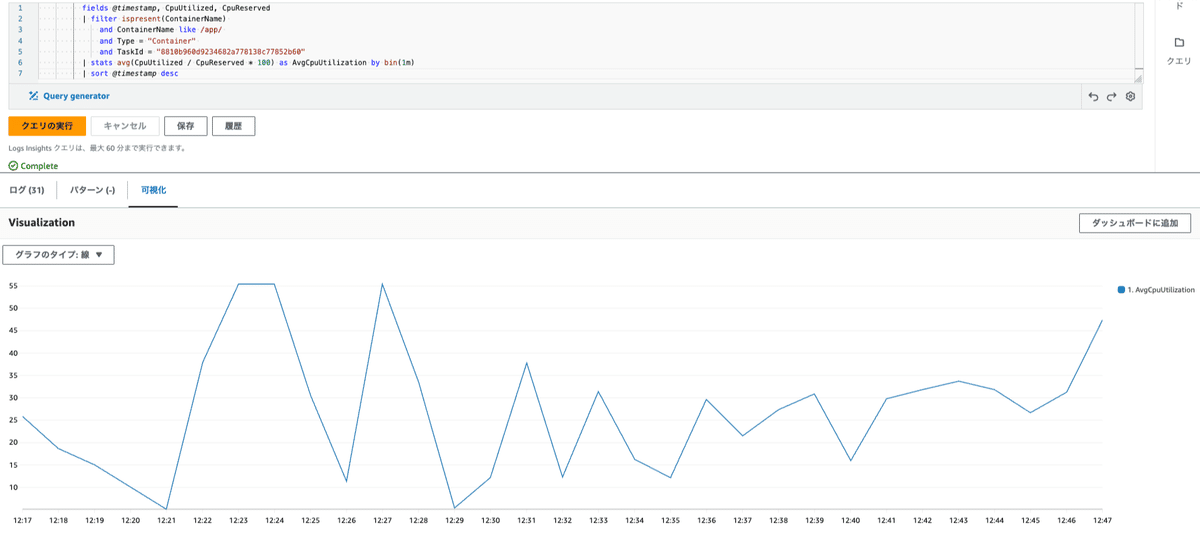
あるいは、ContainerInsights用の以下のようなカスタムダッシュボード等も存在するようです。
https://github.com/mreferre/container-insights-custom-dashboards
メトリクスの調査(その他のメトリクス)
Kibana(OpenSearch)
Nginxのアクセスログ情報を集積しており、ELBのCloudWatchMetricsと比較して以下のメトリクスをビジュアライズしています。
Pathベースでの分析メトリクス
ソースIPベースでの5xx分析メトリクス
Grafana/Prometheus
インスタンス上のメトリクスを node_exporter で収集し、Grafanaで可視化しています。
CloudWatchで収集していないDisk Usage/IO、iNode Usage、ProcessCount等の値を収集しています。
エラートラッキングデータの調査
Sentry
トクバイではエラートラッキングにSentryを利用しています。
また、Sentryのデータを定期的にRedshiftにエクスポートし、Redashで可視化しています。
システムログデータの調査
トクバイサービスではECSコンテナのシステムログ、AWSサービスのイベントログ、EC2インスタンスのログを収集し、S3に格納しています。S3にログを集約することでコストを抑えつつ統合的にAthenaでログ検索を実行できるようにしています。
ECSコンテナのログの場合
例えばECSコンテナのメインアプリケーションやサイドカーアプリケーションのテーブル定義は以下のようになっています。
CREATE EXTERNAL TABLE `ECSクラスタ名_ECSサービス名_app`(
`log` varchar(65535) COMMENT 'from deserializer',
`container_id` varchar(65535) COMMENT 'from deserializer',
`container_name` varchar(65535) COMMENT 'from deserializer',
`source` varchar(65535) COMMENT 'from deserializer',
`ec2_instance_id` varchar(65535) COMMENT 'from deserializer',
`ecs_cluster` varchar(65535) COMMENT 'from deserializer',
`ecs_task_arn` varchar(65535) COMMENT 'from deserializer',
`ecs_task_definition` varchar(65535) COMMENT 'from deserializer',
`service_name` varchar(65535) COMMENT 'from deserializer',
`fluentd_time` bigint COMMENT 'from deserializer')
PARTITIONED BY (
`dt` string,
`hh` string)
ROW FORMAT SERDE
'org.openx.data.jsonserde.JsonSerDe'
WITH SERDEPROPERTIES (
'case.insensitive'='TRUE',
'dots.in.keys'='FALSE',
'ignore.malformed.json'='FALSE',
'mapping'='TRUE')
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
's3://ログ集約バケット名/container_logs/ECSクラスタ名/ECSサービス名/app'
TBLPROPERTIES (
'classification'='json',
'projection.dt.format'='yyyy-MM-dd',
'projection.dt.interval'='1',
'projection.dt.interval.unit'='DAYS',
'projection.dt.range'='NOW-3MONTH,NOW+1MONTH',
'projection.dt.type'='date',
'projection.enabled'='true',
'projection.hh.digits'='2',
'projection.hh.interval'='1',
'projection.hh.range'='0,23',
'projection.hh.type'='integer',
'storage.location.template'='s3://{ログ集約バケット名}/container_logs/ECSクラスタ名/ECSサービス名/app/dt=${dt}/h=${hh}',
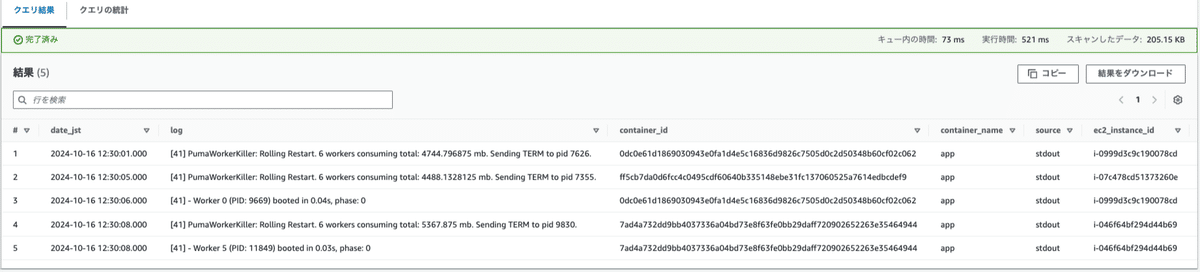
'transient_lastDdlTime'='1729005520')ログ検索時のクエリは以下のような感じです。※fluentd_time=unixtimeです。
SELECT
from_unixtime(fluentd_time + 3600*9) as date_jst,
*
FROM "ECSクラスタ名_ECSサービス名_app"
WHERE dt='2024-10-16' AND hh='12'
AND from_unixtime(fluentd_time) >= CAST('2024-10-16 12:30:00 +09:00' as timestamp)
AND from_unixtime(fluentd_time) < CAST('2024-10-16 12:30:10 +09:00' as timestamp)
ORDER BY fluentd_time;以下のような実行結果となります。
ELBログの場合
ELBログの検索も似たような感覚です。例えばELBに登録されているターゲットの中で50xエラーが多発しているターゲットを特定するクエリは以下のような形式です。
ELBログのAthenaによるクエリ検索はインターネット上に知見が多数あるので、ChatGPTに条件を指定してクエリを生成してもらった方が効率的かもしれません。
SELECT
target_ip,
COUNT(*) AS target_50x_count
FROM
{DB名}.{ELBログテーブル名}
WHERE
target_status_code like '50%'
AND dt = '2024/10/16'
AND from_iso8601_timestamp(time) BETWEEN from_iso8601_timestamp('2024-10-16T03:10:00Z')
AND from_iso8601_timestamp('2024-10-16T03:30:00Z')
GROUP BY
target_ip
ORDER BY
target_50x_count DESC;CloudTrail(監査ログ)の場合
CloudTrailのログ検索もELBのログ検索と同様のイメージ。障害に関連するAWSリソース、IAMロール、障害に関連しそうなAWSアクションについてフィルタをかけ、システム障害に関連する監査ログが存在しないか調査してください。
CloudTrailのログ検索は一般公開されている情報が多数あるので、そちらを参照してください。クエリについては割愛させていただきます🙏
https://repost.aws/ja/knowledge-center/athena-tables-search-cloudtrail-logs
インスタンス内部の調査
EC2インスタンス内部の調査が必要になるケースもあります。ここでは、障害対応時に有用となるコマンドや情報をリストアップしています。適切にこれらを活用し、迅速な原因特定と復旧に役立ててください。
プロセス確認
システム上で動作しているプロセスの確認や、問題のあるプロセスの特定に使用します。
`ps auxf` : プロセスツリー形式でプロセスを一覧表示します。
`top` / `htop` : プロセスのCPUやメモリ使用状況をリアルタイムで監視します。
`pgrep -fl {プロセス名}` : 特定のプロセスが実行されているか確認します。ネットワーク状態の確認
ネットワークの接続状態やアクティブなポートの確認に使用します。
`ip a` : ネットワークインターフェイスとその状態を確認します。
`ss -pantu` : 現在接続中のポートや通信状況を確認します。
`netstat -tuln` : リスニング状態のポートを確認します(`ss`と同様ですが、古いシステム向けです)。ディスク使用状況の確認
ディスク容量やファイルシステムの状況を確認し、ディスク消費量の多いディレクトリやファイルを特定するためのコマンドです。
`df -h` : ファイルシステムのディスク使用量を表示します。
`du -sh {パス}` : 指定したディレクトリやファイルのディスク使用量を表示します。
`du -sh * | sort -rh | head -n 10` : サイズ順に上位10件のディレクトリやファイルを表示します。
`find / -type f -size +500M` : 500MB以上の大きなファイルを特定します。ログの調査
問題の発生に関連するログを調査することは、根本原因を特定するうえで非常に重要です。
`journalctl -u {サービス名}` : systemd管理下のサービスログを確認します。
`/var/log/`配下 : システムやアプリケーションのログが格納されているディレクトリです。
`tail -f /var/log/{ログファイル名}` : 特定のログファイルをリアルタイムで監視します。メモリ使用状況の確認
システムのメモリ消費状況を把握し、メモリリークやスワップの発生を調査するために使用します。
`free -h` : メモリの使用状況を確認します。
`vmstat 1 5` : メモリ、CPU、I/Oのパフォーマンスを確認します。設定ファイルの確認
サービスやミドルウェアの設定ファイルを確認し、設定ミスや不整合がないかを調べます。
`/etc/{ミドルウェア名}/` : ミドルウェアごとの設定ファイルが格納されています。
`grep -i {検索語} /etc/{ミドルウェア名}/{ファイル}` : 設定ファイル内の特定のキーワードを検索します。ファイル/プロセスのオープン状態の確認
問題のプロセスが開いているファイルやポートを確認します。
`lsof -p {プロセスID}` : 指定したプロセスがオープンしているファイルやソケットを確認します。
`lsof +D {ディレクトリ}` : 特定のディレクトリ内で開いているファイルを確認します。システムコールの追跡
プロセスが実行しているシステムコールをリアルタイムで追跡し、問題の原因を探ります。
`strace -p {プロセスID}` : プロセスのシステムコールを監視して詳細な動作を確認します。ワンライナー例
`dmesg | grep -i error` : カーネルメッセージからエラーを抽出します。
`ss -tulwn | grep LISTEN` : リスニング中のTCP/UDPポートを確認します。
`find / -type f -mtime -1` : 過去24時間以内に変更されたファイルを確認します。サポートケースに問い合わせる
AWSサポートケースにて問い合わせるにあたってAWSから問い合わせにおけるガイドラインが公開されています。
AWSサポートケースには緊急度レベルと応答時間がSLOとして定められています。完全に個人的な肌感覚と偏見ですが、ガイドラインに沿った問い合わせの方がそうでないものに比べて早く対応して貰えるような気がします。問い合わせの際はガイドラインに沿った丁寧な問い合わせを心がけましょう。
AWSサポートケース発行にあたっての問い合わせテンプレートは以下の通りです。
件名: [サービス名] [具体的な問題の簡潔な説明]
1. 問題の概要
[問題の簡潔な説明と、ビジネスへの影響を記載]
2. 環境情報
- AWS アカウント ID: [アカウントID]
- リージョン: [リージョン名]
- 影響を受けているリソース:
- [リソースタイプ]: [リソース名/ID]
- [リソースタイプ]: [リソース名/ID]
3. 問題の詳細
- 発生日時: [YYYY-MM-DD HH:MM:SS] (タイムゾーン: [タイムゾーン])
- 再現性: [常時 / 断続的 / 一度のみ]
- 影響範囲: [全ユーザー / 特定のユーザーグループ / 特定の機能]
4. 発生した事象
[具体的に観察された症状や動作、エラーメッセージを記載]
5. 期待される動作
[正常時に期待される動作を記載]
6. 実施済みのトラブルシューティング
- [実施した対応策1]
- [実施した対応策2]
7. 関連ログやエラーメッセージ
[関連するログやエラーメッセージを記載。長文の場合は添付ファイルとして提供]
8. 質問事項
1. [具体的な質問1]
2. [具体的な質問2]
9. 緊急度
[低 / 通常 / 高 / 緊急]
理由: [緊急度の理由を簡潔に説明]
添付ファイル:
- [関連するスクリーンショットやログファイルのリスト]
ご確認とご支援をよろしくお願いいたします。AIの力を借りる
くふうカンパニーグループでは chatbot-ui を利用した社内ChatGPT環境を整備しています。
AWSサポートに問い合わせた内容をそのまま社内ChatGPTに問い合わせるだけでも何らか有用なヒントを得ることができるかも知れません。
4. 終わりに
実はこの記事ですが、本来インシデントレスポンスからポストモーテムまでのテーマで重厚壮大な記事(もとい引き継ぎ資料)を書こうと考えていました。しかし、そのレベルまで全然辿り着かなさそうだったため、局所的にオンコールを取り扱わさせていただきました。
オンコール対応はインシデントレスポンス、あるいはインシデント管理・問題管理プロセスの中のごく一部の側面に過ぎません。
信頼性の向上を追求していくには、一つ一つの対応をただのシステム障害対応で終わらせるのではなく、対応の過程で得られた教訓をチームで共有し、システムの改善や運用の最適化に繋げていくことが求められます。
効果的なインシデントレスポンスプロセスの設計や、そもそものシステム障害(あるいはインシデント)を削減するための効果的なポストモーテム運用などについては以下の書籍に譲ることとします。
SRE サイトリライアビリティエンジニアリングhttps://www.oreilly.co.jp/books/9784873117911/

システム運用アンチパターン
https://www.oreilly.co.jp/books/9784873119847/

くふうAIスタジオでは、採用活動を行っています。
当社は「AX で 暮らしに ひらめきを」をビジョンに、2023年7月に設立されました。 (AX=AI eXperience(UI/UX における AI/AX)とAI Transformation(DX におけるAX)の意味を持つ当社が唱えた造語) くふうカンパニーグループのサービスの企画開発運用を主な事業とし、非エンジニアさえも当たり前にAIを使いこなせるよう、積極的なAI利活用を推進しています。 (サービスの一例:累計DL数1,000万以上の家計簿アプリ「Zaim」、月間利用者数1,600万人のチラシアプリ「トクバイ」等) AXを活用した未来を一緒に作っていく仲間を募集中です。 ご興味がございましたら、以下からカジュアル面談のお申込みやご応募等お気軽にお問合せください。 https://open.talentio.com/r/1/c/kufu-ai-studio/homes/3849