マッキンゼーのレポートに見る企業応用を促進する大規模言語モデルの評価方法

2023 年に大規模言語モデルは多数発表されていますが、どれを選べばよいかは依然として曖昧です。その理由の一つにユースケースと評価方法のミスマッチがあると考えています。例えば、営業メールの草案を生成するモデルを選ぶとき、質問回答データセットの評価結果がどれだけ意味があるかは不透明です。誰かにメールを書いてもらいたいとき、東海道新幹線の速度について知っていることを基準にするか ? という話です。
本記事では、マッキンゼーが公開した The state of AI in 2023 から生成系 AI の企業利用が盛んな領域について示唆を得て、大規模言語モデル評価の方向性を提案します。日本の AI 導入効果は米国の 7 分の 1 程度しかないといわれており、生成系 AI のインパクトは限定的になると見込んでいます。生成系 AI の応用を加速するにはカスタマイズが必要な汎用モデルだけでなく、ユースケースに特化したモデルも作成していく必要があります。評価方法を定めることは、その第一歩になると思います。
トップの画像は SynLLOER さんの Evaluation を使わせていただきました
生成系 AI のインパクトが大きいのは営業、サービス開発、運用
表題そのままの図が The state of AI in 2023 で示されています。本レポートは 2023 年 4 月に行われた調査をもとにしており、米国だけでなくアジア、世ヨーロッパの企業も含まれます。そのため、一地域に限った傾向の可能性は低くなっています。

この結果は参照先のレポート 「The economic potential of generative AI: The next productivity frontier」が報告しているインパクトが高い領域とも一致します。

生成系 AI の応用はまだまだ広がる余地があるとも言えますが、効果のある手堅い領域は限られているとも言えます。その証左に、 AI を適用している業務の数 1~2 が多く、 3~5 へのシフトはそれほど増えていません。

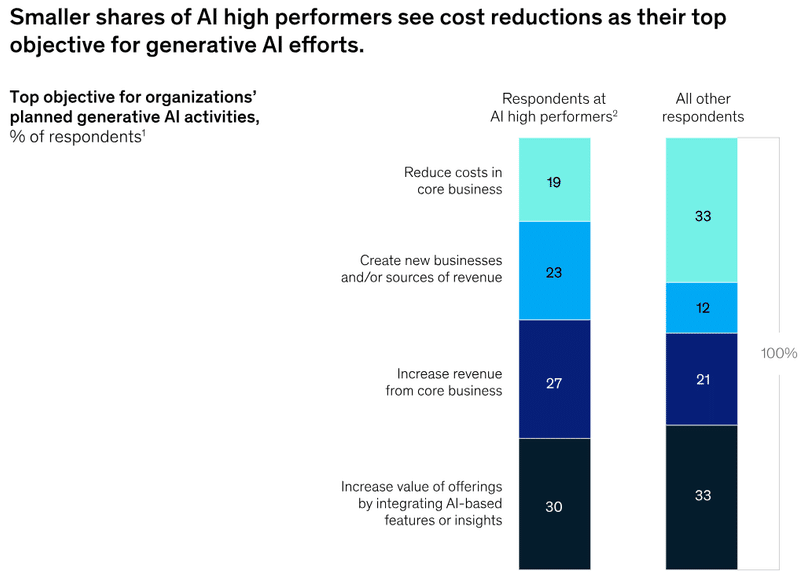
利益 (EBIT) の 20% を AI から創出している企業は、コスト削減より新規ビジネスの創出や利益の拡大に使用しているとの回答があります。営業、サービス開発、運用においても、単にそれにかかる人員を削減するのでなく利益が得られる機会を拡大するために使うことが肝要といえます。
GitHub で公開されている ML Enablement Workshop では、事例の調査をもとにビジネスモデルキャンバスを使って利益創出につながるユースケースを発見するようガイドしています。この進め方はレポートが示唆する点と合致しており、生成系 AI においても効果的と感じました。
レポートからの示唆として、大規模言語モデルの応用は営業・サービス開発・運用における利益創出のユースケースが有力です。そのため、モデルの評価はこれらのユースケースに沿い行われていることが「産業的には」重要になります。※もちろん、この観点は学術的な評価とは一致しない点に注意が必要です。
大規模言語モデル評価の問題点
産業的な観点から見ると、現在の大規模言語モデルの評価はユースケースと評価方法が一致していない点で問題です。たとえば、「営業機会拡大のため顧客データベースの情報を参照しパーソナライズしたメール文の素案を生成する」というユースケースがあったとします。現在代表的な大規模言語モデルの評価は Stability AI の JP Language Model Evaluation Harness 、 Weights & Biases の Nejumi Leaderboard 、東京大学 Sam Passaglia さんが主導する YuzuAI の Rakuda Benchmark などがありますが、どのリーダーボードのどういう数値を見てモデルを選べばよいかは自明ではありません。感情分析の精度が高いといいのかな・・・? ぐらいでしょう。そもそも、自分の用途に一致した評価用データセットを見つけるのは困難かもしれません。
何件かユースケース用のデータセットを用意して、追加学習することでモデルをカスタマイズして使いたいとします。例えば、「プロンプト + ユーザー ID から得られる顧客情報」と「得たいメール文」のペアを用意して学習させるといった具合です。残念ながら、現在のベンチマークはこの評価を行う際も参考になりません。理由は、学習させずに評価しているので学習能力については不明なためです。
なお、プロンプトをどのように与えるとよいのかはモデルによって異なります。下図は 日本語LLMベンチマークと自動プロンプトエンジニアリング より引用した図で、最左がオリジナルの精度、中央および右が遺伝的アルゴリズムでプロンプトを最適化したときの Dev/Test に対する精度です 。各モデル大幅に精度を伸ばしており、特に Stability AI のモデルはプロンプトをチューニングすると正答率が 50 ポイント近く伸びていることがわかります。

よく使われるモデルほどプロンプトの発明が進みアドバンテージがあるとの指摘もあります。つまり、リーダーボードの数値は「あなたが使うプロンプト」の性能については保証しないし、何件データがあれば求める制度が得られそうかについても示唆を与えないということです。
望ましい大規模言語モデルの評価
提案は 2 点です。 1) 応用確率が高いユースケースの評価シナリオの作成、 2) 少量データでの Fine tune 後性能の評価 です。
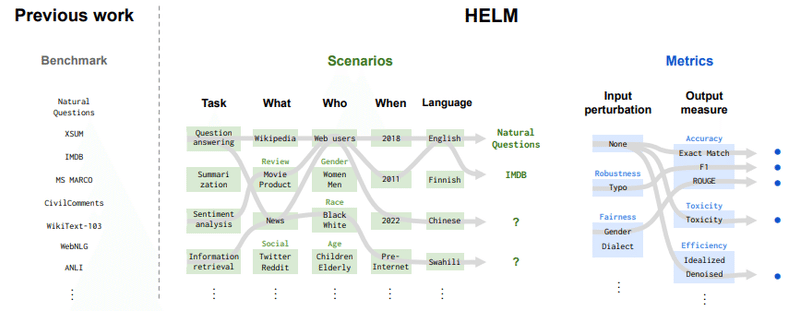
1) 応用確率が高いユースケースの評価シナリオの作成 は、 Stanford の HELM ベンチマークが参考になります。ベンチマークをデータセットのバラエティパック的に作るのではなく、目的に応じたシナリオに沿ってデータセットを編成すべきという提案です。現在英語に閉じているのですが、この日本語版 J-HELM を構築するのはどうかということです。査読のレビューで指摘されているように、 HELM のシナリオでは "Why" の観点が省略されています。そのため、「パーソナライズしたメールを送るために・・・」といった目的を設定することでよりモデルの選択者にとって利用シーンがイメージしやすいシナリオになると考えています。
特にインパクトの高い Software Engineering の領域では、Paper with code の Computer Code のセクションがベンチマーク構成の参考になると考えています。ソースコードの生成を行う Code Generation はもちろん、 Program Repair 、 Source Code Summarization 、 Log Parsing といったタスクもありこれらを目的に応じ編成したベンチマークを作成することでハイインパクトな Software Engineering 領域での活用を促すことができます ( おもったより分量が多かったので、編成案は別途まとめようと思います ) 。
2) 少量データでの Fine tune 後性能の評価は、モデルを使う側にとって重要です。100 件でいいのか、 200 件でいいのか、 1000 件でいいのかは大きな違いです。現在ベンチマークとしてよく使用される JGLUE では含まれるデータセットの件数がバラバラなので、サンプリングして評価するイメージになります。

以前執筆した記事では、 1000 件程度で最終性能の約 7 割りが得られることを示しました。検証は OpenCALM と JAQKET で行いましたが、他のモデル、他のデータセットではどうなるか調べることで「特定タスクにカスタマイズしやすいモデル」が明らかになるはずです。
おわりに
AWS では Amazon Bedrock や Amazon SageMaker JumpStart で複数の大規模言語モデルを提供しています。最近では日本語大規模言語モデルの rinna も使えるようにしました。お客様から頂く質問で私たちからも答えることが難しい問いは、「どんなモデルを選んだらいいのか」「カスタマイズするとしたら何件データを用意したらいいのか」です。これらの問いに答えられるようになるため、 AWS 自身としてもモデルの評価についての検証を行っていきたいと考えています。
余談ですが、 Software Engineering は最も生成系 AI のインパクトが高い領域の一つです。なので、もし皆さんがシステムベンダーなどから生成系 AI 活用の提案を受ける時は「御社ではどんなインパクトがあったのか教えてくれませんか ? 」という質問が効果的です。ソースコードを自動生成する Amazon CodeWhisperer でアクセンチュアが開発生産性を向上させた方法、などの事例が出てくるかどうかです。出てこなかったら一番インパクトが出しやすい領域で活用できてないのに人の活用を手伝うって何 ? という話になります。 AWS 自身も問われる点なので気が抜けないですね💦
この記事が気に入ったらサポートをしてみませんか?